本文介紹了 sql server 2005 enterprise edition 中經(jīng)過改進(jìn)的索引視圖功能。文中對索引視圖進(jìn)行了說明介紹,并討論了可通過該功能改善性能的一些具體情況
一、索引視圖
多年以來,microsoft® sql server™ 一直支持創(chuàng)建稱為視圖的虛擬表。通常,這些視圖的主要作用是:
| • | 提供一種安全機(jī)制,將用戶限制到一個或多個基表的某個數(shù)據(jù)子集中。 |
| • | 提供一種機(jī)制,允許開發(fā)人員自定義用戶通過邏輯方式查看存儲在基表中的數(shù)據(jù)的方式。 |
通過 sql server 2000,sql server 視圖的功能得到了擴(kuò)展,實(shí)現(xiàn)了系統(tǒng)性能方面的收益。可在視圖上創(chuàng)建唯一的聚集索引及非聚集索引,來提高最復(fù)雜的查詢的數(shù)據(jù)訪問性能。在 sql server 2000 和 2005 中,具有唯一的聚集索引的視圖即為索引視圖。本文所討論的內(nèi)容適用于 sql server 2005,其中有許多內(nèi)容也適用于 sql server 2000。
從數(shù)據(jù)庫管理系統(tǒng) (dbms) 的角度看來,視圖是對數(shù)據(jù)(一種元數(shù)據(jù)類型)的一種描述。當(dāng)創(chuàng)建了一個典型視圖時,通過封裝一個 select 語句(定義一個結(jié)果集來表示為虛擬表)來定義元數(shù)據(jù)。當(dāng)在另一個查詢的 from 子句中引用視圖時,將從系統(tǒng)目錄檢索該元數(shù)據(jù),并替代該視圖的引用擴(kuò)展元數(shù)據(jù)。視圖擴(kuò)展之后,sql server 查詢優(yōu)化器會為執(zhí)行查詢編譯一個執(zhí)行計劃。查詢優(yōu)化器會搜索針對某個查詢的一組可能的執(zhí)行計劃,并根據(jù)對執(zhí)行每個查詢計劃所需的實(shí)際時間的估計,選擇所能找到的成本最低的計劃。
對于非索引視圖,解析查詢所必需的視圖部分會在運(yùn)行時被具體化。任何計算(比如:聯(lián)接或聚合)都在每個引用視圖的查詢執(zhí)行時完成1。在視圖上創(chuàng)建了唯一的聚集索引后,該視圖的結(jié)果集隨即被具體化,并保存在數(shù)據(jù)庫的物理存儲中,從而在執(zhí)行時節(jié)省了執(zhí)行這一高成本操作的開銷。
在查詢執(zhí)行中,可通過兩種方式使用索引視圖。查詢可直接引用索引視圖,或者更重要的是,如果查詢優(yōu)化器確定該視圖可替換成本最低的查詢計劃中的部分或全部查詢,那么就可以選定它。在第二種情況中,使用索引視圖替代基礎(chǔ)表及其一般索引。不必在查詢中引用視圖以使查詢優(yōu)化器在查詢執(zhí)行時使用該視圖。這使得現(xiàn)有的應(yīng)用程序可以從新創(chuàng)建的索引視圖中受益,而不必進(jìn)行更改。
注意 索引視圖是 sql server 2000 和 2005 各版本的一個功能。在 sql server 2000 和 2005 的 developer 和 enterprise 版本中,查詢處理器可使用索引視圖來解析結(jié)構(gòu)上與該視圖相匹配的查詢,即便不按名稱來引用視圖。在其他版本中,必須按名稱來引用視圖,并對視圖引用使用 noexpand 提示來查詢索引視圖的內(nèi)容。
通過索引視圖改善性能運(yùn)用索引提高查詢性能不算是一個新概念;但是,索引視圖提供了一些借助標(biāo)準(zhǔn)索引無法取得的性能收益。索引視圖可通過以下方式提高查詢性能:
| • | 可預(yù)先計算聚合并將其保存在索引中,從而在查詢執(zhí)行時,最小化高成本的計算。 |
| • | 可預(yù)先聯(lián)接各個表并保存最終獲得的數(shù)據(jù)集。 |
| • | 可保存聯(lián)接或聚合的組合。 |
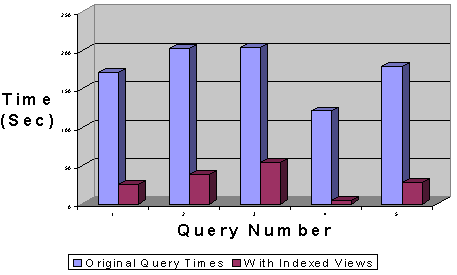
該圖說明了當(dāng)查詢優(yōu)化器使用索引視圖時,通常所能取得的性能改進(jìn)。所列舉的查詢在復(fù)雜性上有所不同(比如:聚合計算的數(shù)量、所用表的數(shù)量或謂詞的數(shù)量)并包含來自真實(shí)的生產(chǎn)環(huán)境的具有數(shù)百萬行的表。
其次,視圖上的非聚集索引可提供更好的查詢性能。與表上的非聚集索引類似,視圖上的非聚集索引可提供更多選項(xiàng),供查詢優(yōu)化器在編譯過程中選擇。例如,如果查詢包含聚集索引所未涉及的列,那么優(yōu)化器可在計劃中選擇一個或多個輔助索引,避免對索引視圖或基表進(jìn)行費(fèi)時的完全掃描。
對架構(gòu)添加索引會增加數(shù)據(jù)庫的開銷,因?yàn)樗饕枰掷m(xù)的維護(hù)。在索引數(shù)量和維護(hù)開銷間尋求適當(dāng)?shù)钠胶恻c(diǎn)時,應(yīng)謹(jǐn)慎權(quán)衡。
二、應(yīng)用索引視圖的優(yōu)點(diǎn)
在實(shí)施索引視圖前,分析數(shù)據(jù)庫工作負(fù)荷。運(yùn)用查詢及各種相關(guān)工具(比如:sql profiler)方面的知識來確定可從索引視圖獲益的查詢。頻繁發(fā)生聚合和聯(lián)接的情況最適合使用索引視圖。無論是否頻繁發(fā)生,只要某個查詢需要很長的響應(yīng)時間,同時快速獲得響應(yīng)的開銷很高,那么就適合使用索引視圖。例如,一些開發(fā)人員發(fā)現(xiàn)為高級主管們在月末運(yùn)行的報告,創(chuàng)建預(yù)先計算和存儲查詢的應(yīng)答的索引視圖很有用。
不是所有的查詢都能從索引視圖中獲益。與一般索引類似,如果未使用索引視圖,就無法從中受益。在這種情況下,不僅無法實(shí)現(xiàn)性能改善,而且會在磁盤空間、維護(hù)和優(yōu)化方面產(chǎn)生額外的成本。然而,當(dāng)使用索引視圖時,可大大改善(在數(shù)量級上)數(shù)據(jù)訪問。這是因?yàn)椴樵儍?yōu)化器使用存儲在索引視圖(大幅降低了查詢執(zhí)行的成本)中預(yù)先計算的結(jié)果。
