現在來關注一下數據庫鏡像狀態,從主服務器和數據庫開始。
主服務器數據庫狀態
當safety設置為full,主數據庫的正常操作狀態時synchronized狀態。當safety設置為off,主數據庫的正常操作狀態是synchronzing狀態。
◆如果safety設置為full,主數據庫的起始狀態始終是synchronizing,當主數據庫和鏡像數據庫事務日志同步后,數據庫狀態就轉換成synchronized,
◆如果safety設置為full并且主服務器斷開了和見證服務器的連接但依然可以進行事務處理,那么數據庫狀態為exposed。
◆如果safety設置為full并且主服務器無法和其他服務器組成quorum,那么將無法提供數據庫服務。不允許任何的用戶連接和事務處理。
下表顯示了主數據庫可能的狀態,以及導致狀態轉換的一些事件。
表5:主數據庫狀態,safety為full以及safety為off
safety | 主服務器初始狀態 | 事件 | 導致結果 | quorum | exposed | 能否提供數據庫服務 |
full | synchronizing | 同步發生 | synchronized | 是 | 否 | 是 |
full | synchronized | 會話暫停 | suspended | 是 | 是 | 是 |
full | synchronized | 鏡像服務器上出現redo錯誤 | suspended | 是,使用見證服務器 | 是 | 是 |
否,沒有見證服務器 | - | 否 | ||||
full | synchronized | 鏡像服務器不可用 | disconnected | 是,使用見證服務器 | 是 | 是 |
否,沒有見證服務器 | - | 否 | ||||
off | synchronizing | 會話暫停 | suspended | - | 是 | 是 |
off | synchronizing | 鏡像服務器上出現redo錯誤 | suspended | - | 是 | 是 |
off | synchronizing | 鏡像服務器不可用 | disconnected | - | 是 | 是 |
當safety設置為full,主數據庫首先進入synchronizing狀態,只要和鏡像數據庫同步,兩個伙伴都進入synchronized狀態。當safety設置為off,伙伴數據庫從synchronizing狀態開始并在整個鏡像過程中保持該狀態。
對于這兩個safety設置,如果會話被掛起或者出現了鏡像服務器的redo錯誤,那么主數據庫進入suspended狀態。如果鏡像服務器不可用,那么主數據庫進入disconnected狀態。
在disconnected和suspended狀態下:
◆當safety設置為full,如果主服務器無法和見證服務器或者鏡像服務器自稱quorum,那么主數據庫被視為exposed。這意味著主數據庫為活動狀態,支持用戶連接和事務處理。 但是沒有日志記錄被發送到鏡像數據庫。因此如果主數據庫失敗了,那么鏡像數據庫不包含任何自主數據庫進入exposed狀態后主服務器上發生的事務。同樣的,也不可以清理主數據庫的事務日志,這導致日志文件的無限增長。
◆當safety設置為full,如果主服務器無法和其他服務器組成quorum,它將不能提供數據庫服務。所有用戶將被斷開連接,也不允許新的事務處理。
◆當safety設置為off,朱數據庫被視為exposed,因為沒有事務日志記錄被發送到鏡像。
注意:management studio's object explorer會在server樹圖中數據庫名稱的旁邊報告主數據庫狀態。將主數據庫的synchronized狀態報告為 'principal, synchronizing',disconnected狀態報告為'principal, disconnected.'
鏡像數據庫狀態
鏡像數據庫具有和主數據庫相同的狀態,但是由于鏡像數據庫始終處于nonrecovered狀態,因此在擔當鏡像角色的時候不能提供數據庫服務。下表顯示了可以導致鏡像服務器和數據庫狀態改變的一些最常見事件。
表6:鏡像服務器狀態,safety為full以及safety為off
safety | 鏡像服務器狀態 | 事件 | 導致的結果 |
full | synchronizing | 同步發生 | synchronized |
full | synchronized | 會話暫停 | suspended |
full | synchronized | 鏡像服務器上出現redo錯誤 | suspended |
full | synchronized | 主數據庫不可用 | disconnected |
off | synchronizing | 會話暫停 | suspended |
off | synchronizing | 鏡像服務器上出現redo錯誤 | suspended |
和主數據庫一樣,management studio's object explorer在server樹的數據庫名稱旁邊報告鏡像數據庫狀態。鏡像數據庫的synchronized狀態報告為'mirror, synchronizing',disconnected狀態報告為'mirror, disconnected.'
