pivot和unpivot關系運算符是sql server 2005提供的新增功能,因此,對升級到sql server 2005的數據庫使用pivot和unpivot時,數據庫的兼容級別必須設置為90(可以使用sp_dbcmptlevel存儲過程設置兼容級別)。
在查詢的from子句中使用pivot和unpivot,可以對一個輸入表值表達式執行某種操作,以獲得另一種形式的表。pivot運算符將輸入表的行旋轉為列,并能同時對行執行聚合運算。而unpivot運算符則執行與pivot運算符相反的操作,它將輸入表的列旋轉為行。
在from子句中使用pivot和unpivot關系運算符時的語法格式如下:
[ from { <table_source> } [ ,...n ] ]
<table_source> ::= {
table_or_view_name [ [ as ] table_alias ]
<pivoted_table> | <unpivoted_table>
}
<pivoted_table> ::=table_source pivot <pivot_clause> table_alias
<pivot_clause> ::=( aggregate_function ( value_column )
for pivot_column
in ( <column_list> )
)
<unpivoted_table> ::=table_source unpivot <unpivot_clause> table_alias
<unpivot_clause> ::=( value_column for pivot_column in ( <column_list> ) )
<column_list> ::= column_name [ , ... ] table_source pivot <pivot_clause>
指定對table_source表中的pivot_column列進行透視。table_source可以是一個表、表表達式或子查詢。
aggregate_function
系統或用戶定義的聚合函數。注意:不允許使用count(*)系統聚合函數。
value_column
pivot運算符用于進行計算的值列。與unpivot一起使用時,value_column不能是輸入table_source中的現有列的名稱。
for pivot_column
pivot運算符的透視列。pivot_column必須是可隱式或顯式轉換為nvarchar()的類型。
使用unpivot時,pivot_column是從table_source中提取輸出的列名稱,table_source中不能有該名稱的現有列。
in ( column_list )
在pivot子句中,column_list列出pivot_column中將成為輸出表的列名的值。
在unpivot子句中,column_list列出table_source中將被提取到單個pivot_column中的所有列名。
table_alias
輸出表的別名。
unpivot < unpivot_clause >
指定將輸入表中由column_list指定的多個列的值縮減為名為pivot_column的單個列。
常見的可能會用到pivot的情形是:需要生成交叉表格報表以匯總數據。交叉表是使用較為廣泛的一種表格式,例如,圖5-4所示的產品銷售表就是一個典型的交叉表,其中的月份和產品種類都可以繼續添加。但是,這種格式在進行數據表存儲的時候卻并不容易管理,要存儲圖5-4這樣的表格數據,數據表通常需要設計為圖5-5這樣的結構。這樣就帶來一個問題,用戶既希望數據容易管理,又希望能夠生成一種能夠容易閱讀的表格數據。好在pivot為這種轉換提供了便利。
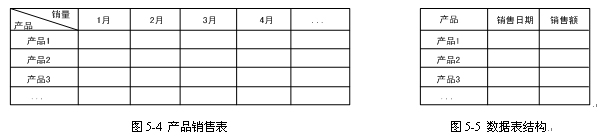
圖5-4 產品銷售表 圖5-5 數據表結構
假設sales.orders表中包含有productid(產品id)、ordermonth(銷售月份)和subtotal(銷售額)列,并存儲有如表5-2所示的內容。
表5-2 sales.orders表中的內容
| productid | ordermonth | subtotal |
| 1 | 5 | 100.00 |
| 1 | 6 | 100.00 |
| 2 | 5 | 200.00 |
| 2 | 6 | 200.00 |
| 2 | 7 | 300.00 |
| 3 | 5 | 400.00 |
| 3 | 5 | 400.00 |
執行下面的語句:
select productid, [5] as 五月, [6] as 六月, [7] as 七月
from
sales.orders pivot
(
sum (orders.subtotal)
for orders.ordermonth in
( [5], [6], [7] )
) as pvt
order by productid;
在上面的語句中,sales.orders是輸入表,orders.ordermonth是透視列(pivot_column),orders.subtotal是值列(value_column)。上面的語句將按下面的步驟獲得輸出結果集:
a.pivot首先按值列之外的列(productid和ordermonth)對輸入表sales.orders進行分組匯總,類似執行下面的語句:
select productid,
ordermonth,
sum (orders.subtotal) as sumsubtotal
from sales.orders
group by productid,ordermonth;
這時候將得到一個如表5-3所示的中間結果集。其中只有productid為3的產品由于在5月有2筆銷售記錄,被累加到了一起(值為800)。
表5-3 sales.orders表經分組匯總后的結果
| productid | ordermonth | sumsubtotal |
| 1 | 5 | 100.00 |
| 1 | 6 | 100.00 |
| 2 | 5 | 200.00 |
| 2 | 6 | 200.00 |
| 2 | 7 | 300.00 |
| 3 | 5 | 800.00 |
b.pivot根據for orders.ordermonth in指定的值5、6、7,首先在結果集中建立名為5、6、7的列,然后從圖5-3所示的中間結果中取出ordermonth列中取出相符合的值,分別放置到5、6、7的列中。此時得到的結果集的別名為pvt(見語句中as pvt的指定)。結果集的內容如表5-4所示。
表5-4 使用for orders.ordermonth in( [5], [6], [7] )后得到的結果集
| productid | 5 | 6 | 7 |
| 1 | 100.00 | 100.00 | null |
| 2 | 200.00 | 200.00 | 200.00 |
| 3 | 800.00 | null | null |
c.最后根據select productid, [5] as 五月, [6] as 六月, [7] as 七月from的指定,從別名pvt結果集中檢索數據,并分別將名為5、6、7的列在最終結果集中重新命名為五月、六月、七月。這里需要注意的是from的含義,其表示從經pivot關系運算符得到的pvt結果集中檢索數據,而不是從sales.orders中檢索數據。最終得到的結果集如表5-5所示。
表5-5 由表5-2所示的sales.orders表將行轉換為列得到的最終結果集
| productid | 五月 | 六月 | 七月 |
| 1 | 100.00 | 100.00 | null |
| 2 | 200.00 | 200.00 | 200.00 |
| 3 | 800.00 | null | null |
unpivot與pivot執行幾乎完全相反的操作,將列轉換為行。但是,unpivot并不完全是pivot的逆操作,由于在執行pivot過程中,數據已經被進行了分組匯總,所以使用unpivot并不會重現原始表值表達式的結果。假設表5-5所示的結果集存儲在一個名為mypvt的表中,現在需要將列標識符“五月”、“六月”和“七月”轉換到對應于相應產品id的行值(即返回到表5-3所示的格式)。這意味著必須另外標識兩個列,一個用于存儲月份,一個用于存儲銷售額。為了便于理解,仍舊分別將這兩個列命名為ordermonth和sumsubtotal。參考下面的語句:
create table mypvt (productid int, 五月int, 六月 int, 七月int); --建立mypvt表
go
--將表5-5中所示的值插入到mypvt表中
insert into mypvt values (1,100,100,0);
insert into mypvt values (2,200,200,200);
insert into mypvt values (3,800,0,0);
--執行unpivot
select productid, ordermonth, subtotal
from
mypvt unpivot
(subtotal for ordermonth in
(五月, 六月, 七月)
)as unpvt;
上面的語句將按下面的步驟獲得輸出結果集:
a.首先建立一個臨時結果集的結構,該結構中包含mypvt表中除in (五月, 六月, 七月)之外的列,以及subtotal for ordermonth中指定的值列(subtotal)和透視列(ordermonth)。
b.將在mypvt中逐行檢索數據,將表的列名稱(在in (五月, 六月, 七月)中指定)放入ordermonth列中,將相應的值放入到subtotal列中。最后得到的結果集如表5-6所示。
表5-6 使用unpivot得到的結果集
| productid | ordermonth | subtotal |
| 1 | 五月 | 100 |
| 1 | 六月 | 100 |
| 1 | 七月 | 0 |
| 2 | 五月 | 200 |
| 2 | 六月 | 200 |
| 2 | 七月 | 200 |
| 3 | 五月 | 800 |
| 3 | 六月 | 0 |
| 3 | 七月 | 0 |
新聞熱點






疑難解答