查詢優(yōu)化器僅考慮對具有高成本的查詢使用索引視圖。從而避免出現(xiàn)這樣的情況:在查詢優(yōu)化成本高于使用索引視圖所節(jié)約的成本時嘗試匹配各種索引視圖。在成本少于 1 的查詢中很好使用索引視圖。
從實(shí)施索引視圖中獲益的應(yīng)用程序包括:
| • | 決策支持工作負(fù)荷 |
| • | 數(shù)據(jù)集市 |
| • | 數(shù)據(jù)倉庫 |
| • | 聯(lián)機(jī)分析處理 (olap) 存儲和源 |
| • | 數(shù)據(jù)挖掘工作負(fù)荷 |
從查詢類型和模式方面來看,獲益的應(yīng)用程序一般包含:
| • | 大型表的聯(lián)接和聚合 |
| • | 查詢的重復(fù)模式 |
| • | 幾組相同或重疊的列上的重復(fù)聚合 |
| • | 相同鍵上相同表的重復(fù)聯(lián)接 |
| • | 以上各項(xiàng)的組合 |
相反,執(zhí)行許多寫入操作的聯(lián)機(jī)事務(wù)處理 (oltp) 系統(tǒng)或者頻繁更新的數(shù)據(jù)庫應(yīng)用程序可能無法運(yùn)用索引視圖,因?yàn)橥瑫r更新視圖和底層基表會帶來更高的維護(hù)成本。
查詢優(yōu)化器如何使用索引視圖sql server 查詢優(yōu)化器自動決定何時對給定的查詢執(zhí)行使用索引視圖。不必在查詢中直接引用視圖以供優(yōu)化器在查詢執(zhí)行計劃中使用。所以,現(xiàn)有的應(yīng)用程序可運(yùn)用索引視圖,而不用更改應(yīng)用程序本身;只是必須創(chuàng)建索引視圖。
優(yōu)化器考慮事項(xiàng)查詢優(yōu)化器通過考慮幾個條件來決定索引視圖能否涵蓋整個或部分查詢。這些條件對應(yīng)查詢中的一個 from 子句并由下列這幾個部分組成:
| • | 查詢 from 子句中的表必須是索引視圖 from 子句中的表的超集。 | ||||||
| • | 查詢中的聯(lián)接條件必須是視圖中的聯(lián)接條件的超集。 | ||||||
| • | 查詢中的聚合列必須可從視圖中的聚合列的子集派生。 | ||||||
| • | 查詢選擇列表中的所有表達(dá)式必須可從視圖選擇列表或未包含在視圖定義中的表派生。 | ||||||
| • | 如果與其他謂詞所匹配的行的超集相匹配,那么該謂詞將歸入另一個謂詞。例如,“t.a=10”歸入“t.a=10 and t.b=20”。任何謂詞都可歸入其自身。視圖中限制表值的那部分謂詞必須歸入查詢中限制相同表的那部分謂詞。此外,必須以 sql server 可驗(yàn)證的方式實(shí)現(xiàn)這一點(diǎn)。 | ||||||
| • | 屬于視圖定義中的表的查詢搜索條件謂詞的所有列必須出現(xiàn)在下列視圖定義的一項(xiàng)或多項(xiàng)中:
情況 (1) 和 (2) 允許 sql server 對視圖的列應(yīng)用查詢謂詞,以便進(jìn)一步限制視圖的列。情況 (3) 比較特殊。在這種情況下,不需要對列進(jìn)行篩選,因此該列不必出現(xiàn)在視圖中。 |
如果查詢不止包含一個 from 子句(子查詢、派生表、union),優(yōu)化器可能選擇幾個索引視圖來處理查詢,并將它們應(yīng)用到不同 from 子句。2
本文檔的末尾提供了涉及這些情況的具體查詢。推薦的最佳實(shí)務(wù)是讓查詢優(yōu)化器決定在查詢執(zhí)行計劃中使用哪些索引(如果有的話)。
使用 noexpand 視圖提示當(dāng) sql server 處理按名稱引用視圖的查詢時,視圖的定義只有在僅引用基表時才會被正常擴(kuò)展。這個過程稱為視圖擴(kuò)展。其屬于一種宏擴(kuò)展形式。
noexpand 視圖提示可強(qiáng)制查詢優(yōu)化器將視圖視為帶有聚集索引的普通表。其可防止視圖擴(kuò)展。只有在 from 子句中直接引用索引視圖,才會應(yīng)用 noexpand 提示。例如,
select column1, column2, ...from table1, view1 with (noexpand) where ...如要確保讓 sql server 通過自己讀取視圖而不是從基表讀取數(shù)據(jù)來處理查詢,那么可使用 noexpand。如果出于某種原因,sql server 選擇了一個查詢計劃來對基表處理查詢,而您想讓其使用視圖,那么可以考慮使用 noexpand。必須在除 developer 和 enterprise 版本外的 sql server 的所有版本中使用 noexpand 來讓 sql server 直接對索引視圖處理查詢。可以看到 sql server 為計劃的圖形表達(dá)式選擇了一個使用 sql server management studio 工具的顯示預(yù)計的執(zhí)行計劃功能的語句。或者,可以看到使用 showplan_all、showplan_text 或 showplan_xml 的不同的非圖形表達(dá)式。參閱 sql sever 聯(lián)機(jī)叢書中有關(guān) showplan 的不同版本的相關(guān)討論。
使用 expand views 查詢提示處理按名稱引用視圖的查詢時,除非對視圖引用添加 noexpand 提示,否則 sql server 總會擴(kuò)展視圖。該提示會嘗試匹配索引視圖和擴(kuò)展查詢,除非在查詢末尾的一個 option 子句中指定 expand views 查詢提示。例如,假設(shè)數(shù)據(jù)庫中有一個索引視圖 view1。在下方的查詢中,根據(jù)其邏輯定義(其 create view 語句)對 view1 進(jìn)行了擴(kuò)展,然后 expand views 選項(xiàng)會阻止在計劃中使用 view1 的索引視圖來解析該查詢。
select column1, column2, ... from table1, view1 where ...