見證服務器狀態
在sys.database_mirroring目錄視圖中有三種見證服務器狀態,connected、 disconnected和unknown。
表7:witness服務器狀態(記錄在伙伴服務器上)
見證服務器狀態 | 事件 | 導致的結果 |
connected | 見證服務器不可用 | disconnected |
主服務器無法初始化鏡像 | unknown |
由于見證服務器狀態真正記錄在伙伴服務器而不是見證服務器上,因此這些狀態是從有利于伙伴的角度來設置的,因此當您看到見證服務器為disconnected狀態時,意味著伙伴和見證服務器斷開了。數據庫鏡像啟動后,如果鏡像服務器無法與主服務器進行初始化,那么見證服務器進入unknown狀態。
傳輸事務日志記錄
sql server主服務器和鏡像服務器傳輸消息和日志記錄的次序根據事務安全性的設置而不同。我們先研究同步傳輸,然后再研究異步傳輸。
當sql server將事務事件記錄在事務日志中時,日志記錄被寫入磁盤前暫時存放在日志緩沖區中。 數據庫鏡像時,每次日志緩沖區被輸出到硬盤時(硬化),主服務器也將相同的日志記錄塊發送到鏡像服務器。
1. 當safety設置為full,只要sql server主服務器硬化它的日志記錄塊,就同時將相同的日志記錄塊發送到鏡像服務器,并認為本地的日志i/o和遠程鏡像服務器的日志i/o從本質上來說是一樣 的。這種傳輸稱為同步的,因為在一個事務提交之前,主服務器既要等待本地的i/o(硬化)還要等待等待鏡像服務器有關完成i/o(硬化)的答復。
每次主服務器或者鏡像服務器硬化日志緩沖區時,都會將緩沖區中最高的日志序列號(lsn)+ 1作為mirroring_failover_lsn記錄在元數據中。
mirroring_failover_lsn用于協商事務日志最后的保障點,這樣兩個伙伴數據庫就可以在初始化時保持同步,在故障轉移后也保持同步。
當主服務器發送日志記錄給鏡像服務器時,主服務器上的mirroring_failover_lsn通常會提前一些。鏡像服務器硬化日志記錄時會記錄其mirroring_failover_lsn,然后回復主服務器。但是等主服務器接收到來自鏡像的確認信息時,主服務器可能已經開始硬化新的一組日志記錄了。
表8顯示了主服務器和鏡像服務器safety為full時的一個事件序列示例。
表8:safety為full (同步傳輸)事件序列的示例
server a | server b |
principal, synchronized | mirror, synchronized |
開始一個包含數據更新的多語句事務 | |
主數據庫的事務日志記錄被放入事務日志緩沖區 | |
事務日志緩沖區內容被寫入磁盤(硬化),日志記錄塊被發送到鏡像服務器,主服務器記錄日志塊的 mirroring_failover_lsn,然后等待鏡像服務器的確認。 | |
鏡像服務器接收日志記錄并放入事務日志緩沖區 | |
鏡像服務器將日志緩沖區輸出到磁盤,記錄 mirroring_failover_lsn,然后通知主服務器日志塊已被硬化 | |
主服務器接收日志記錄已被鏡像服務器硬化到磁盤的通知 | 鏡像服務器繼續重新執行redo隊列中的事務日志 |
包含了commit的日志寫入事務日志緩沖區 | |
事務日志緩沖區內容被寫入磁盤(硬化), 包含了commit的日志記錄塊被發送到鏡像服務器,主服務器記錄日志塊的 mirroring_failover_lsn,然后等待鏡像服務器的確認。 | |
鏡像服務器接收日志記錄并放入事務日志緩沖區 | |
鏡像服務器將日志緩沖區輸出到磁盤,記錄the mirroring_failover_lsn,然后通知主服務器日志塊已被硬化 | |
主服務器接收日志記錄已被鏡像服務器硬化到磁盤的通知,至此整個事務提交 | 鏡像服務器繼續重新執行redo隊列中包含了commit的事務日志,修改數據頁面 |
新事務被寫入主服務器的日志緩沖區 |
以上事件序列中關鍵的一點就是:當 safety設置為full時,主服務器硬化日志緩沖區以及將日志緩沖區中日志記錄的副本發送到鏡像服務器,二者是同時進行的。然后主服務器開始等待自己的i/o以及鏡像服務器的i/o,兩個i/o都完成后才認為事務完成了。當主服務器接收到來自鏡像的答復后,再開始處理下一次硬化。
