通常測試人員或公司實習人員需要處理一些txt文本內容,而此時使用Python是比較方便的語言。它不光在爬取網上資料上方便,還在NLP自然語言處理方面擁有獨到的優勢。這篇文章主要簡單的介紹使用Python處理txt漢字文字、二維列表排序和獲取list下標。希望文章對你有所幫助或提供一些見解~
一. list二維數組排序
功能:已經通過Python從維基百科中獲取了國家的國土面積和排名信息,此時需要獲取國土面積并進行排序判斷世界排名是否正確。
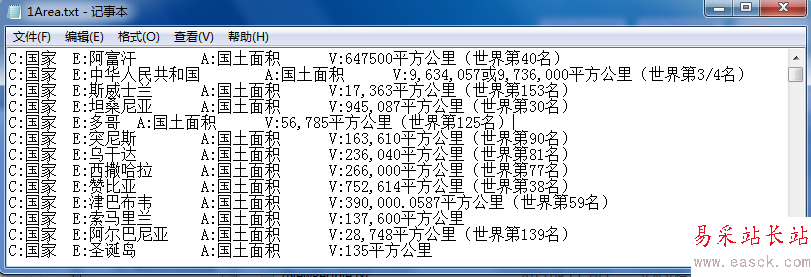
列表基礎知識
列表類型同字符串一樣也是序列式的數據類型,可以通過下標或切片操作來訪問某一個或某一塊連續的元素。它和字符串不同之處在于:字符串只能由字符組成而且不可變的(不能單獨改變它的某個值),而列表是能保留任意數目的Python對象靈活容器。
總之,列表可以包含不同類型的對象(包括用戶自定義的對象)作為元素,列表可以添加或刪除元素,也可以合并或拆分列表,包括insert、update、remove、sprt、reverse等操作。
列表排序介紹
常用列表排序方法包括使用List內建函數list.sort()或序列類型函數sorted(list)排序
#list.sort(func=None, key=None, reverse=False) list = [4, 3, 9, 1, 5, 2] print list list.sort() print list #輸出 [4, 3, 9, 1, 5, 2] [1, 2, 3, 4, 5, 9]
通過對比下面的代碼,可以發現兩種方法的區別是:list.sort()改變了原list的順序,而sorted沒有。
#sorted(list) list = ['h', 'a', 'p', 'd', 'i', 'b'] print list print sorted(list) print list #輸出 ['h', 'a', 'p', 'd', 'i', 'b'] ['a', 'b', 'd', 'h', 'i', 'p'] ['h', 'a', 'p', 'd', 'i', 'b']
二維列表排序
通過lambda表達式實現二維列表排序,并且按照第二個關鍵字進行排序。參考文章
#list.sort(func=None, key=None, reverse=False) list = [('Tom',4),('Jack',7),('Daly',9),('Mary',1),('God',5),('Yuri',3)] print list list.sort(lambda x,y:cmp(x[1],y[1])) print list #輸出 [('Tom', 4), ('Jack', 7), ('Daly', 9), ('Mary', 1), ('God', 5), ('Yuri', 3)] [('Mary', 1), ('Yuri', 3), ('Tom', 4), ('God', 5), ('Jack', 7), ('Daly', 9)] 題目中如果第一個數存儲文件中讀取的行號,第二個數存儲人口數量,此時可對第二個數進行排序。需要注意的是它們一組(1,93)是tuple元組。
#list.sort(func=None, key=None, reverse=False) list = [(1,93),(2,71),(3,89),(4,93),(5,85),(6,77)] print list list.sort(key=lambda x:x[1]) print list #輸出 [(1, 93), (2, 71), (3, 89), (4, 93), (5, 85), (6, 77)] [(2, 71), (6, 77), (5, 85), (3, 89), (1, 93), (4, 93)]
lambada表達式
在上述代碼中,如果還不知道lambada是什么鬼東西的話?那我就來幫你回顧了。
新聞熱點





疑難解答