作為酷愛編程的老程序員,實在按耐不下這個沖動,Python真的是太火了,不斷撩撥我的心。

我是對Python存有戒備之心的,想當年我基于Drupal做的系統,使用php語言,當語言升級了,推翻了老版本很多東西,不得不花費很多時間和精力去移植和升級,至今還有一些隱藏在某處的代碼埋著雷。我估計Python也避免不了這個問題(其實這種聲音已經不少,比如Python 3 正在毀滅 Python)。 但是,我還是啟動了這個Python即時網絡爬蟲項目。我用C++、Java和Javascript編寫爬蟲相關程序超過10年,要追求高性能,非C++莫屬,同時有完善的標準體系,讓你和你的系統十分自信,只要充分測試,就能按照預期的方式運行。在GooSeeker項目中,我們不斷向一個方向努力——“收割數據”,而且讓廣大用戶(不僅是專業的數據采集用戶)都能體驗到收割互聯網數據的快感。“收割”的一個重要含義就是大批量。現在,我要啟動“即時網絡爬蟲”,目的是要補充“收割”沒有覆蓋的場景,我看到的是:
在系統層面:“即時”代表快速部署數據應用系統 在數據流層面:“即時”代表采集數據到數據使用是即時的,單個數據對象可以獨自全流程處理,不用等待一批存入數據庫,然后從數據庫中拿出來用 “即時”另一個含義就是網絡爬蟲是一個嵌入模塊,跟整個信息處理系統集成在一起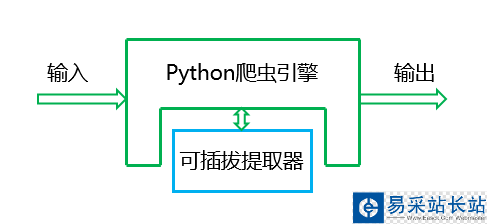
一眾程序員都在玩Python網絡爬蟲,我擬定了一個計劃:建立一個模塊化更強的軟件部件,專門解決最耗費精力的內容提取問題(有人總結說大數據和數據分析整個鏈條上,數據準備占了80%工作量,我們不妨延展一下,網絡數據抓取的工作量有80%是在為各種網站的各種數據結構編寫抓取規則)。
我把他想象成一個小機器(見上圖),輸入的是原始網頁,輸出的是提取出來的結構化的內容,這個小機器還有一個可替換部件:將輸入轉化成輸出結構的一個指令塊,我們成為“提取器”,讓大家不再為調試正則表達式或者XPath而苦惱。
這是一個開放的項目,兩年前啟動了一個手機上的即時網絡爬蟲項目,因為是給某商業集團開發的,所以不便開放,同樣的思想和方法將開放到這個項目中,而且用當前最熱的python來做,希望大家能共同參與。在執行過程中,我們會開放所有資料和成果、已經遇到的坑。
近期做的實驗是
python使用xslt提取網頁數據
新聞熱點





疑難解答