查詢計(jì)劃緩存及各種 set 選項(xiàng)(與 showplan 相關(guān)及其他)
各種 set 選項(xiàng)——多數(shù)與 showplan 相關(guān)——以多種復(fù)雜的方式影響著查詢計(jì)劃和執(zhí)行上下文的編譯、緩存和重用。下表匯總了相關(guān)的詳細(xì)信息。
應(yīng)按如下順序閱讀該表中的內(nèi)容。批處理通過表中第一列所指定的特定模式提交給 sql server。已提交的批處理的計(jì)劃緩存中可能存在、也可能不存在已緩存的查詢計(jì)劃。第 2 列和第 3 列描述了存在已緩存的查詢計(jì)劃時(shí)的情況;第 4 列和第 5 列說明了不存在已緩存的查詢計(jì)劃時(shí)的情況。在每個(gè)類別中,查詢計(jì)劃和執(zhí)行上下文的各種情況都是獨(dú)立的。表中說明了結(jié)構(gòu)(查詢計(jì)劃或執(zhí)行上下文)所發(fā)生的情況:是否被緩存、重用和使用。
| 模式名稱 | 存在已緩存的查詢計(jì)劃時(shí) | 存在已緩存的查詢計(jì)劃時(shí) | 不存在已緩存的查詢計(jì)劃時(shí) | 不存在已緩存的查詢計(jì)劃時(shí) |
查詢計(jì)劃 | 執(zhí)行上下文 | 查詢計(jì)劃 | 執(zhí)行上下文 | |
showplan_text, showplan_all, showplan_xml | 被重用(無編譯) | 被重用 | 被緩存(編譯) | 生成一個(gè)執(zhí)行上下文,對(duì)其進(jìn)行緩存但不使用它 |
statistics profile, statistics xml, statistics io, statistics time | 被重用(無編譯) | 不被重用生成并使用一個(gè)全新的執(zhí)行上下文,但不對(duì)其進(jìn)行緩存 | 被緩存(編譯) | 生成并使用一個(gè)全新的執(zhí)行上下文,但不對(duì)其進(jìn)行緩存 |
noexec | 被重用(無編譯) | 被重用 | 被緩存(編譯) | 不生成執(zhí)行上下文(由于“noexec”模式)。 |
parseonly(例如,在查詢分析器或 management studio 中按“分析”按鈕) | 無 | 無 | 無 | 無 |
對(duì)于每個(gè)查詢計(jì)劃和執(zhí)行上下文,都會(huì)保留一個(gè)成本。該成本會(huì)在一定程度上控制計(jì)劃或上下文在計(jì)劃緩存中的存在時(shí)間。在 sql server 2000 和 sql server 2005 中,成本的計(jì)算和操作方式有所不同。詳細(xì)情況如下。
sql server 2000:對(duì)于查詢計(jì)劃,成本用于度量查詢優(yōu)化器用于優(yōu)化批處理的服務(wù)器資源(cpu 時(shí)間和 i/o)。對(duì)于特殊查詢,其成本為零。對(duì)于執(zhí)行上下文,成本用于度量用于初始化執(zhí)行上下文以便各個(gè)語句做好執(zhí)行準(zhǔn)備的服務(wù)器資源(cpu 時(shí)間和 i/o)。請(qǐng)注意,執(zhí)行上下文成本并不包含批處理執(zhí)行期間所帶來的成本(cpu 和 i/o)。通常,執(zhí)行上下文成本低于查詢計(jì)劃成本。
以下說明了在 sql server 2000 中,批處理的查詢計(jì)劃如何帶來成本開銷。影響成本的因素有四個(gè):生成計(jì)劃所用的 cpu 時(shí)間 (cputime);從磁盤讀取的頁數(shù) (ioread);寫入磁盤的頁數(shù) (iowrite);以及批處理的查詢計(jì)劃所占的內(nèi)存頁數(shù) (pagecount)。這樣,查詢計(jì)劃成本可表示為(f 是一個(gè)數(shù)學(xué)函數(shù)):
query plan cost c = f(cputime, ioread, iowrite) / pagecount以下說明了在 sql server 2000 中,批處理的執(zhí)行上下文如何帶來成本開銷。上方等式中單獨(dú)的成本 c 將針對(duì)批處理中的每個(gè)語句進(jìn)行計(jì)算,并加以累計(jì)。但是請(qǐng)注意,單獨(dú)成本現(xiàn)在是語句初始化成本,而非語句編譯或執(zhí)行成本。
有時(shí),惰性寫入器進(jìn)程會(huì)清除計(jì)劃緩存并減少成本。將成本除于四,并根據(jù)需要四舍五入。(例如,25 --> 6 --> 1 --> 0。)當(dāng)內(nèi)存方面有壓力時(shí),成本為零的查詢計(jì)劃和執(zhí)行上下文將從計(jì)劃緩存中刪除。重用查詢計(jì)劃或執(zhí)行上下文時(shí),其成本會(huì)被重置回編譯(或執(zhí)行上下文生成)成本。特殊查詢的查詢計(jì)劃成本總是以 1 為單位逐漸遞增。因此,頻繁執(zhí)行的批處理的查詢計(jì)劃在計(jì)劃緩存中的存在時(shí)間要長于不頻繁執(zhí)行的批處理的計(jì)劃。
