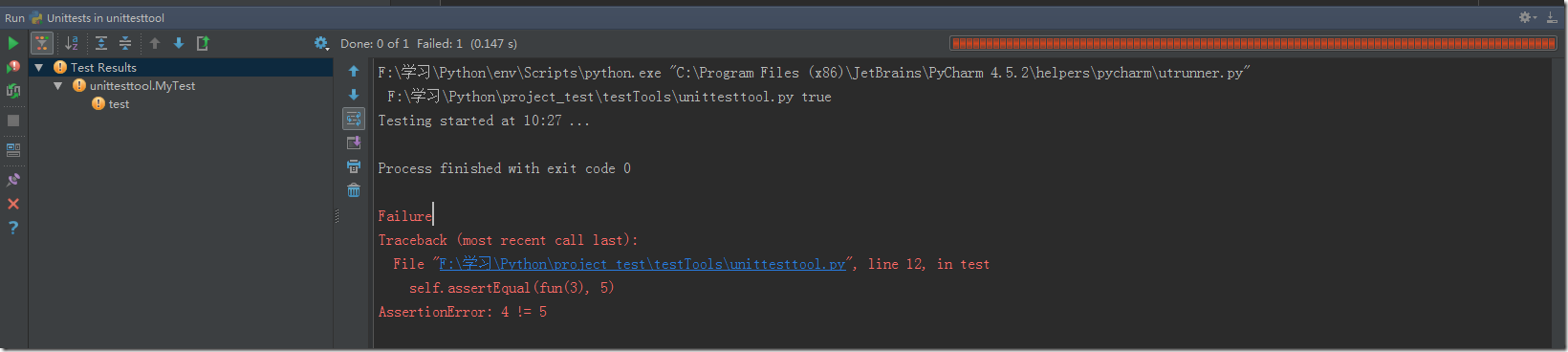
獲得驗證碼圖片光學字符識別驗證碼用API處理復雜驗證碼1 9kw打碼平臺11 提交驗證碼12 請求已提交驗證碼結果12與注冊功能集成
驗證碼(CAPTCHA)全稱為全自動區分計算機和人類的公開圖靈測試(Completely Automated Public Turing test to tell Computersand Humans Apart)。從其全稱可以看出,驗證碼用于測試用戶是真實的人類還是計算機機器人。
每次加載注冊網頁都會顯示不同的驗證驗圖像,為了了解表單需要哪些參數,我們可以復用上一章編寫的parse_form()函數。
>>> import cookielib,urllib2,pPRint>>> import form>>> REGISTER_URL = 'http://127.0.0.1:8000/places/default/user/register'>>> cj=cookielib.CookieJar()>>> opener=urllib2.build_opener(urllib2.HTTPCookieProcessor(cj))>>> html=opener.open(REGISTER_URL).read()>>> form=form.parse_form(html)>>> pprint.pprint(form){'_formkey': 'a67cbc84-f291-4ecd-9c2c-93937faca2e2', '_formname': 'register', '_next': '/places/default/index', 'email': '', 'first_name': '', 'last_name': '', 'passWord': '', 'password_two': '', 'recaptcha_response_field': None}>>>上面recaptcha_response_field是存儲驗證碼的值,其值可以用Pillow從驗證碼圖像獲取出來。先安裝pip install Pillow,其它安裝Pillow的方法可以參考http://pillow.readthedocs.org/installation.html 。Pillow提價了一個便捷的Image類,其中包含了很多用于處理驗證碼圖像的高級方法。下面的函數使用注冊頁的HTML作為輸入參數,返回包含驗證碼圖像的Image對象。
在本例中,這是一張進行了Base64編碼的PNG圖像,這種格式會使用ASCII編碼表示二進制數據。我們可以通過在第一個逗號處分割的方法移除該前綴。然后,使用Base64解碼圖像數據,回到最初的二進制格式。要想加載圖像,PIL需要一個類似文件的接口,所以在傳給Image類之前,我們以使用了BytesIO對這個二進制數據進行了封裝。 完整代碼:
# -*- coding: utf-8 -*-form.pyimport urllibimport urllib2import cookielibfrom io import BytesIOimport lxml.htmlfrom PIL import ImageREGISTER_URL = 'http://127.0.0.1:8000/places/default/user/register'#REGISTER_URL = 'http://example.webscraping.com/user/register'def extract_image(html): tree = lxml.html.fromstring(html) img_data = tree.cssselect('div#recaptcha img')[0].get('src') # remove data:image/png;base64, header img_data = img_data.partition(',')[-1] #open('test_.png', 'wb').write(data.decode('base64')) binary_img_data = img_data.decode('base64') file_like = BytesIO(binary_img_data) img = Image.open(file_like) #img.save('test.png') return imgdef parse_form(html): """extract all input properties from the form """ tree = lxml.html.fromstring(html) data = {} for e in tree.cssselect('form input'): if e.get('name'): data[e.get('name')] = e.get('value') return datadef register(first_name, last_name, email, password, captcha_fn): cj = cookielib.CookieJar() opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cj)) html = opener.open(REGISTER_URL).read() form = parse_form(html) form['first_name'] = first_name form['last_name'] = last_name form['email'] = email form['password'] = form['password_two'] = password img = extract_image(html)# captcha = captcha_fn(img)# form['recaptcha_response_field'] = captcha encoded_data = urllib.urlencode(form) request = urllib2.Request(REGISTER_URL, encoded_data) response = opener.open(request) success = '/user/register' not in response.geturl() #success = '/places/default/user/register' not in response.geturl() return success光學字符識別(Optical Character Recognition, OCR)用于圖像中抽取文本。本節中,我們將使用開源的Tesseract OCR引擎,該引擎最初由惠普公司開發的,目前由Google主導。Tesseract的安裝說明可以從http://code.google.com/p/tesseract-ocr/wiki/ReadMe 獲取。然后可以使用pip安裝其Python封裝版本pytesseractpip install pytesseract。 下面我們用光學字符識別圖像驗證碼:
如果直接把驗證碼原始圖像傳給pytesseract,一般不能解析出來。這是因為Tesseract是抽取更加典型的文本,比如背景統一的書頁。下面我們進行去除背景噪音,只保留文本部分。驗證碼文本一般都是黑色的,背景則會更加明亮,所以我們可以通過檢查是否為黑色將文本分離出來,該處理過程又被稱為閾值化。