當safety設置為full時,盡管主服務器和鏡像服務器之間協調緊密,但是數據庫鏡像不是分布式事務,也不使用兩階段提交協議。
◆在數據庫鏡像中,兩個事務分別在兩臺服務器上執行,并不是一個跨服務器的分布式事務。
◆數據庫鏡像不使用伙伴服務器作為分布式事務中的資源管理器。
◆數據庫鏡像事務不經歷準備和提交階段。
◆最重要的是,鏡像服務器上事務提交失敗不會導致主服務器上的事務會滾,這一點與分布式事務不同。
2. 當safety設置為off時,主服務器不等待來自鏡像服務器的確認消息,因此主服務器上已提交事務數量可能多于鏡像服務器,如圖9所示:
表9:safety為off (異步傳輸)事件序列的示例
server a | server b |
principal, synchronizing | mirror, synchronizing |
開始一個包含數據更新的多語句事務 | |
數據更新的事務日志記錄被寫入事務日志緩沖區 | |
事務日志緩沖區內容被強制輸出到磁盤(硬化),日志記錄塊被發送到鏡像服務器,主服務器記錄日志塊的 mirroring_failover_lsn | |
包含了commit的日志被寫入事務日志緩沖區,加上其他的事務活動 | 鏡像服務器接收日志記錄并放入事務日志緩沖區 |
事務日志緩沖區內容被寫入磁盤, 包含了commit的日志記錄塊被發送到鏡像服務器 | 鏡像服務器將日志緩沖區輸出到磁盤,記錄the mirroring_failover_lsn,然后通知主服務器日志塊已被硬化 |
提交事務 | 鏡像服務器繼續重新執行redo隊列中的事務日志 |
鏡像服務器接收日志記錄并放入事務日志緩沖區 | |
鏡像服務器將日志緩沖區輸出到磁盤,記錄the mirroring_failover_lsn,然后通知主服務器日志塊已被硬化 |
數據庫鏡像角色轉換
可以從數據庫鏡像服務器或者應用程序的角度來思考數據庫鏡像故障轉移問題。從數據庫鏡像服務器角度,故障轉移就是將鏡像服務器轉換為主服務器,以及使用新恢復的數據庫作為主數據庫。故障轉移可以是自動的、手動的、或者forced service。
◆自動的 – 只有高可用模式下才會產生(safety設置為full以及見證服務器的參與)
◆手動的 - 只有高可用和高保護操作模式下才會產生(safety設置為full),兩個伙伴數據庫都是synchronized。
◆forced service (允許數據丟失) - 主要是在高性能模式下(safety off)用于立刻和手動的恢復鏡像數據庫
當safety設置為full時,用于互換服務器角色的最好的方式是使用手動故障轉移,而不是forced service。
自動故障轉移
自動故障轉移是高可用模式下(safety為full使用見證服務器)數據庫鏡像的功能。大多數情況下,sql server可以在幾秒鐘內完成自動故障轉移。sql server可以進行局部自動故障轉移,因為包含在數據庫鏡像會話中的sql服務器會彼此測試對方的存在。該過程稱為“ping”,但包含的操作遠不止一個普通的 ip地址ping。鏡像服務器和見證服務器聯系主服務器以檢查主物理服務器是否存在、sql server是否存在、以及主數據庫是否可用。類似的, 主服務器和見證服務器ping鏡像服務器以檢查鏡像物理服務器和sql server實例的可用性,以及鏡像數據庫的還原狀態。
假設使用safety full和見證服務器配置了數據庫鏡像。鏡像服務器即server b通過ping發現主服務server a不可用。server b與見證服務器通信并收到見證服務器也看不到server a的確認消息。那么server b將和見證服務器組成quorum并將自己提升為主服務器角色。它將恢復它的數據庫并且通知見證服務器如今自己擔當了主服務器的角色(盡管數據庫處于disconnected狀態,新主數據庫的事務日志也不能被截斷)。
server b的新主數據庫繼續重新執行事務日志中的活動,但是它將持續redo狀態而且大多數情況下只有很少的工作需要完成。在所有sql server版本中,新主數據庫只要完成redo過程就立刻可用了。當數據庫進入undo狀態時將可以接收用戶連接了。完成redo通常只需幾秒鐘,盡管余下的undo階段時間可能很長。在數據庫鏡像中,新的主數據庫只要redo階段完成就可以為用戶連接提供服務。新主服務器b的數據庫處于disconnected狀態而且是exposed,但是只要redo過程完成就可以提供數據庫服務。
