安裝Scrapy新建項(xiàng)目1定義模型2創(chuàng)建爬蟲3優(yōu)化設(shè)置4測(cè)試爬蟲5使用shell命令提取數(shù)據(jù)6提取數(shù)據(jù)保存到文件中7中斷和恢復(fù)爬蟲使用Portia編寫可視化爬蟲1安裝2標(biāo)注3優(yōu)化爬蟲4檢查結(jié)果使用Scrapely實(shí)現(xiàn)自動(dòng)化提取
用pip命令安裝Scrapy:pip install Scrapy
本篇會(huì)用到下面幾個(gè)命令: - startproject:創(chuàng)建一人新項(xiàng)目 - genspider:根據(jù)模板生成一個(gè)新爬蟲 - crawl:執(zhí)行爬蟲 - shell:?jiǎn)?dòng)交互式提取控制臺(tái)
文檔:http://doc.scrapy.org/latest/topics/commands.html
輸入scrapy startproject <project_name>新建項(xiàng)目,這里使用example_wu為項(xiàng)目名。
下面是新建項(xiàng)目的默認(rèn)目錄結(jié)構(gòu):
scrapy.cfgexample_wu/ __init__.py items.py middlewares.py pipelines.py setting.py spiders/ __init__.py下面是重要的幾個(gè)文件說(shuō)明: - scrapy.cfg:設(shè)置項(xiàng)目配置(不用修改) - items.py:定義待提取域的模型 - pipelines.py:處理要提取的域(不用修改) - setting.py:定義一些設(shè)置,如用戶代理、提取延時(shí)等 - spiders/:該目錄存儲(chǔ)實(shí)際的爬蟲代碼
example_wu/items.py默認(rèn)代碼如下:
ExampleWuItem類是一個(gè)模板,需要將其中的內(nèi)容替換為爬蟲運(yùn)行時(shí)想要存儲(chǔ)的待提取的國(guó)家信息,我們這里設(shè)置只提取國(guó)家名稱和人口數(shù)量,把默認(rèn)代碼修改為:
現(xiàn)在我們開(kāi)始編寫真正的爬蟲代碼,又稱為spider,通過(guò)genspider命令,傳入爬蟲名、域名和可選模板參數(shù): scrapy genspider country 127.0.0.1:8000/places --template=crawl
這里使用內(nèi)置crawl模板,可以生成更加接近我們想要的國(guó)家爬蟲初始版本。運(yùn)行g(shù)enspider命令之后,將會(huì)生成代碼example_wu/spiders/country.py。
該類的屬性名: - name:定義爬蟲的名稱 - allowed_domains:定義可以提取的域名列表。如果沒(méi)有則表示可以提取任何域名!!!!!! - start_urls:定義爬蟲起始的URL列表。意思為可用的URL!!!!!! - rules:定義正則表達(dá)式集合,用于告知爬蟲需要跟蹤哪些鏈接。還有一個(gè)callback函數(shù),用于解析下載得到的響應(yīng),而parse_urls()示例方法給我們提供了一個(gè)從響應(yīng)中獲取數(shù)據(jù)的例子。
文檔:http://doc.scrapy.org/en/latest/topics/spiders.html
默認(rèn)情況下,Scrapy對(duì)同一個(gè)域名允許最多16個(gè)并發(fā)下載,并且再次下載之間沒(méi)有延時(shí),這樣爬蟲容易被服務(wù)器檢測(cè)到并被封禁,所以要在example_wu/settings.py添加幾行代碼:
這里的延時(shí)不是精確的,精確的延時(shí)有時(shí)也可能被服務(wù)器檢測(cè)到被封禁,而Scrapy實(shí)際在兩次請(qǐng)求的延時(shí)添加隨機(jī)的偏移量。文檔:http://doc.scrapy.org/en/latest/topics/settings.html
使用crawl運(yùn)行爬蟲,并附上爬蟲名稱。
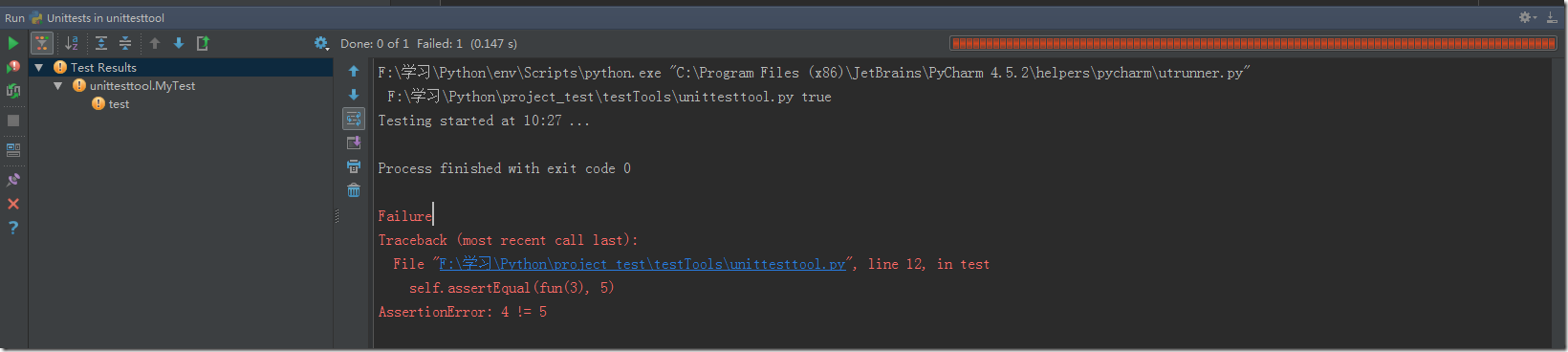
發(fā)現(xiàn)終端日志沒(méi)有輸出錯(cuò)誤信息,命令的參數(shù)LOG_LEVEL=ERROR等同于在settings.py加一行LOG_LEVEL='ERROR',默認(rèn)是在終端顯示所有日志信息。
上面我們添加了兩條規(guī)則。第一條規(guī)則爬取索引頁(yè)并跟蹤其中的鏈接(遞歸爬取鏈接,默認(rèn)是True),而第二條規(guī)則爬取國(guó)家頁(yè)面并將下載響應(yīng)傳給callback函數(shù)用于提取數(shù)據(jù)。