>>> >>> img.save('2captcha_1original.png')>>> gray=img.convert('L')>>> gray.save('2captcha_2gray.png')>>> bw=gray.point(lambda x:0 if x<1 else 255,'1')>>> bw.save('2captcha_3thresholded.png')>>>這里只有閾值小于1的像素(全黑)都會保留下來,分別得到三張圖像:原始驗證碼圖像、轉換后的灰度圖和閾值化處理后的黑白圖像。最后我們將閾值化處理后黑白圖像再進行Tesseract處理,驗證碼中的文字已經被成功抽取出來了。
>>> pytesseract.image_to_string(bw)'language'>>> >>> import Image,pytesseract>>> img=Image.open('2captcha_3thresholded.png')>>> pytesseract.image_to_string(img)'language'>>>我們通過示例樣本測試,100張驗證碼能正確識別出90張。
>>> import ocr>>> ocr.test_samples()Accuracy: 90/100>>>下面是注冊賬號完整代碼:
# -*- coding: utf-8 -*-import csvimport stringfrom PIL import Imageimport pytesseractfrom form import registerdef main(): print register('Wu1', 'Being1', 'Wu_Being001@QQ.com', 'example', ocr)def ocr(img): # threshold the image to ignore background and keep text gray = img.convert('L') #gray.save('captcha_greyscale.png') bw = gray.point(lambda x: 0 if x < 1 else 255, '1') #bw.save('captcha_threshold.png') word = pytesseract.image_to_string(bw) ascii_word = ''.join(c for c in word if c in string.letters).lower() return ascii_wordif __name__ == '__main__': main()我們可以進一步改善OCR性能: - 實驗不同閾值 - 腐蝕閾值文本,突出字符形狀 - 調整圖像大小 - 根據驗證碼字體訓練ORC工具 - 限制結果為字典單詞
為了處理更加復雜的圖像,我們將使用驗證處理服務,也叫打碼平臺。
提交驗證碼參數: - URL: https://www.9kw.eu/index.cgi(POST) - action:POST必須設為:’usercaptchaupload’ - apikey:個人的API key - file-upload-01:需要處理的圖像(文件、url 或字符串) - base64:如果輸入的是Base64編碼,則設為“1” - maxtimeout:等待處理的最長時間(60~3999) - selfsolve:如果自己處理該驗證碼,則設為“1”
返回值: - 該驗證碼的ID
API_URL: https://www.9kw.eu/index.cgi def send(self, img_data): """Send CAPTCHA for solving """ print 'Submitting CAPTCHA' data = { 'action': 'usercaptchaupload', 'apikey': self.api_key, 'file-upload-01': img_data.encode('base64'), 'base64': '1', 'selfsolve': '1', 'maxtimeout': str(self.timeout) } encoded_data = urllib.urlencode(data) request = urllib2.Request(API_URL, encoded_data) response = urllib2.urlopen(request) return response.read()API文檔地址https://www.9kw.eu/api.html#apisubmit-tab
請求結果的參數: - URL: https://www.9kw.eu/index.cgi(GET) - action:GET必須設為:’usercaptchacorrectdata’ - apikey:個人的API key - id:要檢查的驗證碼ID - info:若設為“1”,沒有得到結果時返回“NO DATA”(默認返回空)
返回值: - 要處理的驗證碼文本或錯誤碼
錯誤碼: - 0001:API key不存在 - 0002:沒有找到API key - 0003:沒有找到激活的API key …… - 0031:賬號被系統禁用24小時 - 0032:賬號沒有足夠的權限 - 0033:需要升級插件
def get(self, captcha_id): """Get result of solved CAPTCHA """ data = { 'action': 'usercaptchacorrectdata', 'id': captcha_id, 'apikey': self.api_key, 'info': '1' } encoded_data = urllib.urlencode(data) response = urllib2.urlopen(self.url + '?' + encoded_data) return response.read()Wu_Being 博客聲明:本人博客歡迎轉載,請標明博客原文和原鏈接!謝謝! 【Python爬蟲系列】《【Python爬蟲7】驗證碼處理》http://blog.csdn.net/u014134180/article/details/55508229 Python爬蟲系列的GitHub代碼文件:https://github.com/1040003585/WebScrapingWithPython
新聞熱點






疑難解答