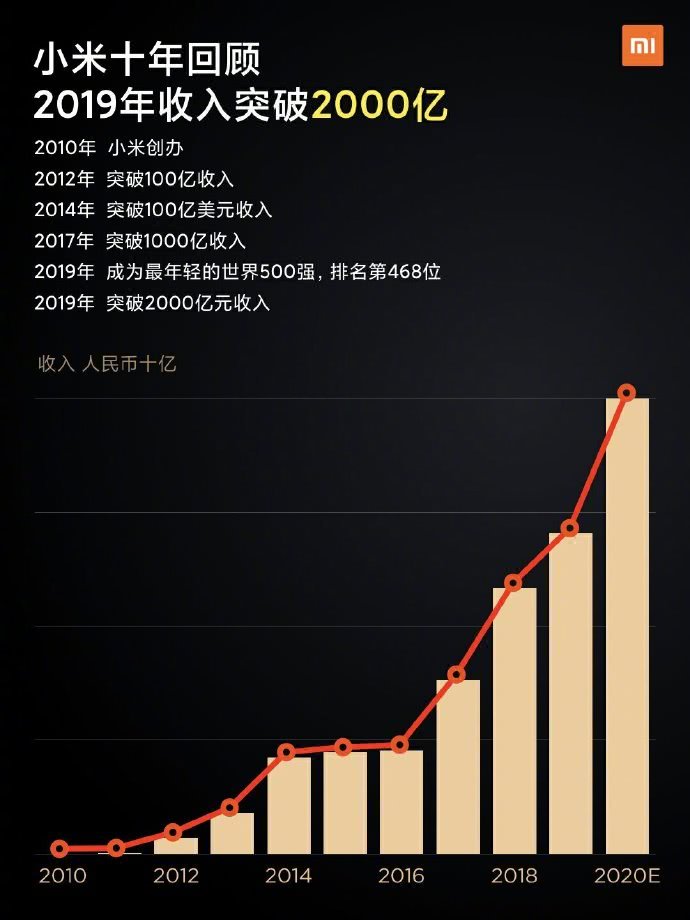
但是,當(dāng)一本書學(xué)過(guò)之后,對(duì)一般的技術(shù)和函數(shù)都有了印象,突然想要查找某個(gè)函數(shù)的實(shí)例代碼時(shí),卻感到很困難,因?yàn)橐槐緯脑创a目錄很長(zhǎng),往往有幾十甚至上百個(gè)源代碼文件,想要找到自己想要的函數(shù)實(shí)例談何容易?
所以這里就是要將所有源代碼按照目錄和文件名作為標(biāo)簽,全部合并到一處,這樣便于快速的搜索。查找,不是,那么查找下一個(gè)……于是很快便可以找到自己想要的實(shí)例,非常方便。當(dāng)然,分開(kāi)的源代碼文件依然很有用,同樣可以保留。合并之后的源代碼文件并不大,n*100KB而已,打開(kāi)和搜索都是很快速的。大家可以將同一種編程語(yǔ)言的所有實(shí)例通過(guò)這種方法全部合并為一個(gè)文件,搜索的效率就會(huì)大大提高。
注意:保存代碼之后,將源文件復(fù)制到目錄下,同一目錄下的所有目錄和其子目錄都會(huì)被搜索;你可以加上后綴限定,只獲取某種格式的文件的內(nèi)容即可;源代碼如下,請(qǐng)復(fù)制后保存:
代碼如下:
# -*- coding: utf-8 -*-
import os,sys
info = os.getcwd()
fout = open('note.tpy', 'w') # 合并內(nèi)容到該文件
def writeintofile(info):
fin = open(info)
strinfo = fin.read()
# 利用##作為標(biāo)簽的點(diǎn)綴,你也可以使用其他的
fout.write('/n##/n')
fout.write('## '+info[-30:].encode('utf-8'))
fout.write('/n##/n/n')
fout.write(strinfo)
fin.close()
for root, dirs, files in os.walk(info):
if len(dirs)==0:
for fl in files:
info = "%s/%s" % (root,fl)
if info[-2:] == 'py': # 只將后綴名為py的文件內(nèi)容合并
writeintofile(info)
fout.close()
如果你不想合并內(nèi)容,只想獲得一個(gè)文件名的清單文件,也可以。這里給你代碼。例如,有的作者就會(huì)使用這個(gè)功能為自己生成一個(gè)源代碼文件清單,很實(shí)用。
源代碼為:
代碼如下:
# -*- coding: utf-8 -*-
'''
本程序自動(dòng)搜索指定的目錄,
打印所有文件的完整文件名到指定的文件中
'''
import os,sys
export = ""
i=1
for root, dirs, files in os.walk(r'..'):
#r'.'表示當(dāng)前目錄中的所有清單
#..表示平行的其他目錄,多出很多內(nèi)容
export += "--%s--/n%s/n/n%s/n/n" % (i,root,'/n'.join(files))
i=i+1
fp = open('cdcfile-4.txt', 'w')
fp.write(export)
fp.close()