option (expand views)如要確保讓 sql server 通過從查詢所引用的基表直接訪問數(shù)據(jù)來處理該查詢,而不必訪問索引視圖,那么可使用 expand views。在某些情況下,expand 視圖有助于消除因使用索引視圖而導(dǎo)致的鎖爭用。在測試應(yīng)用程序時,noexpand 和 expand views 都可幫助用戶在使用和不使用索引視圖的情況下進(jìn)行性能評估。
三、sql server 2005 的索引視圖的新增功能
與 sql server 2000 相比,sql server 2005 包含了許多索引視圖的改進(jìn)功能。可索引的視圖組已擴(kuò)展至包含基于下列各項(xiàng)的視圖:
• 標(biāo)量聚合,包括 sum 和不帶 group by 的 count_big。
• 標(biāo)量表達(dá)式和用戶定義的功能 (udfs)。例如,給定一個表 t(a int, b int, c int) 和一個標(biāo)量 udf dbo.myudf(@x int),t 上定義的索引視圖可包含一個計算列(比如:a+b 或 dbo.myudf(a))。
• 不精確的永久性列。不精確的列是一種浮型或?qū)嵭偷牧校蛘呤且环N派生自浮型或?qū)嵭土械挠嬎懔小T?sql server 2000 中,如果不屬于索引鍵的一部分,不精確的列就可用于索引視圖的選擇列表。不精確的列不能用于視圖定義中的其他地方(比如:where 或 from 子句)。如果不精確的列永久保存在基表中,那么 sql server 2005 允許其加入鍵或視圖定義。永久性列包含常規(guī)列和標(biāo)記為 persisted 的計算列。
• 不精確的非永久性列無法加入索引或索引視圖的根本原因是:必須使數(shù)據(jù)庫脫離原計算機(jī),然后再附加到另一臺計算機(jī)。完成轉(zhuǎn)移之后,保存在索引或索引視圖中的所有計算列值在新硬件上的派生方式必須與舊硬件完全相同,精確到每個位。否則,這些索引視圖在新硬件上會遭到邏輯破壞。由于這種破壞,在新硬件上,針對索引視圖的查詢會根據(jù)計劃是否使用了索引視圖或基表來派生視圖數(shù)據(jù),返回不同的應(yīng)答。此外,無法在新計算機(jī)上正常維護(hù)索引視圖。可惜,不同計算機(jī)上的浮點(diǎn)硬件(即便采用相同制造商的相同處理器體系結(jié)構(gòu))在處理器的版本上并不總是完全相同。對于某些浮點(diǎn)值 a 和 b,固件升級可能導(dǎo)致新硬件上的 (a*b) 不同于舊硬件上的 (a*b)。例如,結(jié)果可能非常相近,但仍存在細(xì)微差別。在進(jìn)行索引之前一直保留不精確的計算值可解決這種分離/附加的不一致性問題,因?yàn)樵谶M(jìn)行索引和索引視圖的數(shù)據(jù)庫更新和維護(hù)期間,在相同的計算機(jī)上評估了所有表達(dá)式。
• 通用語言運(yùn)行時 (clr) 類型。sql server 2005 的一個主要的新功能是支持基于 clr 的用戶定義的類型 (udt) 和 udf。假如列或表達(dá)式具有確定性或是永久且精確的,或者二者兼具,那么就可在 clr udt 列或從這些列派生而來的表達(dá)式上定義索引視圖。不能在索引視圖上使用 clr 用戶定義的聚合。
優(yōu)化器匹配查詢和索引視圖(使之可在查詢計劃中使用)的功能經(jīng)擴(kuò)展包含:
• 新的表達(dá)式類型,位于查詢或視圖的 select 列表或條件中,涉及:
• 標(biāo)量表達(dá)式(比如 (a+b)/2)。
• 標(biāo)量聚合。
• 標(biāo)量 udf。
• 間隔歸入。優(yōu)化器可檢測索引視圖定義中的間隔條件是否覆蓋或“歸入”查詢中的間隔條件。例如,優(yōu)化器可確定“a>10 and a<20”覆蓋“a>12 and a<18”。
• 表達(dá)式等價。某些表達(dá)式雖然在語法上有所不同,但最終的結(jié)果卻相同,那么可以將其視為等價。例如,“a=b and c<>10”與“10<>c and b=a”等價。
另外,如果數(shù)據(jù)庫中存在大量索引視圖,那么對比在其上定義視圖的表的編譯性能,sql server 2005 通常要比 sql server 2000 快很多。.
四、設(shè)計注意事項(xiàng)
對數(shù)據(jù)庫系統(tǒng)確定一組適當(dāng)?shù)乃饕赡芎軓?fù)雜。如果在設(shè)計一般索引時需要考慮眾多可能性,那么對架構(gòu)添加索引視圖會大幅提高設(shè)計和潛在結(jié)果的復(fù)雜性。例如,索引視圖可用于:
• 查詢中引用的表的任何子集。
• 該表子集的查詢中的條件的任何子集。
• 組合的列。
• 聚合函數(shù)(比如:sum)。
應(yīng)同時設(shè)計表和索引視圖上的索引,以便從每個構(gòu)造中獲得最佳結(jié)果。由于索引和索引視圖對給定查詢可能都很有用,因此分開設(shè)計會導(dǎo)致多余的建議,從而產(chǎn)生較高的存儲和維護(hù)開銷。優(yōu)化數(shù)據(jù)庫的物理設(shè)計時,必須權(quán)衡一組不同的查詢和數(shù)據(jù)庫系統(tǒng)必須支持的更新的性能要求。所以,對索引視圖確定一項(xiàng)適當(dāng)?shù)奈锢碓O(shè)計是一種富有挑戰(zhàn)性的任務(wù),應(yīng)盡可能使用數(shù)據(jù)庫優(yōu)化顧問 (database tuning advisor)。
如果為建立一個特殊的查詢,查詢優(yōu)化器考慮了許多索引視圖,那么查詢優(yōu)化成本就會顯著增加。查詢優(yōu)化器可能會考慮在查詢中的表的任何子集上定義的所有索引視圖。在拒絕視圖之前,必須調(diào)查每個視圖以便進(jìn)行替換。這可能要花一些時間,尤其當(dāng)給定查詢存在數(shù)百個這類視圖時。
在其上創(chuàng)建一個唯一的聚集索引之前,視圖必須滿足幾項(xiàng)要求。在設(shè)計階段,考慮這些要求:
• 視圖以及視圖中引用的所有表必須在相同的數(shù)據(jù)庫中,并具有相同的所有者。
• 索引視圖不必包含查詢中引用的供優(yōu)化器使用的所有表。
• 在視圖上創(chuàng)建任何其他的索引之前,必須先創(chuàng)建一個唯一的聚集索引。
• 在創(chuàng)建基表、視圖和索引時,以及基表和視圖中的數(shù)據(jù)被修改時,必須正確設(shè)置某些 set 選項(xiàng)(在本文檔后面所有詳述)。此外,除非這些 set 選項(xiàng)正確無誤,否則查詢優(yōu)化器不會考慮索引視圖。
• 必須使用架構(gòu)綁定創(chuàng)建視圖,并且還必須通過 schemabinding 選項(xiàng)創(chuàng)建該視圖中引用的任何用戶定義的函數(shù)。
• 需要額外的磁盤空間來保存索引視圖所定義的數(shù)據(jù)。
設(shè)計方針
設(shè)計索引視圖時考慮這些指導(dǎo)方針:
| • | 設(shè)計可供幾個查詢或多項(xiàng)操作使用的索引視圖。 例如,包含列的 sum 和 count_big 的索引視圖可供包含函數(shù) sum、count、count_big 或 avg 的查詢使用。查詢的速度會更快,因?yàn)橹恍鑼σ晥D中少量的行進(jìn)行檢索,而不必檢索基表中所有的行,而且執(zhí)行 avg 函數(shù)所需的一部分計算已經(jīng)完成。 | ||||
| • | 使索引鍵保持簡潔。 通過在索引鍵中盡可能使用最少的列和字節(jié),可對索引視圖的列實(shí)現(xiàn)更高效的訪問,因?yàn)樗饕晥D的列更窄,鍵比較的速度較更寬的鍵快一些。另外,在索引視圖上定義的每個非聚集索引中,聚集索引鍵都被用作行定位器。較大的索引鍵的成本隨視圖上非聚集索引的數(shù)量成比例增長。 | ||||
| • | 考慮最終索引視圖的大小。 對于純聚合,如果索引視圖的大小與原始表的大小不相上下,可能就不會實(shí)現(xiàn)巨大的性能改善。 | ||||