...2017-01-30 00:12:47 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://127.0.0.1:8000/places/> (referer: None)2017-01-30 00:12:52 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://127.0.0.1:8000/places/default/view/Afghanistan-1> (referer: http://127.0.0.1:8000/places/)2017-01-30 00:12:57 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://127.0.0.1:8000/places/default/index/1> (referer: http://127.0.0.1:8000/places/)2017-01-30 00:12:58 [scrapy.dupefilters] DEBUG: Filtered duplicate request: <GET http://127.0.0.1:8000/places/default/index/1> - no more duplicates will be shown (see DUPEFILTER_DEBUG to show all duplicates)2017-01-30 00:13:03 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://127.0.0.1:8000/places/default/view/Antigua-and-Barbuda-10> (referer: http://127.0.0.1:8000/places/)......2017-01-30 00:14:11 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://127.0.0.1:8000/places/default/user/login?_next=%2Fplaces%2Fdefault%2Findex%2F1> (referer: http://127.0.0.1:8000/places/default/index/1)2017-01-30 00:14:17 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://127.0.0.1:8000/places/default/user/register?_next=%2Fplaces%2Fdefault%2Findex%2F1> (referer: http://127.0.0.1:8000/places/default/index/1)......我們發(fā)現(xiàn)已經(jīng)自動(dòng)過(guò)濾了重復(fù)鏈接,但結(jié)果有多余的登錄頁(yè)和注冊(cè)頁(yè),我們可以用正則表達(dá)式過(guò)濾。
rules = ( Rule(LinkExtractor(allow='/index/', deny='/user/'), follow=True), #False Rule(LinkExtractor(allow='/view/', deny='/user/'), callback='parse_item'),)使用該類的文檔:http://doc.scrapy.org/en/latest/topics/linkextractors.html
scrapy提供了shell命令可以下載URL并在python解釋器中給出結(jié)果狀態(tài)。
wu_being@ubuntukylin64:~/GitHub/WebScrapingWithPython/8.Scrapy爬蟲框架/example_wu$ scrapy shell http://127.0.0.1:8000/places/default/view/47...2017-01-30 11:24:21 [scrapy.core.engine] INFO: Spider opened2017-01-30 11:24:21 [scrapy.core.engine] DEBUG: Crawled (400) <GET http://127.0.0.1:8000/robots.txt> (referer: None)2017-01-30 11:24:22 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://127.0.0.1:8000/places/default/view/47> (referer: None)[s] Available Scrapy objects:[s] scrapy scrapy module (contains scrapy.Request, scrapy.Selector, etc)[s] crawler <scrapy.crawler.Crawler object at 0x7fd8e6d5cbd0>[s] item {}[s] request <GET http://127.0.0.1:8000/places/default/view/47>[s] response <200 