本篇文章主要通過一個簡單的例子來實(shí)現(xiàn)神經(jīng)網(wǎng)絡(luò)。訓(xùn)練數(shù)據(jù)是隨機(jī)產(chǎn)生的模擬數(shù)據(jù)集,解決二分類問題。
下面我們首先說一下,訓(xùn)練神經(jīng)網(wǎng)絡(luò)的一般過程:
1.定義神經(jīng)網(wǎng)絡(luò)的結(jié)構(gòu)和前向傳播的輸出結(jié)果
2.定義損失函數(shù)以及反向傳播優(yōu)化的算法
3.生成會話(Session)并且在訓(xùn)練數(shù)據(jù)上反復(fù)運(yùn)行反向傳播優(yōu)化算法
要記住的一點(diǎn)是,無論神經(jīng)網(wǎng)絡(luò)的結(jié)構(gòu)如何變化,以上三個步驟是不會改變的。
完整代碼如下:
import tensorflow as tf #導(dǎo)入TensorFlow工具包并簡稱為tf from numpy.random import RandomState #導(dǎo)入numpy工具包,生成模擬數(shù)據(jù)集 batch_size = 8 #定義訓(xùn)練數(shù)據(jù)batch的大小 w1 = tf.Variable(tf.random_normal([2,3],stddev=1,seed=1)) w2 = tf.Variable(tf.random_normal([3,1],stddev=1,seed=1)) #分別定義一二層和二三層之間的網(wǎng)絡(luò)參數(shù),標(biāo)準(zhǔn)差為1,隨機(jī)產(chǎn)生的數(shù)保持一致 x = tf.placeholder(tf.float32,shape=(None,2),name='x-input') y_ = tf.placeholder(tf.float32,shape=(None,1),name='y-input') #輸入為兩個維度,即兩個特征,輸出為一個標(biāo)簽,聲明數(shù)據(jù)類型float32,None即一個batch大小 #y_是真實(shí)的標(biāo)簽 a = tf.matmul(x,w1) y = tf.matmul(a,w2) #定義神經(jīng)網(wǎng)絡(luò)前向傳播過程 cross_entropy = -tf.reduce_mean(y_ * tf.log(tf.clip_by_value(y,1e-10,1.0))) train_step = tf.train.AdamOptimizer(0.001).minimize(cross_entropy) #定義損失函數(shù)和反向傳播算法 rdm = RandomState(1) dataset_size = 128 #產(chǎn)生128組數(shù)據(jù) X = rdm.rand(dataset_size,2) Y = [[int(x1+x2 < 1)] for (x1,x2) in X] #將所有x1+x2<1的樣本視為正樣本,表示為1;其余為0 #創(chuàng)建會話來運(yùn)行TensorFlow程序 with tf.Session() as sess: init_op = tf.global_variables_initializer() #初始化變量 sess.run(init_op) print(sess.run(w1)) print(sess.run(w2)) #打印出訓(xùn)練網(wǎng)絡(luò)之前網(wǎng)絡(luò)參數(shù)的值 STEPS = 5000 #設(shè)置訓(xùn)練的輪數(shù) for i in range(STEPS): start = (i * batch_size) % dataset_size end = min(start+batch_size,dataset_size) #每次選取batch_size個樣本進(jìn)行訓(xùn)練 sess.run(train_step,feed_dict={x:X[start:end],y_:Y[start:end]}) #通過選取的樣本訓(xùn)練神經(jīng)網(wǎng)絡(luò)并更新參數(shù) if i%1000 == 0: total_cross_entropy = sess.run(cross_entropy,feed_dict={x:X,y_:Y}) print("After %d training step(s),cross entropy on all data is %g" % (i,total_cross_entropy)) #每隔一段時間計算在所有數(shù)據(jù)上的交叉熵并輸出,隨著訓(xùn)練的進(jìn)行,交叉熵逐漸變小 print(sess.run(w1)) print(sess.run(w2)) #打印出訓(xùn)練之后神經(jīng)網(wǎng)絡(luò)參數(shù)的值 運(yùn)行結(jié)果如下:
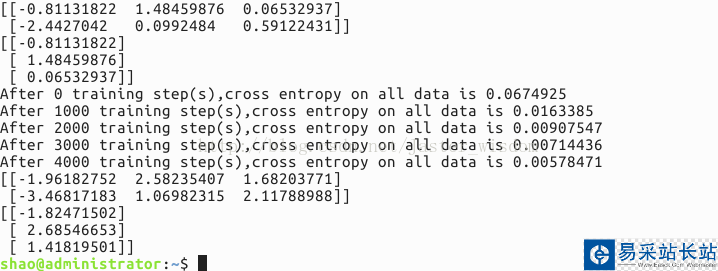
結(jié)果說明:
首先是打印出訓(xùn)練之前的網(wǎng)絡(luò)參數(shù),也就是隨機(jī)產(chǎn)生的參數(shù)值,然后將訓(xùn)練過程中每隔1000次的交叉熵輸出,發(fā)現(xiàn)交叉熵在逐漸減小,說明分類的性能在變好。最后是訓(xùn)練網(wǎng)絡(luò)結(jié)束后網(wǎng)絡(luò)的參數(shù)。
新聞熱點(diǎn)





疑難解答
圖片精選