| • | 設(shè)計多個較小的索引視圖來局部加速過程。 可能無法總對整個查詢設(shè)計一個索引視圖。如要怎么做,考慮創(chuàng)建若干個索引視圖,各執(zhí)行部分查詢。 考慮這幾個例子:
|
數(shù)據(jù)庫優(yōu)化顧問 (dta3) 是 sql server 2005 的一項(xiàng)功能,可幫助管理員優(yōu)化物理數(shù)據(jù)庫設(shè)計。除了建議使用基表上的索引以及表和索引分區(qū)策略外,dta 還推薦使用索引視圖。使用 dta 可加強(qiáng)管理員確定索引、索引視圖和分區(qū)策略(可優(yōu)化對數(shù)據(jù)庫執(zhí)行的查詢的典型組合的性能)的組合的能力。dta 會向用戶推薦廣泛的索引視圖。其中包括運(yùn)用 sql server 2005 的索引視圖的新功能(在“sql server 2005 的索引視圖有哪些新增功能?”一節(jié)有所描述)的索引視圖。dta 并沒有排除讓數(shù)據(jù)庫管理在設(shè)計物理存儲結(jié)構(gòu)時做出恰當(dāng)判斷的需要。但是,它可以簡化物理數(shù)據(jù)庫的設(shè)計過程。dta 通過推薦一組假定的索引,索引視圖和分區(qū)結(jié)果,與基于成本的查詢優(yōu)化器協(xié)同工作。dta 使用優(yōu)化器來估計當(dāng)使用和不使用這些結(jié)構(gòu)時的工作負(fù)荷成本,并推薦可提供較低的總成本的結(jié)構(gòu)。
因?yàn)閿?shù)據(jù)庫優(yōu)化顧問強(qiáng)制執(zhí)行所有必須的 set 選項(xiàng)(確保結(jié)果集正確無誤),所以將成功完成索引視圖的創(chuàng)建。然而,如果未能按要求設(shè)置選項(xiàng),用戶的應(yīng)用程序可能無法運(yùn)用這些視圖。如果未按要求指定 set 選項(xiàng),對加入索引視圖定義的表執(zhí)行的插入、更新或刪除操作就有可能失敗。
更新數(shù)據(jù)時索引視圖會有什么變化?與其他任何索引一樣,當(dāng)基表數(shù)據(jù)變化時,sql server 會自動維護(hù)索引視圖。對于一般索引,每個索引都直接與一個表相關(guān)聯(lián)。隨著在基礎(chǔ)表上執(zhí)行每一項(xiàng) insert、update 或 delete 操作,索引將被相應(yīng)地更新,從而使保存在索引中的值總是與表保持一致。
索引視圖也得到相同的維護(hù);但是,如果視圖引用了若干個表,那么更新任何一個表都需要更新索引視圖。不同于一般索引,在任何參與的表中插入一行都可能導(dǎo)致索引視圖中發(fā)生多行更改。這是因?yàn)樗迦氲男锌赡芘c另一個表的多個行相聯(lián)接。更新和刪除行的情況也一樣。因此,索引視圖的維護(hù)成本可能比維護(hù)表上的索引更高。相反,維護(hù)具有高選擇性條件的索引視圖的成本可能要比維護(hù)表上的索引低得多,因?yàn)槎鄶?shù)對視圖所引用的基表的插入、刪除和更新操作不會影響視圖。不用訪問其他數(shù)據(jù)庫數(shù)據(jù)就可為索引視圖篩選掉這些操作。
在 sql server 中,可更新某些視圖。當(dāng)某個視圖可更新時,將使用 insert、update 和 delete 語句通過視圖直接修改底層基表。在視圖上創(chuàng)建索引不會阻止視圖的更新。索引視圖的更新確實(shí)會導(dǎo)致視圖下基表的更新。這些更新會作為索引視圖維護(hù)的一部分自動傳播回索引視圖。有關(guān)可更新的視圖的詳細(xì)信息,參閱面向 sql server 2005 的 sql server 聯(lián)機(jī)叢書中的“通過視圖修改數(shù)據(jù)”。
維護(hù)成本注意事項(xiàng)設(shè)計索引視圖時應(yīng)考慮下面這幾點(diǎn):
| • | 索引視圖的數(shù)據(jù)庫需要附加存儲。索引視圖的結(jié)果集在物理上通過與典型表存儲相似的方式保留在數(shù)據(jù)庫中。 |
| • | sql server 會自動維護(hù)視圖;因此,對定義了視圖的基表進(jìn)行的任何更改都可能引發(fā)對索引視圖進(jìn)行一項(xiàng)或多項(xiàng)更改。所以,將產(chǎn)生額外的維護(hù)開銷。 |
視圖所獲得的凈性能提升為其所實(shí)現(xiàn)的總查詢執(zhí)行成本節(jié)約與存儲和維護(hù)成本的差值。
比較容易獲得接近于視圖所需的存儲。通過 sql server management studio 工具——顯示預(yù)計的執(zhí)行計劃,評估視圖定義所封裝的 select 語句。該工具將生成查詢所返回的行數(shù)和行大小的近似值。通過將這兩個值相乘,就可以獲得接近于可能的視圖大小;但是,只是近似。只有在視圖定義中執(zhí)行查詢或在視圖上創(chuàng)建索引,才能確定視圖上索引的實(shí)際大小。
從 sql server 所執(zhí)行的自動維護(hù)注意事項(xiàng)的角度來看,顯示預(yù)計的執(zhí)行計劃功能可能會讓用戶在一定程度上了解這一開銷的影響。如果通過 sql server management studio 評估修改視圖的語句(視圖上的 update、基表中的 insert),對該語句顯示的執(zhí)行計劃將包括該語句的維護(hù)操作。如果就該操作在生產(chǎn)環(huán)境中所要執(zhí)行的次數(shù)考慮該成本,那么可能會產(chǎn)生視圖維護(hù)成本。
通常建議盡可能對視圖或其底下的基表成批(而非單獨(dú))執(zhí)行任何修改或更新操作。這樣就會降低視圖維護(hù)開銷。
五、創(chuàng)建索引視圖
創(chuàng)建索引視圖所需的步驟對于視圖的成功執(zhí)行至關(guān)重要。
1. | 針對將在視圖中引用的所有現(xiàn)有表,確認(rèn) ansi_nulls 的設(shè)置正確無誤。 |
2. | 創(chuàng)建任何新表之前,確認(rèn)對下表所示的當(dāng)前會話正確設(shè)置了 ansi_nulls。 |
3. | 創(chuàng)建任何新表之前,確認(rèn)對下表所示的當(dāng)前會話正確設(shè)置了 ansi_nulls 和 quoted_identifier。 |
4. | 確認(rèn)視圖定義具有確定性。 |
5. | 使用 with schemabinding 選項(xiàng)創(chuàng)建視圖。 |
6. | 在視圖上創(chuàng)建唯一的聚集索引之前,確認(rèn)會話的 set 選項(xiàng)的設(shè)置正確無誤,如下圖所示。 |
7. | 在視圖上創(chuàng)建唯一的聚集索引。 |
8. | 可用 objectproperty 函數(shù)檢查現(xiàn)有表或視圖上 ansi_nulls 和 quoted_identifier 的值。 |
如果在執(zhí)行查詢時對當(dāng)前會話啟用了不同的 set 選項(xiàng),評估相同的表達(dá)式可在 sql server 2005 中產(chǎn)生不同的結(jié)果。例如,set 選項(xiàng) concat_null_yields_null 被設(shè)為 on 后,表達(dá)式 'abc' + null 會返回值 null。但當(dāng) concat_null_yieds_null 被設(shè)為 off 后,相同的表達(dá)式會生成 'abc'。對于當(dāng)前會話和視圖所引用的對象,索引視圖需要幾個 set 選項(xiàng)的固定值,以確保正確維護(hù)視圖并返回一致的結(jié)果。
只要存在下列條件,就必須按下表中“必需的值”一列所示的值對當(dāng)前會話設(shè)置 set 選項(xiàng):
| • | 創(chuàng)建了索引視圖。 | |||||||||||||||||||||||||||||||||||
| • | 在加入索引視圖的任何表上執(zhí)行了任何 insert、update 或 delete 操作。 | |||||||||||||||||||||||||||||||||||
| • | 查詢優(yōu)化器用索引視圖生成查詢計劃。