http://127.0.0.1:8000/places/default/view/47>[s] settings <scrapy.settings.Settings object at 0x7fd8e6d5c5d0>[s] spider <DefaultSpider 'default' at 0x7fd8e5b24c50>[s] Useful shortcuts:[s] fetch(url[, redirect=True]) Fetch URL and update local objects (by default, redirects are followed)[s] fetch(req) Fetch a scrapy.Request and update local objects [s] shelp() Shell help (print this help)[s] view(response) View response in a browser>>>下面我們來(lái)測(cè)試一下。
>>> >>> response<200 http://127.0.0.1:8000/places/default/view/47>>>> response.url'http://127.0.0.1:8000/places/default/view/47'>>> response.status200>>> item{}>>> >>>scrapy可以使用lxml提取數(shù)據(jù),這里用CSS選擇器。用extract()提取數(shù)據(jù)。
下面是該爬蟲的完整代碼。
# -*- coding: utf-8 -*-import scrapyfrom scrapy.linkextractors import LinkExtractorfrom scrapy.spiders import CrawlSpider, Rulefrom example_wu.items import ExampleWuItem ###wuclass CountrySpider(CrawlSpider): name = 'country' #allowed_domains = ['127.0.0.1:8000/places']####domains!!!!這個(gè)不是域名 start_urls = ['http://127.0.0.1:8000/places/'] rules = ( Rule(LinkExtractor(allow='/index/', deny='/user/'), follow=True), #False Rule(LinkExtractor(allow='/view/', deny='/user/'), callback='parse_item'), ) def parse_item(self, response): item = ExampleWuItem() ###wu item['name'] = response.css('tr#places_country__row td.w2p_fw::text').extract() item['population'] = response.css('tr#places_population__row td.w2p_fw::text').extract() return item要想保存結(jié)果,我們可以在parse_item()方法中添加保存提取數(shù)據(jù)的代碼,或是定義管道。不過(guò)scrapy提供了一個(gè)方便的--output選項(xiàng),用于自動(dòng)保存提取的數(shù)據(jù)到CSV、JSON和XML文件中。
提取過(guò)程最后還輸出一些統(tǒng)計(jì)信息。我們查看輸出文件countries.csv的信息,結(jié)果和預(yù)期一樣。
name,populationAndorra,84000American Samoa,57881Algeria,34586184Albania,2986952Aland Islands,26711Afghanistan,29121286Antigua and Barbuda,86754Antarctica,0Anguilla,13254... ...我們只需要定義用于保存爬蟲當(dāng)前狀態(tài)目錄的JOBDIR設(shè)置即可。
wu_being@ubuntukylin64:~/GitHub/WebScrapingWithPython/8.Scrapy爬蟲框架/example_wu$ scrapy crawl country -s LOG_LEVEL=DEBUG -s JOBDIR=2.7crawls/country...