通常將整個應用程序從主服務器重新定向到新主服務器花費的時間要多于數據庫鏡像的自動故障轉移。應用程序必須檢測和重試連接,這樣也會增加該過程的整體時間。此外,如果將新的sql server驗證登陸賬號添加到服務器,還需要使用系統存儲過程sp_change_users_login將這些登陸賬戶映射到新主數據庫的用戶賬戶。如果舊的主服務器上一些關鍵對象,如sql agent作業還沒有拷貝到新主服務器上,也會耽誤應用程序故障轉移的完成。(更多信息請閱讀該白皮書實現數據庫鏡像部分的“為故障轉移準備鏡像服務器”)
現在假設舊的主服務器聯機了。如果是手動故障轉移,或者舊的主服務器被快速修復的自動故障轉移場景,兩臺服務器需要進行角色互換,那么就必須進行一個協商過程。在數據庫鏡像重新開始之前,兩臺伙伴服務器需要決定彼此怎樣進行同步。鏡像故障轉移lsn這個過程中扮演了一個關鍵角色。
server a (新鏡像服務器)落后了,但它并不清楚自己落后了多少。server a向server b(新主服務器)報告它從server b接收的最后的鏡像故障轉移lsn。另一方面,server b由于某些提交的工作而導致它有最新的鏡像故障轉移lsn,server a必須要追趕上server b。server b將足夠數量的事務日志發送給server a,使server a通過重新這些執行事務并與server b同步。
手動故障轉移
手動故障轉移就是依次交換兩個伙伴服務器的角色。它要求safety設置為full,并且主服務器和鏡像服務器處于synchronized狀態。
在主服務器上使用下面的alter database命令進行手動故障轉移:
| alter database adventureworks set partner failover; |
或者在management studio的database properties/mirroring對話框中單擊failover按鈕。手動故障轉移在舊的主數據庫上斷開所有用戶連接并回滾所有未完成的事務。通過完成所有redo隊列中已提交的事務,回滾所有未完成的事務(在undo階段)來恢復鏡像數據庫。舊的舊的鏡像數據庫被分配了主數據庫角色,而舊的主數據庫則擔當新的鏡像數據庫角色。兩臺服務器根據它們的鏡像故障轉移lsn協商數據庫鏡像的新起點,然后處理角色互換。
可以使用手動故障轉移作為實現操作系統或者sql server實例的‘滾動升級’的一種方式來,假如您在初始化鏡像服務器之前首先升級鏡像服務器。更多信息請參閱sql server books online中'manual failover' 主題。
forced service
在鏡像服務器上使用alter database命令進行forced service:
alter database adventureworks set partner force_service_allow_data_loss; |
通常只有當safety為off并且主服務器再也無法運轉時才使用這種方式。也可以在safety為full使使用該命令,但是如果恢復的鏡像服務器無法組成quorum,它也不能提供數據庫服務。因此最好在safety為off(高性能操作模式)是使用該命令。由于異步的數據傳輸無法保證鏡像數據庫包含所有主服務器上提交的最新事務,因此有些數據可能會丟失。
數據庫鏡像可用性場景
在這一部分,您將根據以下兩類事件對數據庫鏡像預期的可用性結果進行研究:
◆一個或多個服務器或者數據庫失敗
◆服務器之間一條或多條通信連路失敗
服務器失敗可能是由于某個鏡像伙伴數據庫、或者某個sql server實例不可用。此外,即使服務器本身可以繼續運轉,但是數據庫鏡像伙伴服務器之間的通信連路可能中斷。
以下場景中,兩個組件的同時失敗被視為一個組件緊接著另一個組件的順序失敗。例如,server a和b出現了同時失敗,鏡像系統將該事件視為一個順序事件:server a失敗然后server b失敗,或者反過來。
使用下面的規則來判定一個不可用事件的預期結果:
1.當safety設置為full時,主服務器需要至少一臺其他服務器才能形成quorum來保持數據庫可用。
如果主服務器無法組成quorum,也就無法再提供數據庫服務了。
2.當safety設置為full,如果鏡像服務器和見證服務器都無法聯系到主服務器,那么鏡像服務器可以和見證服務器組成quorum并且改變其角色,使之成為新的主服務器。