sql server 2005:特殊查詢的成本為零。另外,查詢計(jì)劃的成本用于度量生成其所需的資源量。尤其,該成本按“記號(hào)數(shù)”計(jì)算,最大值為 31,共由三部分組成:
成本 = i/o 成本 + 上下文開關(guān)成本(用于度量 cpu 成本) + 內(nèi)存成本
該成本各部分的計(jì)算方法如下。
| • | 兩個(gè) i/o 的成本為 1 個(gè)記號(hào),最大成本為 19 個(gè)記號(hào)。 |
| • | 另個(gè)上下文開關(guān)的成本為 1 個(gè)記號(hào),最大成本為 8 個(gè)記號(hào)。 |
| • | 十六個(gè)內(nèi)存頁 (128 kb) 的成本為 1 個(gè)記號(hào),最大成本為 4 個(gè)記號(hào)。 |
在 sql server 2005 中,計(jì)劃緩存不同于數(shù)據(jù)緩存。此外,還有一些特定于功能的緩存。在 sql server 2005 中,惰性寫入器進(jìn)程不會(huì)增加成本。相反,只要計(jì)劃緩存的大小達(dá)到緩沖池大小的 50%,下一個(gè)計(jì)劃緩存訪問就會(huì)以 1 為單位減少所有計(jì)劃的記號(hào)數(shù)。請(qǐng)注意,由于這種減少情況是隨為查找計(jì)劃而訪問計(jì)劃緩存的線程而產(chǎn)生的,因此可認(rèn)為這一減少是以惰性方式進(jìn)行的。在 sql server 2005 中,如果所有緩存大小的總和達(dá)到或超過了緩沖池大小的 75%,那么將激活一個(gè)專用的資源監(jiān)視器線程,它將減少所有緩存中的所有對(duì)象的記號(hào)數(shù)。(所以該線程的行為方式與 sql server 2000 中的惰性寫入器線程大致相同。)查詢計(jì)劃重用導(dǎo)致查詢計(jì)劃成本被重置為初識(shí)值。
五、文本其他部分的內(nèi)容說明
到此,讀者應(yīng)該清楚:為了獲得良好的 sql server 批處理執(zhí)行性能,需要執(zhí)行下列這兩項(xiàng)操作:
| • | 應(yīng)盡可能重用查詢計(jì)劃。這可避免不必要的查詢編譯成本。計(jì)劃重用還會(huì)帶來更高的計(jì)劃緩存使用率,而反過來又會(huì)實(shí)現(xiàn)更好的服務(wù)器性能。 |
| • | 應(yīng)避免可能造成查詢編譯次數(shù)增多的操作。減少重新編譯次數(shù)可節(jié)省服務(wù)器資源(cpu 和內(nèi)存),并增加批處理執(zhí)行次數(shù),同時(shí)達(dá)到預(yù)期性能。 |
下一節(jié)描述了有關(guān)查詢計(jì)劃重用的詳細(xì)信息。同時(shí),在適當(dāng)位置給出了可實(shí)現(xiàn)更好的計(jì)劃重用的最佳實(shí)務(wù)。再下一節(jié)中,我們介紹了可能導(dǎo)致重新編譯次數(shù)增多的一些常見方案,并給出了避免發(fā)生這種情況的最佳實(shí)務(wù)。
六、查詢計(jì)劃重用計(jì)劃緩存包含查詢計(jì)劃和執(zhí)行上下文。概念上,查詢計(jì)劃同與之相關(guān)聯(lián)的執(zhí)行上下文相鏈接。批處理 s 的查詢計(jì)劃重用獨(dú)立于 s 本身(比如:查詢文本或存儲(chǔ)過程名稱)以及該批處理的一些外部因素(比如:生成 s 的用戶名,生成 s 的 set 選項(xiàng),與 s 相關(guān)聯(lián)的連接的 set 選項(xiàng)等等)。有一些外部因素會(huì)影響計(jì)劃重用:只要兩個(gè)相同的查詢?cè)谶@些因素之一上有所不同,就將無法使用常見計(jì)劃。而其他外部因素則不會(huì)影響計(jì)劃重用。
大多數(shù)影響計(jì)劃重用的因素都羅列在 sys.syscacheobjects 虛擬表中。下方列表描述了“典型用法”方案中的因素。在某些情況下,條目只會(huì)指出何時(shí)計(jì)劃未被緩存(并因此永不被重用)。
通常,如果導(dǎo)致查詢計(jì)劃被緩存的連接的服務(wù)器、數(shù)據(jù)庫和連接設(shè)置與當(dāng)前連接的相應(yīng)設(shè)置相同,就會(huì)重用查詢計(jì)劃。其次,批處理所引用的對(duì)象不要求名稱解析。例如,sales.salesorderdetail 不要求名稱解析,而 salesorderdetail 則相反,因?yàn)槊麨?salesorderdetail 的表會(huì)存在于多個(gè)數(shù)據(jù)庫中。大體上,完全合格的對(duì)象名稱會(huì)為計(jì)劃重用提供更多的機(jī)會(huì)。