^C2017-01-30 13:31:27 [scrapy.crawler] INFO: Received SIGINT, shutting down gracefully. Send again to force 2017-01-30 13:33:13 [scrapy.core.scraper] DEBUG: Scraped from <200 http://127.0.0.1:8000/places/default/view/Albania-3>{'name': [u'Albania'], 'population': [u'2986952']}2017-01-30 13:33:15 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://127.0.0.1:8000/places/default/view/Aland-Islands-2> (referer: http://127.0.0.1:8000/places/)2017-01-30 13:33:16 [scrapy.core.scraper] DEBUG: Scraped from <200 http://127.0.0.1:8000/places/default/view/Aland-Islands-2>{'name': [u'Aland Islands'], 'population': [u'26711']}...我們通過(guò)按Ctrl+C發(fā)送終止信號(hào),然后等待爬蟲再下載幾個(gè)條目后自動(dòng)終止,注意不能再按一次Ctrl+C強(qiáng)行終止,否則爬蟲保存狀態(tài)不成功。 我們運(yùn)行同樣的命令恢復(fù)爬蟲運(yùn)行。
wu_being@ubuntukylin64:~/GitHub/WebScrapingWithPython/8.Scrapy爬蟲框架/example_wu $wu_being@ubuntukylin64:~/GitHub/WebScrapingWithPython/8.Scrapy爬蟲框架/example_wu$ scrapy crawl country -s LOG_LEVEL=DEBUG -s JOBDIR=2.7crawls/country...2017-01-30 13:33:21 [scrapy.core.engine] DEBUG: Crawled (400) <GET http://127.0.0.1:8000/robots.txt> (referer: None)2017-01-30 13:33:23 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://127.0.0.1:8000/places/default/view/Barbados-20> (referer: http://127.0.0.1:8000/places/default/index/1)2017-01-30 13:33:23 [scrapy.core.scraper] DEBUG: Scraped from <200 http://127.0.0.1:8000/places/default/view/Barbados-20>{'name': [u'Barbados'], 'population': [u'285653']}2017-01-30 13:33:25 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://127.0.0.1:8000/places/default/view/Bangladesh-19> (referer: http://127.0.0.1:8000/places/default/index/1)2017-01-30 13:33:25 [scrapy.core.scraper] DEBUG: Scraped from <200 http://127.0.0.1:8000/places/default/view/Bangladesh-19>{'name': [u'Bangladesh'], 'population': [u'156118464']}...^C2017-01-30 13:33:43 [scrapy.crawler] INFO: Received SIGINT, shutting down gracefully. Send again to force 2017-01-30 13:33:43 [scrapy.core.engine] INFO: Closing spider (shutdown)^C2017-01-30 13:33:44 [scrapy.crawler] INFO: Received SIGINT twice, forcing unclean shutdownwu_being@ubuntukylin64:~/GitHub/WebScrapingWithPython/8.Scrapy爬蟲框架/example_wu$恢復(fù)時(shí)注意cookie過(guò)期問(wèn)題。文檔:http://doc.scrapy.org/en/latest/topics/jobs.html
Portia是一款基于scrapy開(kāi)發(fā)的開(kāi)源工具,該工具可以通過(guò)點(diǎn)擊要提取的網(wǎng)頁(yè)部分來(lái)創(chuàng)建爬蟲,這樣就比手式創(chuàng)建CSS選擇器的方式更加方便。文檔:https://github.com/scrapinghub/portia#running-portia
先使用virtualenv創(chuàng)建一個(gè)虛擬python環(huán)境,環(huán)境名為portia_examle。 pip install virtualenv
