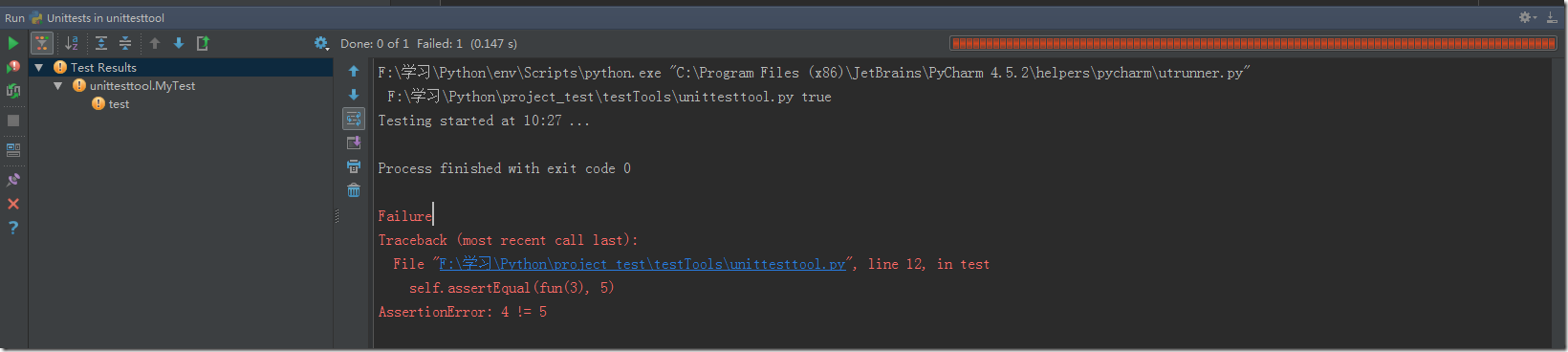
新手,以下是爬取百度貼吧制定帖子的圖片腳本,因?yàn)槟_本主要是解析html代碼,因此一旦百度修改頁(yè)面前端代碼,那么腳本會(huì)失效,權(quán)當(dāng)爬蟲(chóng)入門(mén)練習(xí)吧,后續(xù)還會(huì)嘗試更多的爬蟲(chóng)。
# coding=utf-8# !/usr/bin/env pythonimport urllib, string, osfrom bs4 import BeautifulSoupdef getHtml(url): page = urllib.urlopen(url) html = page.read() return htmldef getImg(): imgPath = 'F:/craw_tieba/' if not os.path.exists(imgPath): os.makedirs(imgPath) baseUrl = 'http://tieba.baidu.com/p/4657665666' imgList = [] for pg in range(1, 114): url = baseUrl + '?pn=' + str(pg)
新聞熱點(diǎn)






疑難解答
網(wǎng)友關(guān)注