影響計(jì)劃重用的因素請(qǐng)注意,查詢計(jì)劃如果還未被緩存,就不能被重用。 所以,我們將僅明確指出無可緩存性,即表示無重用。
1. | 如果一個(gè)存儲(chǔ)過程在數(shù)據(jù)庫 d1 中執(zhí)行,那么在不同的數(shù)據(jù)庫 d2 中執(zhí)行相同的存儲(chǔ)過程時(shí),就不會(huì)重用其查詢計(jì)劃。請(qǐng)注意,這一行為僅適用于存儲(chǔ)過程,并不適用于特殊查詢、預(yù)備的查詢或動(dòng)態(tài) sql。 | ||||||||||||||||||||||||||||||||||||
2. | 對(duì)于觸發(fā)器執(zhí)行,受執(zhí)行影響的行數(shù)(1 比 n)——按被插入或被刪除的表中的行數(shù)度量——是確定計(jì)劃緩存命中的一個(gè)顯著因素。請(qǐng)注意,該行為特別針對(duì)觸發(fā)器,并不適用于存儲(chǔ)過程。 在 sql server 2005 instead of 觸發(fā)器中,“1-plan”由影響 0 和 1 行的執(zhí)行共享,而對(duì)于 non-instead of ("after") 觸發(fā)器,“1-plan”僅由影響 1 行的執(zhí)行使用,同時(shí)“n-plan”由影響 0 和 n 行 (n > 1) 的執(zhí)行使用。 | ||||||||||||||||||||||||||||||||||||
3. | 從不緩存大容量插入語句,但卻緩存與大容量插入相關(guān)聯(lián)的觸發(fā)器。 | ||||||||||||||||||||||||||||||||||||
4. | 不緩存包含任何長于 8 kb 的文本的批處理。因此,無法緩存這種批處理的查詢計(jì)劃。(應(yīng)用常量折疊之后,測量文本的長度。) | ||||||||||||||||||||||||||||||||||||
5. | 標(biāo)有“復(fù)制標(biāo)記”(與某位復(fù)制用戶相關(guān)聯(lián))的批處理與沒有該標(biāo)記的批處理不相匹配。 | ||||||||||||||||||||||||||||||||||||
6. | 從 sql server 2005 的通用語言運(yùn)行時(shí) (clr) 調(diào)用的批處理與從 clr 外部提交的相同批處理不相匹配。然而,兩個(gè)由 clr 提交的批處理可重用相同的計(jì)劃。相同的情況適用于:
| ||||||||||||||||||||||||||||||||||||
7. | 不緩存通過 sp_resyncquery 提交的查詢的查詢計(jì)劃。所以,如果重新提交了(通過或不通過 sp_resyncquery 提交)該查詢,就需要重新進(jìn)行編譯。 | ||||||||||||||||||||||||||||||||||||
8. | sql server 2005 允許在 t-sql 批處理上定義游標(biāo)。如果批處理被當(dāng)作單獨(dú)的語句提交,那么就不會(huì)對(duì)游標(biāo)重用(部分)計(jì)劃。 | ||||||||||||||||||||||||||||||||||||
9. | 下列 set 選項(xiàng)會(huì)影響計(jì)劃重用。
此外,ansi_defaults 也會(huì)影響計(jì)劃重用,因?yàn)槠淇捎糜谕瑫r(shí)更改下列 set 選項(xiàng)(其中有一些會(huì)影響計(jì)劃重用):ansi_nulls、ansi_null_dflt_on、ansi_padding、ansi_warnings、cursor_close_on_commit、implicit_transactions、quoted_identifier. 上面這些 set 選項(xiàng)會(huì)影響計(jì)劃重用,因?yàn)?sql server 2000 和 sql server 2005 都能執(zhí)行“常量折疊”(在編譯時(shí)評(píng)估常量表達(dá)式以實(shí)現(xiàn)一些優(yōu)化),而且這些選項(xiàng)的設(shè)置會(huì)影響這類表達(dá)式的結(jié)果。 部分上述 set 選項(xiàng)的設(shè)置羅列在 sys.syscacheobjects 虛擬表中(比如:“langid”和“dateformat”。 請(qǐng)注意,可使用幾種方法更改部分上述 set 選項(xiàng)的值:
在 set 選項(xiàng)存在沖突時(shí),用戶級(jí)和連接級(jí) set 選項(xiàng)值優(yōu)先于數(shù)據(jù)庫和服務(wù)器級(jí) set 選項(xiàng)值。另外,如果某個(gè)數(shù)據(jù)庫級(jí) set 選項(xiàng)有效,那么對(duì)于引用多個(gè)數(shù)據(jù)庫(可能擁有不同的 set 選項(xiàng)值)的批處理,數(shù)據(jù)庫(該批處理在其上下文中執(zhí)行)的 set 選項(xiàng)優(yōu)先于其他數(shù)據(jù)庫的 set 選項(xiàng)。 最佳實(shí)務(wù):為了避免與 set 選項(xiàng)相關(guān)的重新編譯,在連接時(shí)創(chuàng)建 set 選項(xiàng),并確保其在連接期間不會(huì)發(fā)生變化。 | ||||||||||||||||||||||||||||||||||||
10. | 帶有不合格對(duì)象名的批處理不會(huì)重用查詢計(jì)劃。例如,在“select * from mytable”中,如果 alice 發(fā)出了相應(yīng)的查詢并擁有帶有相應(yīng)名稱的表,mytable 可能會(huì)正常地解析到 alice。同樣,mytable 可能解析到 bob.mytable。在這種情況下,sql server 不會(huì)重用查詢計(jì)劃。但是,如果 alice 發(fā)出了“select * from dbo.mytable”,就不會(huì)存在不確定性,因?yàn)閷?duì)象被唯一指定,并可重用查詢計(jì)劃。(請(qǐng)參見 sys.syscacheobjects 中的 uid 列。該列給出了生成計(jì)劃的連接的用戶 id。只有帶有相同用戶 id 的查詢計(jì)劃才可被重用。當(dāng) uid = -2 時(shí),表示該查詢不依賴于隱式名稱解析,并可在不同的用戶 id 間共享。) | ||||||||||||||||||||||||||||||||||||
11. | 當(dāng)通過“create procedure ...with recompile”選項(xiàng)創(chuàng)建存儲(chǔ)過程時(shí),無論何時(shí)執(zhí)行該存儲(chǔ)過程,都不會(huì)緩存其查詢計(jì)劃。不存在計(jì)劃重用的可能性:每次執(zhí)行這種過程都會(huì)導(dǎo)致重新編譯。 | ||||||||||||||||||||||||||||||||||||
12. | 最佳實(shí)務(wù):“create procedure ...with recompile”可用于標(biāo)記通過各種參數(shù)調(diào)用的存儲(chǔ)過程,而其最佳的查詢計(jì)劃高度依賴于在調(diào)用期間所提供的參數(shù)值。 | ||||||||||||||||||||||||||||||||||||
13. | 當(dāng)使用“exec ...with recompile”執(zhí)行存儲(chǔ)過程 p 時(shí),p 被重新編譯。即使 p 的一個(gè)查詢計(jì)劃預(yù)先存在于計(jì)劃緩存中并可被重用,也不會(huì)發(fā)生重用。不緩存為 p 全新編譯的查詢計(jì)劃。 |
最佳實(shí)務(wù):當(dāng)通過非典型參數(shù)值執(zhí)行存儲(chǔ)過程時(shí),“exec ...with recompile”可用于確保新的查詢計(jì)劃不會(huì)替代使用典型參數(shù)值編譯的現(xiàn)有的已緩存計(jì)劃。
“exec ...with recompile”還可與用戶定義的函數(shù)一起使用,但只有在存在 exec 關(guān)鍵字時(shí)才可以。
1. | 為了避免通過不同的參數(shù)值執(zhí)行的查詢存在多個(gè)查詢計(jì)劃,應(yīng)使用 sp_executesql 存儲(chǔ)過程執(zhí)行該查詢。如果同一個(gè)查詢計(jì)劃有益于所有或大多數(shù)參數(shù)值,那么這種方法將很有用。 |
2. | 可緩存臨時(shí)存儲(chǔ)過程(針對(duì)會(huì)話范圍及全局),因而可進(jìn)行重用。 |
3. | 在 sql server 2005 中,不緩存創(chuàng)建或更新統(tǒng)計(jì)(手動(dòng)或自動(dòng))的查詢的計(jì)劃。 |
回想一下,當(dāng) sql server 在批處理 b 中執(zhí)行語句后,重新編譯了某些(或所有)語句,這時(shí) b 被重新編譯。產(chǎn)生重新編譯的原因可分為兩大類:
| • | 與正確性相關(guān)的原因。如果不進(jìn)行重新編譯會(huì)導(dǎo)致錯(cuò)誤的結(jié)果或操作,那么就必須對(duì)批處理進(jìn)行重新編譯。與正確性相關(guān)的原因又可分為兩類。
| ||||
| • | 與計(jì)劃最優(yōu)性相關(guān)的原因。自 b 上次編譯之后,b 所引用的表中的數(shù)據(jù)可能發(fā)生巨大的變化。在這種情況下,可能會(huì)對(duì) b 進(jìn)行重新編譯,以便獲得更快捷的查詢執(zhí)行計(jì)劃。 |
下面兩節(jié)將詳細(xì)介紹這兩個(gè)類別。