在virtualenv中安裝Portia及依賴。
(portia_examle) wu_being@ubuntukylin64:~/GitHub/WebScrapingWithPython/portia_examle$ git clone https://github.com/scrapinghub/portiacd portiapip install -r requirements.txtpip install -e ./slybotcd slydtwistd -n slyd如果安裝成功,在瀏覽器中訪問(wèn)到Portia工具h(yuǎn)ttp://localhost:9001/static/main.html
new_project,而爬蟲名被設(shè)為待爬取域名127.0.0.1:8000/places/,這兩項(xiàng)都通過(guò)單擊相應(yīng)標(biāo)簽進(jìn)行修改。單擊Annotate this page按鈕,然后單擊國(guó)家人口數(shù)量。單擊+field按鈕創(chuàng)建一個(gè)名為population的新域,然后單擊Done保存。其他的域也是相同操作。完成標(biāo)注后,單擊頂部的藍(lán)色按鈕Continue Browsing。標(biāo)注完成后,Portia會(huì)生成一個(gè)scrapy項(xiàng)目,并將產(chǎn)生的文件保存到data/projects目錄中,要運(yùn)行爬蟲,只需執(zhí)行portiacrawl命令,并帶上項(xiàng)目名和爬蟲名。
(portia_examle) wu_being@ubuntukylin64:~/GitHub/WebScrapingWithPython/portia_examle$ portiacrawl portia/slyd/data/projects/new_project 如果爬蟲默認(rèn)設(shè)置運(yùn)行太快就遇到服務(wù)器錯(cuò)誤portiacrawl portia/slyd/data/projects/new_project 127.0.0.1:8000/places/ -s DOWNLOAD_DELAY = 2 -s CONCURRENT_REQUESTS_PER_DOMAIN = 1配置右邊欄面板中的Crawling選項(xiàng)卡中,可以添加/index/和/view/為爬蟲跟蹤模式,將/user/為排除模式,并勾選Overlay blocked links復(fù)選框。
Portia是一個(gè)非常方便的與Scrapy配合的工具。對(duì)于簡(jiǎn)單的網(wǎng)站,使用Portia開(kāi)發(fā)爬蟲通常速度更快。而對(duì)于復(fù)雜的網(wǎng)站(比如依賴javaScript的界面),則可以選擇使用Python直接開(kāi)發(fā)Scrapy爬蟲。
Portia使用了Scrapely庫(kù)來(lái)訓(xùn)練數(shù)據(jù)建立從網(wǎng)頁(yè)中提取哪些內(nèi)容的模型,并在相同結(jié)構(gòu)的其他網(wǎng)頁(yè)應(yīng)用該模型。 https://github.com/scrapy/scrapely
(portia_examle) wu_being@ubuntukylin64:~/GitHub/WebScrapingWithPython/portia_examle$ pythonPython 2.7.12 (default, Nov 19 2016, 06:48:10) [GCC 5.4.0 20160609] on linux2Type "help", "copyright", "credits" or "license" for more information.>>> from scrapely import Scraper>>> s=Scraper()>>> train_url='http://127.0.0.1:8000/places/default/view/47'>>> s.train(train_url,{'name':'China','population':'1330044000'})>>> test_url='http://127.0.0.1:8000/places/default/view/239'>>> s.scrape(test_url)[{u'name':[u'United Kingdom'],u'population':[u'62,348,447']}]Wu_Being 博客聲明:本人博客歡迎轉(zhuǎn)載,請(qǐng)標(biāo)明博客原文和原鏈接!謝謝! 【Python爬蟲系列】《【Python爬蟲8】Scrapy 爬蟲框架》http://blog.csdn.net/u014134180/article/details/55508259 Python爬蟲系列的GitHub代碼文件:https://github.com/1040003585/WebScrapingWithPython
新聞熱點(diǎn)






疑難解答
網(wǎng)友關(guān)注