|
arithabort4 選項(xiàng)必需被設(shè)為 on,以便使當(dāng)前會話創(chuàng)建索引視圖,但是在 sql server 2005 中,只要 ansi_warnings 的值為 on,該選項(xiàng)就會自動被設(shè)為 on,所以不必對其進(jìn)行設(shè)置。如果使用 ole db 或 odbc 服務(wù)器連接,只需修改 arithabort 設(shè)置的值。必須使用 sp_configure 在服務(wù)器級別或使用 set 命令從應(yīng)用程序正確設(shè)置所有 db lib 值。有關(guān) set 選項(xiàng)的詳細(xì)信息,參閱 sql server 聯(lián)機(jī)叢書中的“使用選項(xiàng)”。
使用具有確定性的功能索引視圖的定義必須具有確定性。如果選擇列表中的所有表達(dá)式以及 where 和 group by 子句都具有確定性,那么視圖就具有確定性。具有確定性的表達(dá)式總是在通過一組特定的輸入值對其進(jìn)行評估時,返回相同的結(jié)果。只有具有確定性的函數(shù)才會加入具有確定性的表達(dá)式。例如,dateadd 函數(shù)具有確定性,因?yàn)閷τ谌魏谓o定的一組參數(shù)值,該函數(shù)總對它的三個參數(shù)返回相同的結(jié)果。getdate 不具有確定性,因?yàn)樗傉{(diào)用相同的參數(shù),而其返回的值在每次執(zhí)行時都會發(fā)生變化。詳細(xì)信息,參閱面向 sql server 2005 的 sql server 聯(lián)機(jī)叢書中的“具有和不具有確定性的函數(shù)”。
即使某個表達(dá)式具有確定性(如果其包含浮點(diǎn)表達(dá)式),確切的結(jié)果可能依處理器體系結(jié)構(gòu)或微碼的版本而定。為了在計算機(jī)間遷移數(shù)據(jù)庫時確保 sql server 2005 中數(shù)據(jù)的完整性,這種表達(dá)式只能作為索引視圖的非鍵列加入。不含浮點(diǎn)表達(dá)式的具有確定性的表達(dá)式被認(rèn)為是精確的。只有永久和/或精確的具有確定性的表達(dá)式才可加入鍵列以及索引視圖的 where 或 group by 子句。永久性表達(dá)式是對已保存列的引用,包括一般列和標(biāo)為 persisted 的計算列。
用 columnproperty 函數(shù)和 isdeterministic 屬性確定視圖列是否具有確定性。用 columnproperty 函數(shù)和 isprecise 屬性確定帶有 schemabinding 的視圖中的具有確定性的列是精確的。如果屬性為 true,columnproperty 將返回 1;如為 false,則返回 0;而如果為 null,則表示無效輸入。例如,在此腳本中
create table t(a int, b real, c as getdate(), d as a+b)
create view vt with schemabinding as select a, b, c, d from dbo.t
select object_id('vt'), columnproperty(object_id('vt'),'b','isprecise')select 對 isprecise 返回 0,因?yàn)?b 列為實(shí)型。可通過 columnproperty 做一些實(shí)驗(yàn),確認(rèn) t 的其他列是否具有確定性并是精確的。
其他要求可索引的視圖集合是可能的視圖集合的一個子集。任何可索引的視圖在有或沒有索引的情況下都可存在。
除了設(shè)計方針(“使用 set 選項(xiàng)獲得一致的結(jié)果”和“使用具有確定性的函數(shù)”這兩節(jié))中所列的要求外,還必須滿足下列要求,以便在視圖上創(chuàng)建唯一的聚集索引。
有關(guān)基表的要求| • | 視圖所引用的基表必須具有在創(chuàng)建表時所設(shè)的 set 選項(xiàng) ansi_nulls 的正確的值。可用 objectproperty 函數(shù)檢查現(xiàn)有表上的 ansi_nulls 的值。 |
| • | 必須使用 with schemabinding 選項(xiàng)創(chuàng)建視圖所引用的用戶定義的函數(shù)。 |
| • | 必須使用 with schemabinding 選項(xiàng)創(chuàng)建視圖。 |
| • | 必須由使用雙結(jié)構(gòu)名稱 (schemaname.tablename) 的視圖引用表。 |
| • | 必須由使用雙結(jié)構(gòu)名稱 (schemaname.functionname) 的視圖引用用戶定義的函數(shù)。 |
| • | 必須正確設(shè)置 set 選項(xiàng) ansi_nulls 和 quoted_identifier。 |
如要在 sql server 2005 中的視圖上創(chuàng)建一個索引,相應(yīng)的視圖定義必須包含:
any、not any | openrowset、openquery、opendatasource |
不精確的(浮型、實(shí)型)值上的算術(shù) | openxml |
compute、compute by | order by |
convert 生成一個不精確的結(jié)果 | outer 聯(lián)接 |
count(*) | 引用帶有一個已禁用的聚集索引的基表 |
group by all | 引用不同數(shù)據(jù)庫中的表或函數(shù) |
派生的表(from 列表中的子查詢) | 引用另一個視圖 |
distinct | rowset 函數(shù) |
exists、not exists | 自聯(lián)接 |
聚合結(jié)果(比如:sum(x)+sum(x))上的表達(dá)式 | stdev、stdevp、var、varp、avg |
全文謂詞 (contains、freetext、containstable、freetexttable) | 子查詢 |
不精確的常量(比如:2.34e5) | 可為空的表達(dá)式上的 sum |
內(nèi)嵌或表值函數(shù) | 表提示(比如:nolock) |
min、max | text、ntext、image、filestream 或 xml 列 |
不具有確定性的表達(dá)式 | top |
非 unicode 排序 | union |
sql server 2005 可檢測到的矛盾情況表示視圖將為空(比如,當(dāng) 0=1 及 ...) |
注意 索引視圖可能包含浮型和實(shí)型列;但是,如果這類列為非永久性的計算列,則不能包含在聚集索引鍵中。
group by 限制如果存在 group by,view 定義為:
| • | 一定包含 count_big(*)。 |
| • | 一定不包含 having、cube、rollup 或 grouping()。 |
這些限制僅適用于索引視圖定義。即便不能滿足上述 group by 限制,查詢也可以在其執(zhí)行計劃中使用索引視圖。
有關(guān)索引的要求| • | 執(zhí)行 create index 語句的用戶必須是視圖所有者。 |
| • | 如果視圖定義包含 group by 子句,唯一的聚集索引的鍵只能引用 group by 子句所指定的列。 |
| • | 一定不能在啟用 ignore_dup_key 選項(xiàng)的情況下創(chuàng)建索引。 |
六、示例
本節(jié)中的例子闡述了如何結(jié)合兩類主要的查詢使用索引視圖:聚合和聯(lián)接。同時,說明了查詢優(yōu)化器在確定某個索引視圖是否適用時所用的條件。有關(guān)完整的條件列表的信息,參閱“查詢優(yōu)化器如何使用索引視圖”。