導(dǎo)致批處理重新編譯的與正確性相關(guān)的原因后面列舉了一些導(dǎo)致與正確性相關(guān)的重新編譯的具體操作。因?yàn)楸仨氝M(jìn)行這類重新編譯,所以用戶可以選擇不進(jìn)行這些操作,或者在 sql server 運(yùn)行的非高峰期執(zhí)行這些操作。
對(duì)象的架構(gòu)1. | 無論批處理引用的任何對(duì)象在何時(shí)發(fā)生了架構(gòu)更改,批處理都會(huì)被重新編譯。“架構(gòu)更改”的定義如下:
| ||||||||||||||
2. | 在存儲(chǔ)過程或觸發(fā)器上運(yùn)行 sp_recompile 會(huì)導(dǎo)致它們?cè)谙乱淮螆?zhí)行時(shí)被重新編譯。在表或視圖上運(yùn)行 sp_recompile 時(shí),所有引用該表或視圖的存儲(chǔ)過程都將在下一次運(yùn)行時(shí)被重新編譯。sp_recompile 通過遞增上述對(duì)象的磁盤上的架構(gòu)版本來完成重新編譯。 | ||||||||||||||
3. | 下列操作會(huì)刷新整個(gè)計(jì)劃緩存,從而導(dǎo)致對(duì)之后所提交的批處理進(jìn)行全新編譯:
|
下列操作將刷新引用特定數(shù)據(jù)庫的計(jì)劃緩存條目,并隨之導(dǎo)致全新編譯。
| • | dbcc flushprocindb 命令 |
| • | alter database ...modify name = 命令 |
| • | alter database ...set online 命令 |
| • | alter database ...set offline 命令 |
| • | alter database ...set emergency 命令 |
| • | drop database 命令 |
| • | 數(shù)據(jù)庫自動(dòng)關(guān)閉時(shí) |
| • | 當(dāng)通過 check option 創(chuàng)建視圖時(shí),在其中創(chuàng)建該視圖的數(shù)據(jù)庫的計(jì)劃緩存條目將被刷新。 |
| • | 運(yùn)行 dbcc checkdb 時(shí),將創(chuàng)建指定數(shù)據(jù)庫的一個(gè)副本。作為 dbcc checkdb 執(zhí)行的一部分,將執(zhí)行針對(duì)該副本的一些查詢,并緩存其計(jì)劃。在 dbcc checkdb 執(zhí)行結(jié)束時(shí),將刪除該副本以及針對(duì)其的查詢的查詢計(jì)劃。 “引用特定數(shù)據(jù)庫的計(jì)劃緩存條目”這一概念需要解釋一下。數(shù)據(jù)庫 id 是計(jì)劃緩存的鍵之一。假設(shè)執(zhí)行了下列命令序列。 use master假定在計(jì)劃緩存中緩存了 q。與 q 的計(jì)劃相關(guān)聯(lián)的數(shù)據(jù)庫 id 將成為“master”而非“db1”的數(shù)據(jù)庫 id。 |
當(dāng) sql server 2005 的事務(wù)級(jí)快照隔離級(jí)別開啟時(shí),通常會(huì)發(fā)生計(jì)劃重用。只要快照隔離級(jí)別下的批處理中的語句引用了一個(gè)對(duì)象(其架構(gòu)自開啟快照隔離模式后即被更改),同時(shí)緩存并重用了該語句的查詢計(jì)劃,就會(huì)發(fā)生語句級(jí)重新編譯。全新編譯的查詢計(jì)劃將被緩存,而該語句本身則會(huì)失敗(根據(jù)相應(yīng)隔離級(jí)別的語義)。如果未緩存查詢計(jì)劃,就會(huì)發(fā)生編譯,隨后被編譯的查詢計(jì)劃會(huì)被緩存,而語句本身則會(huì)失敗。
set 選項(xiàng)正如第 6 節(jié)已經(jīng)提到的,在批處理開始執(zhí)行后更改下列 set 選項(xiàng)中的一項(xiàng)或多項(xiàng),將導(dǎo)致重新編譯:ansi_null_dflt_off、ansi_null_dflt_on、ansi_nulls、ansi_padding、ansi_warnings、arithabort、concat_null_yields_null、datefirst、dateformat、forceplan、language、no_browsetable、numeric_roundabort、quoted_identifier。
導(dǎo)致批處理重新編譯的與計(jì)劃最優(yōu)性相關(guān)的原因sql server 設(shè)計(jì)用于當(dāng)數(shù)據(jù)庫中的數(shù)據(jù)更改時(shí),生成最佳的查詢執(zhí)行計(jì)劃。使用 sql server 的查詢處理器中的統(tǒng)計(jì)(直方圖)來跟蹤數(shù)據(jù)更改。所以,與計(jì)劃最優(yōu)性相關(guān)的原因同統(tǒng)計(jì)密切相關(guān)。