這就是自動的故障轉移。
3.當safety設置為full,如果主服務器和見證服務器合作組成quorum,但是斷開了和鏡像服務器的連接,那么主服務器失敗將不允許鏡像服務器和見證服務器組成quorum,也不允許鏡像服務器承擔主服務器的角色。
這樣可以防止所做的工作由于會話中斷而丟失。
4.當safety設置為full,如果失敗的主服務器在停機或者孤立后重新加入會話,同時舊的鏡像服務器已經承擔了主服務器的角色(和見證服務器組成quorum),那么舊的主服務器將在此次會話中承擔新鏡像服務器角色。
在故障轉移過程中,鏡像服務器和見證服務器會增加鏡像角色順序計數器。因為主服務器的鏡像角色順序計數器 小于另一個伙伴服務器和見證服務器的順序計數器,因此那兩臺服務器會在舊的主服務器重新加入會話之前組成quorum并開始工作。舊的主服務器擔當起鏡像的角色。
5.當safety設置為full并且會話中沒有見證服務器,或者見證不知何故退出了會話,鏡像伙伴服務器的失敗將導致無法組成quorum,主服務器也因此不再保持主數據庫可以使用。
無法組成quorum,因此不可能進行自動的故障轉移,如果見證服務器不包含在safety為full的會話中。
高可用場景中服務器失敗
高可用操作模式下的數據庫鏡像其目的就是盡可能增加數據庫的可用性。在這種模式下,如果主數據庫無法訪問,那么數據庫鏡像將迅速使鏡像數據庫可以接受訪問。在下面的一組場景中,我們的討論將從高可用配置加上三臺獨立的服務器開始。
在下面的高可用場景中,server a作為主服務器啟動,server b是鏡像服務器,而server w是見證服務器,如圖1所示:
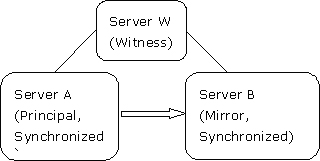
圖1:示例數據庫鏡像會話在高可用操作模式下啟動
所有這三臺服務器可以在同一個站點使用局域網連接,也可以在不同的站點使用wan進行連接。server a和server b可以互換角色,但是server w始終作為見證服務器。
現在來考慮如果其中一臺服務器出現故障時產生的結果。
場景 hasl1.1:主服務器失敗
下面的場景分析了在高可用模式下主服務器失敗時會發生什么。圖 2顯示了不同的角色,以及鏡像伙伴之間如何做角色轉換。

圖2:在高可用模式下,當主服務器server a失敗,故障轉移發生
主服務器server a失敗后,鏡像和見證服務器組成quorum,自動的故障轉移產生。如果重新恢復了原始的主服務器,它將擔當起鏡像服務器的角色。
注意:要導致高可用模式下的故障轉移,失敗可以發生在不同的級別上:服務服務器可能停機、主服務器上的sql server實例可能停止或者失敗、服務器上的主數據庫可能不可用或狀態可疑。在下面場景中,主服務器失敗可能由這些事件中的任何一個引起。
因為server b和w可以組成quorum,并且二者均無法聯系server a,那么server b可以將自己提升為新的主服務器。但是如果沒有鏡像服務器,鏡像會話就被認為是exposed。
server a恢復后,它成為新的主服務器,鏡像會話也不再是exposed。
單服務器失敗事件并不多見,兩臺服務器失敗就更少見了,因此研究在這種情況下出現的結果十分有用。
兩臺服務器可以同時或者幾乎同時失敗,但從數據庫鏡像的角度來看,其結果被視為一臺服務器失敗緊接著另一臺也失敗了。因此這些場景只考慮當多臺服務器順序失敗時的后果。
接下來的兩個場景分析主服務器 server a失敗,緊接著其他兩臺服務器也失敗時會產生的結果。
◆新的主服務器 server b失敗;
◆見證服務器 server w失敗;
場景 hasl1.2:主服務器失敗,隨后新的主服務器失敗
同前面的場景一樣,在高可用操作模式下,如果主服務器首先失敗,那么故障轉移發生。圖3顯示了如果新的主服務器接下來也失敗了,那么無論怎樣恢復這些服務器,新的主服務器(server b)始終保持其主服務器的角色。
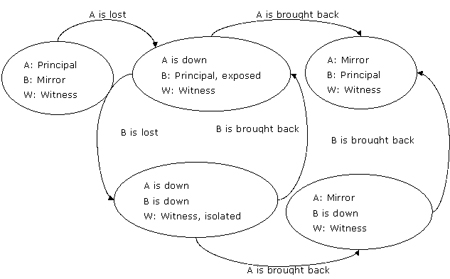
圖3:由于主服務器失敗,接著新主服務器也失敗而導致角色轉換
server a失敗后,server b成為新的主服務器,但是無法將數據發送給鏡像服務器,因此主服務器處于exposed,即使它仍然提供數據庫服務。當server a失敗緊接著server b也失敗,那么就不存在數據庫鏡像了,因為server b已經停工了。