這些查詢基于 adventureworks 中的表。adventureworks 是 sql server 2005 所提供的示例數(shù)據(jù)庫,并可作為寫入方式來執(zhí)行。在創(chuàng)建視圖前后,用戶可能想用 sql server management studio 中顯示預(yù)計的執(zhí)行計劃工具,來查看查詢優(yōu)化器所選擇的計劃。雖然這些例子說明了優(yōu)化器選擇低成本執(zhí)行計劃的方式,但是 adventureworks 示例由于太小而無法顯示出性能方面的提升。
在開始運(yùn)用這些示例之前,確保通過運(yùn)行下列命令對會話設(shè)置正確的選項(xiàng):
設(shè)置
set ansi_nulls on
set ansi_padding on
set ansi_warnings on
set concat_null_yields_null on
set numeric_roundabort off
set quoted_identifier on
set arithabort on下列查詢顯示了兩種方法用于從 sales.salesorderdetail 表返回具有最大總折扣的五個產(chǎn)品。
查詢 1
select top 5 productid, sum(unitprice*orderqty) -
sum(unitprice*orderqty*(1.00-unitpricediscount)) as rebate
from sales.salesorderdetail
group by productid
order by rebate desc查詢 2
select top 5 productid,
sum(unitprice*orderqty*unitpricediscount) as rebate
from sales.salesorderdetail
group by productid
order by rebate desc查詢優(yōu)化器所選的執(zhí)行計劃包含:
| • | 一個聚集索引掃描,位于估計行數(shù)為 121,317 的 sales.salesorderdetail 表上。 |
| • | 一個哈希匹配/聚合操作符,用于將所選的行放入基于 group by 列的哈希表,并計算每行的 sum 聚合。 |
| • | 一個 top 5 分類操作符,基于 order by 子句。 |
視圖 1
添加包含 rebate 列所需聚合的索引視圖將更改“查詢 1”的查詢執(zhí)行計劃。在大型表(含數(shù)百萬行)上,查詢的性能也會得到大幅提升。
create view vdiscount1 with schemabinding as
select sum(unitprice*orderqty) as sumprice,
sum(unitprice*orderqty*(1.00-unitpricediscount)) as sumdiscountprice,
count_big(*) as count, productid
from sales.salesorderdetail
group by productid
go
create unique clustered index vdiscountind on vdiscount1 (productid)第一個查詢的執(zhí)行計劃顯示 vdiscount1 視圖被優(yōu)化器所用。然而,該視圖將不被第二個查詢所用,因?yàn)槠洳话?sum(unitprice*orderqty*unitpricediscount) 聚合。可再創(chuàng)建一個索引視圖,來同時應(yīng)付這兩個查詢。
視圖 2
create view vdiscount2 with schemabinding as
select sum(unitprice*orderqty)as sumprice,
sum(unitprice*orderqty*(1.00-unitpricediscount))as sumdiscountprice,
sum(unitprice*orderqty*unitpricediscount)as sumdiscountprice2,
count_big(*) as count, productid
from sales.salesorderdetail
group by productid
go
create unique clustered index vdiscountind on vdiscount2 (productid)使用這個索引視圖,在丟棄 vdiscount1 后,這兩個查詢的查詢執(zhí)行計劃現(xiàn)在包含:
| • | 一個聚集索引掃描,位于估計行數(shù)為 266 的 vdiscount2 視圖上 |
| • | 一個 top 5 分類函數(shù),基于 order by 子句 |
查詢優(yōu)化器選擇了該視圖,因?yàn)殡m然沒有在查詢中引用該視圖,但其提供了最低的執(zhí)行成本。
查詢 3
“查詢 3”與上述查詢類似,但 productid 被列 salesorderid (未包含在視圖定義中)所替換。這違反了條件:視圖定義中表上的選擇列表中的所有表達(dá)式必須派生自視圖選擇列表,以便使用查詢計劃中的索引視圖。
select top 3 salesorderid,
sum(unitprice*orderqty*unitpricediscount) orderrebate
from sales.salesorderdetail
group by salesorderid
order by orderrebate desc必須用一個單獨(dú)的索引視圖來應(yīng)付該查詢。可修改 vdiscount2 以包含 salesorderid;但是,結(jié)果視圖將和原始表包含同樣多的行,并不會通過使用基表提高性能。
查詢 4
該查詢可生成每個產(chǎn)品的平均價格。
select p.name, od.productid,
avg(od.unitprice*(1.00-od.unitpricediscount)) as avgprice,
sum(od.orderqty) as units
from sales.salesorderdetail as od, production.product as p
where od.productid=p.productid
group by p.name, od.productid復(fù)雜的聚合(比如:stdev、variance、avg)不能包含在索引視圖的定義中。然而,通過包含(經(jīng)組合)執(zhí)行復(fù)雜聚合的一些簡單的聚合函數(shù),索引視圖可用以執(zhí)行含 avg 的查詢。
視圖 3
該索引視圖包含執(zhí)行 avg 函數(shù)所需的簡單聚合函數(shù)。在創(chuàng)建“視圖 3”后執(zhí)行“查詢 4”時,執(zhí)行計劃將顯示所用的視圖。優(yōu)化器可從視圖的簡單聚合列 price 和 count 派生 avg 表達(dá)式。
create view view3 with schemabinding as
select productid, sum(unitprice*(1.00-unitpricediscount)) as price,
count_big(*) as count, sum(orderqty) as units
from sales.salesorderdetail
group by productid
go
create unique clustered index iv3 on view3 (productid)查詢 5
該查詢與“查詢 4”相同,但包含一個附加的搜索條件。即使附加的搜索條件只從未包含在視圖定義中的表引用列,“視圖 3”也將作用于該查詢。
select p.name, od.productid,
avg(od.unitprice*(1.00-unitpricediscount)) as avgprice,
sum(od.orderqty) as units
from sales.salesorderdetail as od, production.product as p
where od.productid=p.productid and p.name like '%red%'
group by p.name, od.productid查詢 6