開始詳細(xì)介紹與計(jì)劃最優(yōu)性相關(guān)的原因之前,讓我們列出不會(huì)發(fā)生與計(jì)劃最優(yōu)性相關(guān)的重新編譯的情況。
| • | 當(dāng)計(jì)劃屬于“常用計(jì)劃”時(shí)。當(dāng)查詢優(yōu)化器決定查詢所引用的給定表及其上的索引時(shí),將產(chǎn)生常用計(jì)劃,只能有一個(gè)計(jì)劃。顯而易見,在這種情況下進(jìn)行重新編譯并沒有什么用。當(dāng)然,生成過常用計(jì)劃的查詢不一定總是生成這類計(jì)劃。例如,可能在基礎(chǔ)表上創(chuàng)建新的索引,從而就有多個(gè)訪問路徑供查詢優(yōu)化器使用。如第 7.1 節(jié)所提到的,所添加的這類索引將被刪除,而與正確性相關(guān)的重新編譯可能將常用計(jì)劃替換為非常用計(jì)劃。 |
| • | 當(dāng)查詢包含“keepfixed plan”提示時(shí),不會(huì)出于與計(jì)劃最優(yōu)性相關(guān)的原因重新編譯該查詢的計(jì)劃。 |
| • | 當(dāng)查詢計(jì)劃引用的所有表都為只讀時(shí),該計(jì)劃將被重新編譯。 |
| • | 這一點(diǎn)只適用于 sql server 2000。假定某個(gè)查詢計(jì)劃被編譯(不是重新編譯),而作為編譯的一部分,查詢處理器將決定更新表 t 上的統(tǒng)計(jì) s。查詢處理器試圖在 t 上獲取一個(gè)特殊的“統(tǒng)計(jì)鎖”。如果其他進(jìn)程正在更新 t 上的某個(gè)統(tǒng)計(jì)(不一定是 s!),查詢處理器就無法在 t 上獲得統(tǒng)計(jì)鎖。在這種情況下,查詢處理器不會(huì)更新 s。另外,上述查詢計(jì)劃不會(huì)再因?yàn)榕c計(jì)劃最優(yōu)性相關(guān)的原因而被重新編譯。這就像通過“keepfixed plan”提示提交查詢一樣。 |
| • | 這種情況與上面著重提到的一個(gè)情況相同,只是此處的查詢計(jì)劃被緩存了。換句話說,這種情況涉及重新編譯,而前面的那個(gè)情況與之相反,僅涉及編譯。對(duì)于這種重新編譯情形,假設(shè)查詢處理器試圖在 t 上獲得一個(gè)“統(tǒng)計(jì)鎖”,但失敗了。在這種情況下,查詢處理器會(huì)跳過對(duì)統(tǒng)計(jì) s 的更新;使用過時(shí)的統(tǒng)計(jì) s;并同平常一樣,通過其他重新編譯步驟/檢查繼續(xù)進(jìn)行操作。因而,借助可能較慢的查詢執(zhí)行計(jì)劃可避免重新編譯。 |
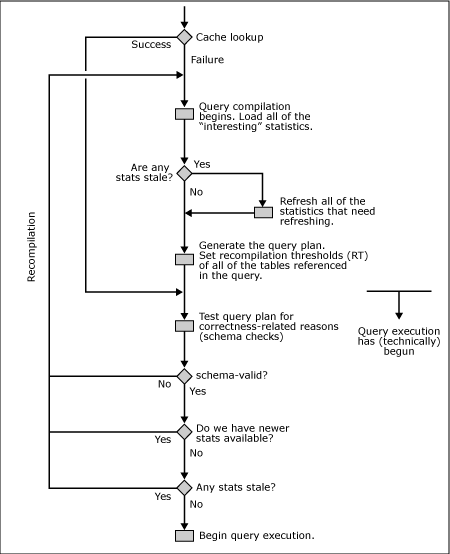
下方流程圖簡單明了地描述了 sql server 中的批處理編譯和重新編譯過程。主要的處理步驟如下所示(本文檔后面將對(duì)各個(gè)步驟進(jìn)行詳細(xì)介紹):
1. | sql server 開始編譯一個(gè)查詢。(正如前面提到的,批處理是一個(gè)編譯和緩存單位,而批處理中的各個(gè)語句則是逐一進(jìn)行編譯。) |
2. | 可能有助于生成最佳查詢計(jì)劃的所有“引起關(guān)注的”統(tǒng)計(jì)都將從磁盤載入內(nèi)存。 |
3. | 如果任何統(tǒng)計(jì)過時(shí)了,那么將逐一對(duì)其進(jìn)行更新。查詢編譯將等待更新的結(jié)束。對(duì)于這一步驟,sql server 2000 和 sql server 2005 間的一個(gè)重要不同之處在于:在 sql server 2005 中,可能會(huì)有選擇地對(duì)統(tǒng)計(jì)進(jìn)行異步更新。也就是說,統(tǒng)計(jì)更新線程不阻止查詢編譯線程。編譯線程將用狀態(tài)統(tǒng)計(jì)繼續(xù)操作。 |
4. | 生成查詢計(jì)劃。查詢中所引用的所有表的重新編譯閾值隨查詢計(jì)劃一起被保存。 |
5. | 這時(shí),查詢執(zhí)行在理論上已經(jīng)開始。現(xiàn)在測試查詢計(jì)劃以查找與正確性相關(guān)的原因。相關(guān)原因在第 7.1 中有所描述。 |
6. | 如果就任何與正確性相關(guān)的原因而言,計(jì)劃不正確,那么將開始進(jìn)行重新編譯。請(qǐng)注意,由于查詢執(zhí)行在理論上已經(jīng)開始了,因此剛剛開始的編譯即為重新編譯。 |
7. | 如果計(jì)劃“正確”,那么各種重新編譯閾值將與表基數(shù)或各種表修改計(jì)數(shù)器(sql server 2000 中的 rowmodctr 或 sql server 2005 中的 colmodctr)相比較。 |
8. | 如果根據(jù)步驟 7 中進(jìn)行的比較認(rèn)定有任何統(tǒng)計(jì)過時(shí)了,那么將進(jìn)行重新編譯。 |