如果server a首先恢復,它從見證服務器的mirroring_role_sequence號中檢測到見證服務器已經組成了新的quorum。
server a接納了鏡像服務器的角色,然后等待server b恢復。server b一旦恢復,立刻開始了和server a的數據庫鏡像過程。如果server b先恢復,那么就重新回到了在hasl1。1中顯示的初始場景。
注意:如果server w在server a和server b相繼失敗后也宣告失敗,導致所有三臺服務器均停工,那么無論以什么次序恢復見證服務器,已經轉換完成的server a和server b的角色將保持不變。
場景 hasl1.3:主服務器失敗,隨后見證服務器失敗
主服務器失敗后發生故障轉移。見證服務器可能接下來也失敗,如圖4所示:
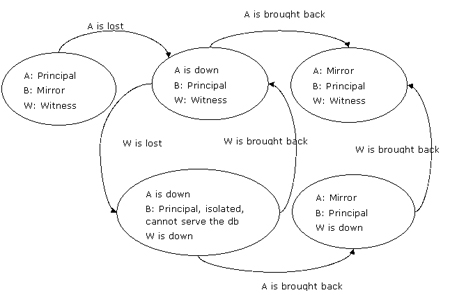
圖4:見證服務器緊隨原始主服務器出現失敗,那么新主服務器無法提供數據庫服務
當見證服務器 server w主服務器 server a失敗后也出現失敗,那么新主服務器 server b依然為主服務器但被孤立,無法組成quorum,也不能提供數據庫服務。
如果server a首先恢復,server b的mirroring_role_sequence號將比server a的大1,因為產生了故障轉移。這些信息指示server a如今server b在server a只有擔當了主服務器的角色。server a和server b組成quorum 并成為一對鏡像,此后兩臺服務器保持同步。除非server w恢復,否則不會產生自動故障轉移。
注意: 如果server w在server a和server b相繼之后也宣告失敗,那么無論以什么次序恢復見證服務器,已經轉換完成的server a和server b的角色將保持不變。
場景 hasl2.1:鏡像服務器失敗
如果鏡像服務器首先失敗,那么主服務器被視為exposed,因為它無法發送數據給鏡像服務器。圖 5顯示了server b,即鏡像服務器失敗時的行為。
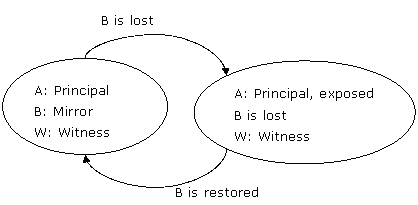
圖5:在高可用模式下,當鏡像服務器server b失敗時不產生故障轉移
沒有自動故障轉移發生,鏡像伙伴也不會交換角色。當server b恢復時,所有三臺服務器還原到其初始角色和狀態。
下表顯示了鏡像服務器server b失敗以及恢復時數據庫狀態。
由于沒有鏡像服務器,數據無法存放在冗余數據庫中,因此會話處于exposed。
server b一旦恢復立刻重新擔當起它的鏡像服務器角色。只要兩臺服務器同步,鏡像會話就不再被視為exposed。
接下來的兩個場景考慮鏡像服務器server b失敗,緊接著主服務器server a或者見證服務器server w失敗時產生的結果。
場景 hasl2.2:鏡像服務器失敗,隨后主服務器失敗
緊隨鏡像服務器之后主服務器也失敗了,鏡像伙伴服務器的角色保持不變。圖6顯示了采用不同方式還原服務器時角色將如何轉換。
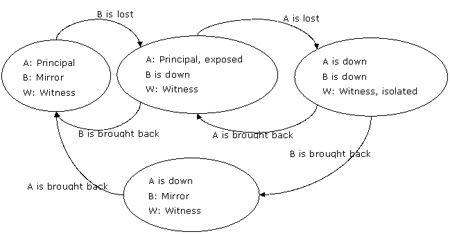
圖6:鏡像服務器失敗隨后主服務器主失敗,那么見證服務器被孤立
在server b和server a都失敗后,各服務器狀態顯示在圖中的右上角處。
如果server b首先恢復,它將從見證服務器server w處檢測到server a依然為主服務器并且還沒有產生故障轉移,mirroring_failover_lsn也沒有增加。其結果為,server b依然為鏡像服務器。server w恢復后將會話還原到初始狀態。
注意:如果server w在server b和server a相繼失敗之后也宣告失敗了,那么以任何順序還原這些服務器將導致相同結果。
場景 hasl2.3:鏡像服務器失敗,隨后見證服務器失敗
鏡像服務器失敗,隨后見證服務器也失敗,那么主服務器被孤立并且無法和任何其他服務器組成quorum。因此它必須停止數據庫的工作,如圖7右上角所示。
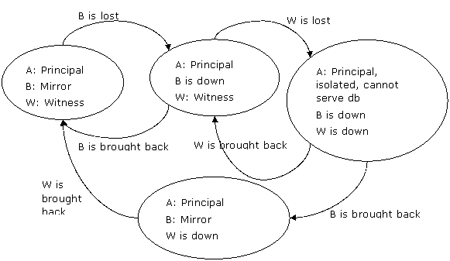
圖7:a鏡像服務器失敗,隨后見證服務器失敗,導致主服務器無法提供數據庫服務