查詢優(yōu)化器無法對該查詢使用“視圖 3”。添加的搜索條件 od.unitprice>10 包含來自視圖定義中表的列,但該列不顯示在 group by 列表中,而搜索謂詞也不顯示在視圖定義中。
select p.name, od.productid,
avg(od.unitprice*(1.00-unitpricediscount)) as avgprice,
sum(od.orderqty) as units
from sales.salesorderdetail as od, production.product as p
where od.productid=p.productid and p.name like '%red%'
group by p.name, od.productid查詢 7
相反,查詢優(yōu)化器可對“查詢 7”使用“視圖 3”,因?yàn)樾碌乃阉鳁l件 od.productid in (1,2,13,41) 中定義的列包含在視圖定義的 group by 子句中。
select p.name, od.productid,
avg(od.unitprice*(1.00-unitpricediscount)) as avgprice,
sum(od.orderqty) as units
from sales.salesorderdetail as od, production.product as p
where od.productid = p.productid and od.unitprice > 10
group by p.name, od.productid視圖 4
通過包含視圖定義中的 sumprice 和 count 列以便計算查詢中的 avg,該視圖將滿足“查詢 6”的條件。
create view view4 with schemabinding as
select p.name, od.productid,
sum(od.unitprice*(1.00-unitpricediscount)) as sumprice,
sum(od.orderqty) as units, count_big(*) as count
from sales.salesorderdetail as od, production.product as p
where od.productid = p.productid and od.unitprice > 10
group by p.name, od.productid
go
create unique clustered index vdiscountind on view4 (name, productid)查詢 8
“視圖 4”上相同的索引也將用于在其中添加對表 sales.salesorderheader 的聯(lián)接的查詢。該查詢滿足條件:查詢 from 子句中所列的表是索引視圖的 from 子句中的表的超集。
select p.name, od.productid,
avg(od.unitprice*(1.00-unitpricediscount)) as avgprice,
sum(od.orderqty) as units
from sales.salesorderdetail as od, production.product as p,
sales.salesorderheader as o
where od.productid = p.productid and o.salesorderid = od.salesorderid
and od.unitprice > 10
group by p.name, od.productid最后兩個查詢在“查詢 8”的基礎(chǔ)上進(jìn)行了修改。每個修改后的查詢都違反了優(yōu)化器的條件之一,并且不同于“查詢 8”,無法使用“視圖 4”。
查詢 8a
“查詢 8a”(q8a) 無法使用索引視圖,因?yàn)?where 子句無法將視圖定義中的 unitprice > 10 與查詢中的 unitprice > 25 相匹配,而且 unitprice 未出現(xiàn)在視圖中。查詢搜索條件謂詞必須是視圖定義中的搜索條件謂詞的超集。
select p.name, od.productid, avg(od.unitprice*(1.00-unitpricediscount))
avgprice, sum(od.orderqty) as units
from sales.salesorderdetail as od, production.product as p,
sales.salesorderheader as o
where od.productid = p.productid and o.salesorderid = od.salesorderid
and od.unitprice > 25
group by p.name, od.productid查詢 8b
注意,表 sales.salesorderheader 不加入索引視圖 v4 定義。盡管這樣,在該表上添加一個謂詞將不允許使用索引視圖,因?yàn)樗砑拥闹^詞可能會更改或消除加入下方“查詢 8b”所示的聚合的其他行。
select p.name, od.productid, avg(od.unitprice*(1.00-unitpricediscount))
as avgprice, sum(od.orderqty) as units
from sales.salesorderdetail as od, production.product as p,
sales.salesorderheader as o
where od.productid = p.productid and o.salesorderid = od.salesorderid
and od.unitprice > 10 and o.orderdate > '20040728'
group by p.name, od.productid視圖 4a
“視圖 4a”通過將 unitprice 列包含在選擇列表和 group by 子句中,擴(kuò)展了“視圖 4”。“查詢 8a”可使用“視圖 4a”,因?yàn)閷⑦M(jìn)一步篩選 unitprice 值(已知大于 10)以便只留下大于 25 的值。以下是間隔歸入的一個例子。
create view view4a with schemabinding as
select p.name, od.productid, od.unitprice,
sum(od.unitprice*(1.00-unitpricediscount)) as sumprice,
sum(od.orderqty) as units, count_big(*) as count
from sales.salesorderdetail as od, production.product as p
where od.productid = p.productid and od.unitprice > 10
group by p.name, od.productid, od.unitprice
go
create unique clustered index vdiscountind
on view4a (name, productid, unitprice)視圖 5
“視圖 5”在其選擇和 group by 列表中包含一個表達(dá)式。請注意,linetotal 是一個計算列,因此本身是一個表達(dá)式。反過來,該表達(dá)式嵌套在對 floor 函數(shù)的調(diào)用中。
create view view5 with schemabinding as
select floor(linetotal) floortotal, count_big(*) c
from sales.salesorderdetail
group by floor(linetotal)
go
create unique clustered index iview5 on view5(floortotal)查詢 9
“查詢 9”在其選擇和 group by 列表中包含表達(dá)式 floor(linetotal)。通過對 sql server 2005 中表達(dá)式的視圖匹配的新擴(kuò)展,該查詢使用“視圖 5”上的索引。