9. | 如果步驟 7 中的所有比較都成功完成,那么將開始實(shí)際的查詢執(zhí)行。 |
每個(gè) select、insert、update 和 detele 語句都訪問一個(gè)或多個(gè)表。表內(nèi)容因 insert、update 和 delete 等操作而發(fā)生變化。sql server 的查詢處理器設(shè)計(jì)用于通過潛在地生成不同的查詢計(jì)劃(每個(gè)查詢計(jì)劃在生成時(shí)都是最佳的),來適應(yīng)這種變化。使用表基數(shù)直接跟蹤表內(nèi)容,并使用表列上的統(tǒng)計(jì)(直方圖)進(jìn)行間接跟蹤。
每個(gè)表都有一個(gè)與之相關(guān)聯(lián)的重新編譯閾值 (rt)。rt 是表中列數(shù)的一個(gè)函數(shù)。在查詢編譯期間,查詢處理器將不載入或載入若干個(gè)在查詢中引用的表上的統(tǒng)計(jì)。這些統(tǒng)計(jì)被稱為引人關(guān)注的統(tǒng)計(jì)。對(duì)于查詢中引用的每個(gè)表,已編譯的查詢計(jì)劃包含:
| • | 重新編譯閾值 |
| • | 列出查詢編譯期間載入的所有統(tǒng)計(jì)的列表對(duì)于每個(gè)統(tǒng)計(jì),將保存計(jì)算表修改次數(shù)的計(jì)數(shù)器的快照值。在 sql server 2000 中,該計(jì)數(shù)器被稱為 rowmodctr,而在 sql server 2005 中則稱為 colmodctr。每個(gè)表列中都存在一個(gè)單獨(dú)的 colmodctr(非永久性計(jì)算列除外)。 |
| modctr(snapshot) – modctr(current) | >= rtmodctr(current) 表示修改計(jì)數(shù)器的當(dāng)前值,而 modctr(snapshot) 表示查詢計(jì)劃上次編譯時(shí)修改計(jì)數(shù)器的值。如果閾值交叉在任何令人關(guān)注的統(tǒng)計(jì)上取得了成功,那么將重新編譯查詢計(jì)劃。在 sql server 2000 中,包含該查詢的整個(gè)批處理都被重新編譯;而在 sql server 2005 中,僅重新編譯上述查詢。
如果表或索引視圖 t 上沒有統(tǒng)計(jì),或者在查詢編譯期間 t 上現(xiàn)有的統(tǒng)計(jì)都不被認(rèn)為是“令人關(guān)注的”,那么仍會(huì)僅根據(jù) t 的基數(shù),執(zhí)行下列閾值交叉測試。
| card(snapshot) – card(current) | >= rtcard(current) 表示當(dāng)前 t 中的行數(shù),而 card(snapshot) 表示查詢計(jì)劃上次編譯時(shí)的行數(shù)。
下面幾節(jié)將介紹“整體情況”中引入的幾個(gè)重要概念。
“令人關(guān)注”的統(tǒng)計(jì)的概念對(duì)于每個(gè)查詢計(jì)劃 p,優(yōu)化器保存被載入以生成 p 的統(tǒng)計(jì)的 id。請(qǐng)注意,“載入的”集同時(shí)包含:
| • | 用作操作符(顯示在 p 中的)的基數(shù)評(píng)估器的統(tǒng)計(jì) |
| • | 用作查詢計(jì)劃(在查詢優(yōu)化期間加以考慮但為了支持 p 而被拋棄)中的基數(shù)評(píng)估器的統(tǒng)計(jì) |
換而言之,查詢優(yōu)化器出于某個(gè)原因或其他原因,將載入的統(tǒng)計(jì)認(rèn)作是“令人關(guān)注的”。
回想一下,統(tǒng)計(jì)可以手動(dòng)或自動(dòng)創(chuàng)建或更新。還會(huì)因執(zhí)行下列命令而導(dǎo)致統(tǒng)計(jì)更新:
| • | create index ...with drop existing |
| • | sp_createstats 存儲(chǔ)過程 |
| • | sp_updatestats 存儲(chǔ)過程 |
| • | dbcc dbreindex(但不是 dbcc indexdefrag!) |
表的重新編譯閾值可部分決定引用該表的查詢的重新編譯頻率。rt 取決于表類型(永久或臨時(shí))以及編譯查詢計(jì)劃時(shí)表中的行數(shù)(基數(shù))。在批處理中引用的所有表的重新編譯閾值都將隨該批處理的查詢計(jì)劃一起保存。
rt 的計(jì)算方法如下所示。(n 表示編譯查詢計(jì)劃時(shí)表的基數(shù)。)
| • | 永久表
| ||||||
| • | 臨時(shí)表
| ||||||
| • | 表變量
|
表修改計(jì)數(shù)器(rowmodctr 和 colmodctr)