由于鏡像服務器故障以及隨后的見證服務器失敗,主服務器 server a保持其主服務器角色,由于無法和任何其他服務器組成quorum,而safety又被設置成full,因此不再為數據庫提供服務,并斷開所有的用戶連接。
如果server b首先恢復,那么數據庫鏡像將重新開始工作,盡管由于缺失見證服務器而不會產生自動故障轉移。
如果server w首先恢復,那么情況與圖5中顯示的一樣。
注意:如果server a在server b和server w相繼失敗之后也宣告失敗,那么以任何次序還原這些服務器其最終結果保持不變。
場景 hasl3.1:見證服務器失敗
見證服務器失敗時,數據庫鏡像繼續進行但是不可能產生自動的故障轉移。如果再有一臺或多臺服務器失敗,就意味著沒法組成quorum,那么主服務器上的數據庫也不再服務于數據庫用戶。
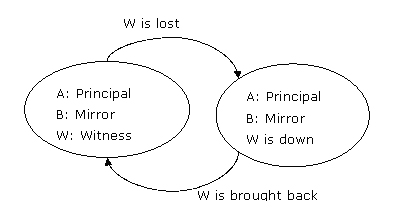
圖8:在高可用模式下,見證服務器server w首先失敗,那么數據庫鏡像繼續
server w恢復后,兩個伙伴服務器server a和server b維持它們的初始角色。
下表顯示了見證服務器失敗以及恢復后,數據庫狀態以及quorum的變化。
下面的兩個場景考慮見證服務器server w失敗,緊接著主服務器 server a或者鏡像服務器server b失敗時產生的結果。
場景 hasl3.2:見證服務器失敗,隨后主服務器失敗
見證服務器首先失敗,那么數據庫鏡像將繼續進行,但是不可能產生自動的故障轉移。其余兩臺服務器中任何一臺失敗將導致無法組成quorum,余下的那臺服務器將被孤立。
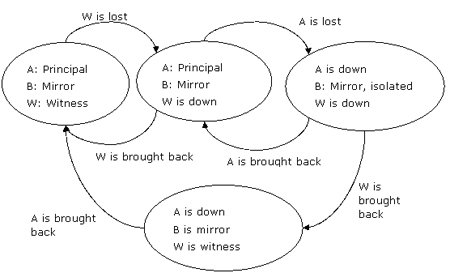
圖9:原始見證服務器失敗,隨后主服務器失敗,鏡像伙伴角色保持不變
如果server w首先恢復,那么server b將從見證服務器那里檢測到最后的主服務器是server a,同時server b依然是鏡像服務器。最終server a恢復時,它將保持其主服務器角色。
注意: 如果server b在server w和server a相繼失敗后也宣告失敗了,那么以任意次序還原這些服務器都不會影響最終結果。
場景 hasl3.3:見證服務器失敗,隨后鏡像服務器失敗
如果見證服務器失敗,隨后鏡像服務器也失敗,那么主服務器被孤立。由于safety設置為full并且主服務器無法組成quorum,它將不再提供數據庫服務,如圖10所示。
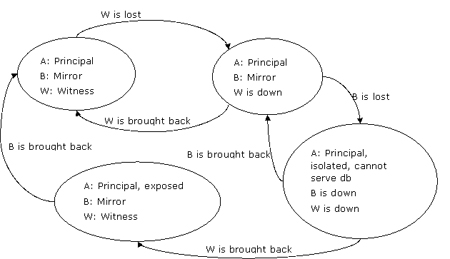
圖10:見證服務器失敗,隨后鏡像服務器失敗,主服務器必須停止其數據庫服務
注意: 如果server a在server w和server b相繼失敗之后也宣告失敗, 那么以任意次序還原這些服務器都不會影響最終結果。
總結:高可用場景中服務器失敗
從這些場景中可以得出幾個結論。在高可用操作模式下:
1.如果主服務器首先不可用,那么產生自動的故障轉移,原先的鏡像服務器將擔當主服務器角色,并使其數據庫服務于用戶活動。后續的服務器失敗和恢復不會影響使用新主服務器的數據庫鏡像的整體配置。數據庫鏡像將以相反的方向繼續進行。
2.如果鏡像首先不可用,那么產生自動的故障轉移 。后續的服務器失敗以及恢復次序都不會影響鏡像伙伴角色。
3.如果見證服務器首先不可用,那么不可能產生自動的故障轉移,鏡像伙伴服務器將保持其初始角色。后續的服務器失敗以及恢復都不會影響鏡像伙伴角色。
下表總結了在高可用場景中出現一臺或兩臺服務器失敗時產生的結果。表中假設的條件是safety設置為full并且鏡像會話中的服務器滿足下列條件:
a:主服務器, synchronized
b:鏡像服務器,synchronized
w:見證服務器,connected
表中使用灰色加亮顯示故障轉移場景。
表10:總結:單服務器或者雙服務器失敗,顯示伙伴服務器角色和數據庫狀態
高可用場景中通信失敗
高可用操作模式需要三個sql sever實例。如果這些服務器位于兩個或三個獨立的物理站點并且相距很遠,那么這些站點間的通信就很可能出現問題。換句話說,服務器依然運轉但是彼此間的通信連路中斷了。這種情況比前面的那些場景要復雜一些,但原理是一樣的。
下面高可用操作場景中通信失敗的研究將通過兩組來完成。第一組是基于三個來自不同站點的sql server實例,因此有三條獨立的通信連路。第二組是基于兩個獨立站點上的服務器,第一個站點上的一對服務器和第二個站點上的第三臺服務器之間有一條通信連路。