select top 5 floor(linetotal), count(*)
from sales.salesorderdetail
group by floor(linetotal)
order by count(*) desc視圖 6
“視圖 6”存儲月末三天中有關(guān)線項(xiàng)目的信息。這樣可將這些行聚集在少量頁面上,從而可以迅速應(yīng)對這些天里對 sales.salesorderdetail 的查詢。
create view view6 with schemabinding as
select salesorderid, salesorderdetailid, carriertrackingnumber, orderqty,
productid, specialofferid, unitprice, unitpricediscount, rowguid,
modifieddate
from sales.salesorderdetail
where modifieddate in ( convert(datetime, '2004-07-31', 120),
convert(datetime, '2004-07-30', 120),
convert(datetime, '2004-07-29', 120) )
go
create unique clustered index vendjulyo4ind
on view6(salesorderid, salesorderdetailid)
go查詢 10
下面的查詢可匹配“視圖 6”,同時系統(tǒng)可生成一個計劃,用于掃描視圖上的 vendjuly04ind 索引,但不掃描整個 sales.salesorderdetail 表。此查詢還說明了表達(dá)式等價(由于查詢中日期的順序不同于視圖,而且數(shù)據(jù)格式也不同)和謂詞歸入(由于查詢要求將結(jié)果的子集保存在視圖中)。
select h.*, salesorderdetailid, carriertrackingnumber, orderqty,
productid, specialofferid, unitprice, unitpricediscount, d.rowguid,
d.modifieddate
from sales.salesorderheader as h, sales.salesorderdetail as d
where (d.modifieddate = '20040729' or d.modifieddate = '20040730')
and d.salesorderid=h.salesorderid視圖 7
開發(fā)人員有時還會發(fā)現(xiàn)使用索引視圖強(qiáng)制專門的完整性約束很方便。例如,可通過索引視圖強(qiáng)制約束:“除非列中存在多個 0 值,否則表 t 的列 a 就是唯一的”。下方索引視圖“視圖 7”就強(qiáng)制了這一約束。如果運(yùn)行下面的腳本,其將成功運(yùn)行直至最終的插入操作。該語句被禁止,因?yàn)槠涮砑恿艘粋€非零重復(fù)值。
use tempdb
go
create table t(a int)
go
create view view7 with schemabinding
as select a
from dbo.t
where a <> 0
go
create unique clustered index iv on view7(a)
go
-- legal:
insert into t values(1)
insert into t values(2)
insert into t values(0)
insert into t values(0) -- duplicate 0
-- dissalowed:
insert into t values(2)七、有關(guān)索引視圖的常見問題
問:為何對可創(chuàng)建索引的視圖類型存在限制?
答:為了確保在邏輯上可對視圖進(jìn)行增量維護(hù),限制創(chuàng)建維護(hù)成本較高的視圖,并限制 sql server 實(shí)施的復(fù)雜性。較大的視圖集不具有確定性并與內(nèi)容相關(guān);其內(nèi)容的“更改”獨(dú)立于 dml 操作。無法對這些內(nèi)容進(jìn)行索引。在其定義中調(diào)用 getdate 或 suser_sname 的任何視圖就屬于這類視圖。
問:視圖上的第一個索引為何必須為 clustered 和 unique?
答:必須為 unique 以便在維護(hù)索引視圖期間,輕松地按鍵值查找視圖中的記錄,并阻止創(chuàng)建帶有重復(fù)項(xiàng)目的視圖(要求維護(hù)特殊的邏輯)。必須為 clustered,因?yàn)橹挥芯奂饕拍茉趶?qiáng)制唯一性的同時存儲行。
問:為何查詢優(yōu)化器不選取我的索引視圖用于查詢計劃?
答:優(yōu)化器不選取索引視圖主要有三種原因:
(1) 使用 sql server enterprise 或 developer 版本之外的其他版本。只有 enterprise 和 developer 版本才支持自動的查詢對索引視圖匹配。按名稱引用索引視圖并包含 noexpand 提示,讓查詢處理器使用所有其他版本中的索引視圖。
(2) 使用索引視圖的成本可能超出從基表獲取數(shù)據(jù)的成本,或者查詢過于簡單,使得針對基表的查詢的速度既快又容易查找。當(dāng)在較小的表上定義索引視圖時,經(jīng)常會發(fā)生這種情況。如要強(qiáng)制查詢處理器使用索引視圖,那么可使用 noexpand 提示。如果最初不通過顯式的方式引用視圖,這樣做就可能要求重新編寫查詢。您可獲得帶有 noexpand 的查詢的實(shí)際成本,并將之與不引用該視圖的查詢計劃的實(shí)際成本相比較。如果兩者的成本相近,那么您就可以認(rèn)定用不用索引視圖都不重要。
(3) 查詢優(yōu)化器不將查詢與索引視圖相匹配。重新檢查視圖和查詢的定義,確保兩者在結(jié)構(gòu)上可相匹配。casts、converts 以及其他在邏輯上不會更改查詢結(jié)果的表達(dá)式可能會阻止匹配。另外,表達(dá)式規(guī)范化和等價以及 sql server 執(zhí)行的歸入測試方面存在一些限制。可能無法顯示某些等價表達(dá)式是相同的,或者邏輯上被其他表達(dá)式歸入的表達(dá)式被真正歸入,因此可能會錯失匹配。
問:我每周更新一次數(shù)據(jù)倉庫。索引視圖使查詢速度大大提升,卻降低了每周更新的速度?該怎么辦呢?
答:可以考慮在每周更新前丟棄索引視圖,更新完后再重新創(chuàng)建。
問:我的視圖存在重復(fù)項(xiàng)目,而我確實(shí)想對其進(jìn)行維護(hù)。該怎么辦呢?
答:可以考慮創(chuàng)建一個視圖,按您所要的視圖中的所有列和表達(dá)式進(jìn)行分組,并添加一個 count_big(*) 列,然后在組合的列上創(chuàng)建一個唯一的聚集索引。分組過程可確保唯一性。雖然不是完全相同的視圖,但可以滿足您的需要。
問:我在一個視圖上定義了另一個視圖。sql server 不讓我索引頂級視圖。該怎么辦呢?
答:可以考慮手動將嵌套視圖的定義擴(kuò)展到頂級視圖,然后對其進(jìn)行索引(索引最低層的視圖,或者不索引該視圖)。
問:為何一定要對索引視圖定義 with schemabinding?
答:為了
•
使用 schemaname.objectname 明確識別視圖所引用的所有對象,而不管是哪個用戶訪問該視圖,同時
•
不會以導(dǎo)致視圖定義非法或強(qiáng)制 sql server 在該視圖上重新創(chuàng)建索引的方式,更改視圖定義中所引用的對象。
問:為何不能在索引視圖中使用 outer join?
答:當(dāng)將數(shù)據(jù)插入基表時,行會在邏輯上從基于 outer join 的索引視圖上消失。這會使執(zhí)行 outer join 視圖的增量更新變得相對復(fù)雜,而執(zhí)行性能將比基于標(biāo)準(zhǔn) (inner) join 的視圖慢一些。
新聞熱點(diǎn)






疑難解答
圖片精選