如上所述,rt 與表所執(zhí)行的修改次數(shù)進(jìn)行了對(duì)比。使用稱為 rowmodctr(在 sql server 2000 中)和 colmodctr(在 sql server 2005 中)的計(jì)數(shù)器跟蹤表所進(jìn)行的修改次數(shù)。 這兩種計(jì)數(shù)器都不是針對(duì)具體事務(wù)的。例如,如果啟動(dòng)了某個(gè)事務(wù),并在表中插入了 100 行,然后再回滾操作,那么對(duì)修改計(jì)數(shù)器所作的更改將不會(huì)被回滾。
rowmodctr (sql server 2000)每個(gè)表都有一個(gè) rowmodctr 與之相關(guān)聯(lián)。其值可從 sysindexes 系統(tǒng)表獲得。在表或索引視圖 t 的一個(gè)或多個(gè)列上創(chuàng)建的每個(gè)統(tǒng)計(jì)都有一個(gè) rowmodctr 的快照值與之相關(guān)聯(lián)。無論該統(tǒng)計(jì)何時(shí)被更新——手動(dòng)或自動(dòng)(通過 sql server 的自動(dòng)統(tǒng)計(jì)功能),rowmodctr 的快照值也會(huì)被刷新。有關(guān) rowmodctr 的詳細(xì)信息在下方白皮書中有所描述:http://msdn.microsoft.com/library/default.asp?url=/nhp/default.asp?contentid=28000409
“閾值交叉”測試中所提到的 rowmodctr(current) 是 sysindexes 系統(tǒng)表(針對(duì)堆棧或聚集索引)在查詢編譯期間進(jìn)行測試時(shí)所保留的值。
rowmodctr 可在 sql server 2005 服務(wù)器上使用,但其值總為 0。
補(bǔ)充說明一下,在 sql server 2000 中,當(dāng) rowmodctr 為 0 時(shí),將無法導(dǎo)致重新編譯。
colmodctr (sql server 2005)與 rowmodctr 不同,每個(gè)表列都會(huì)保存一個(gè) colmodctr 值(非永久性計(jì)算列除外)。同普通列一樣,永久性計(jì)算列擁有 colmodctr。使用 colmodctr 值,可以更細(xì)化地跟蹤表的更改。colmodctr 值對(duì)用戶不可用;僅供查詢處理器使用。
當(dāng)在表或索引視圖 t 的一個(gè)或多個(gè)列上(通過自動(dòng)統(tǒng)計(jì)功能手動(dòng)或自動(dòng))創(chuàng)建或更新統(tǒng)計(jì)時(shí),最左邊一列的 colmodctr 的快照值將保存在統(tǒng)計(jì)二進(jìn)制大對(duì)象 (stats-blob) 中。
“閾值交叉”測試中所提到的 colmodctr(current) 在查詢編譯期間進(jìn)行測試時(shí)保留在 sql server 2005 的元數(shù)據(jù)中的值。
與 rowmodctr 不同,colmodctr 的值是一個(gè)不斷遞增的序列:colmodctr 值從不被重置為 0。
不存在非永久性計(jì)算列的 colmodctr 值。其派生自參與計(jì)算的列。
使用 rowmodctr 和 colmodctr 跟蹤表和索引視圖的更改由于 rowmodctr 和 colmodctr 值用于做出重新編譯決定,因此它們的值被當(dāng)作表更改來進(jìn)行修改。在下列描述中,我們僅提到了表。但是,相同的情況也適用于索引視圖。可通過下列語句更改表:insert、delete、update、大容量插入和表截?cái)唷O铝斜矶x了修改 rowmodctr 和 colmodctr 值的方式。
| 語句 | sql server 2000 | sql server 2005 |
insert | rowmodctr += 1 | 所有 colmodctr += 1 |
delete | rowmodctr += 1 | 所有 colmodctr += 1 |
update | rowmodctr += 2 或 3。“2”的說明:1 表示刪除 + 1 表示插入。 | 如果更新針對(duì)非鍵列:colmodctr += 1 針對(duì)所有已更新的列。 如果更新針對(duì)鍵列:colmodctr += 2 針對(duì)所有列。 |
大容量插入 | 不更改。 | 與 n insert 相同。所有 colmodctr += n。(n 是大容量插入的行數(shù)。) |
表截?cái)?/p> | 不更改。 | 與 n delete 相同。所有 colmodctr += n。(n 是表的基數(shù)。) |
,歡迎訪問網(wǎng)頁設(shè)計(jì)愛好者web開發(fā)。
新聞熱點(diǎn)






疑難解答
圖片精選