先從第一組開始,假設一個數據庫會話中所有三臺服務器之間有三條獨立的通信連路。例如,主服務器、鏡像服務器和見證服務器位于三個獨立的協作站點上(也有可能三臺服務器位于同一個站點,但使用私有網絡連接)
初始條件是server a上運行主數據庫并且與其鏡像伙伴server b保持同步。
server b上是鏡像數據庫safety設置為full,見證服務器 (server w)也包含在數據庫鏡像會話中。圖11顯示了初始配置。
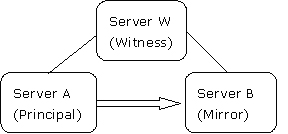
圖11:高可用配置中三臺獨立服務器、三條獨立通信連路的初始狀態
注意:要獲得頁面上圖表的解釋,請參閱前面介紹的“高可用場景中服務器失敗”
根據圖11,三條鏈路可能首先中斷:a/b, a/w和b/w。注意當某條通信連路中斷時,所有三臺服務器依然運轉正常。只有主服務器和鏡像服務器之間的通信連路有一些影響,如表11所示。
表11:總結:單條通信連路中斷
初始條件 | 事件 | quorum | 結果 | 條件 |
a: 主服務器, synchronized b: 鏡像服務器, synchronized w: 見證服務器, connected | a/b連路中斷 | a和w | a上的數據庫提供服務, exposed | a: 主服務器, disconnected b: 鏡像服務器, disconnected w: 見證服務器, connected |
a/w | a和b | a上的數據庫提供服務 | a: 主服務器, synchronized b: 鏡像服務器, synchronized w: 見證服務器, connected | |
b/w | a和b | a上的數據庫提供服務 | a: 主服務器, synchronized b: 鏡像服務器, synchronized w: 見證服務器, connected |
只有主服務器/鏡像服務器的連接中斷會對鏡像造成影響。其他的連路中斷,例如主服務器/見證服務器或者鏡像服務器/見證服務器之間的通信中斷不會改變數據庫鏡像會話的行為。
總之,表hacl1顯示出:
◆所有單條鏈路中斷場景中只有主服務器/鏡像服務器鏈路中斷會影響數據庫鏡像,主服務器運行 狀態為exposed,因為沒有日志記錄發送到鏡像。
現在考慮如果第二條連路中斷產生的結果。兩條連路可以同時中斷,也可以相繼中斷。
如果兩條連路同時中斷,其最終結果與兩條連路相繼中斷是一樣的。但是無法事先預料中斷的先后順序;只有知道了先后次序才能夠據此分析鏈路同時中斷的結果。
由于這個原因,我們只考慮鏈路順序中斷的情形。表12列出了高可用模式中通信鏈路中斷的一些基本場景。
表12:大部分雙-通信鏈路中斷的結果與服務器故障場景中單機故障是一樣的
場景 | 第一條連路中斷 | 場景 | 第一條連路中斷 | 結果 | 其余服務器的等價場景 | 參閱場景 |
hacl1.1 | a/b | hacl1.2 | a/w | server a被孤立 | server a停機 | 無 |
hacl1.3 | b/w | server b 被孤立 | server b 停機 | hasl2.1 | ||
hacl2.1 | a/w | hacl2.1 | a/b | server a 被孤立 | server a 停機 | hasl1.1 |
hacl2.2 | b/w | server w 被孤立 | server w 停機 | hasl3.1 | ||
hacl3.1 | b/w | hacl3.1 | a/w | server w 被孤立 | server w 停機 | hasl3.1 |
hacl3.2 | a/b | server b 被孤立 | server b 停機 | hasl2.1 |
表hacl2顯示所有順序的雙-通信鏈路失敗都等價于前一部分介紹的單服務器故障場景,因此我們不再這里對它們作重復分析了。
值得注意的一點是:
◆兩條鏈路中斷時只有一個場景會產生故障轉移:主服務器/見證服務器鏈路中斷,隨后主服務器/鏡像服務器鏈路中斷。
如果主服務器/鏡像服務器鏈路中斷,隨后主服務器/見證服務器也出現鏈路中斷,那么不會產生故障轉移,即使主服務器被孤立而且鏡像服務器和見證服務器無法聯系上它。
我們再仔細研究一下場景 hacl1.2。
場景 hacl1.2:主服務器/鏡像服務器連路中斷,隨后主服務器/見證服務器鏈路中段
如果主服務器/鏡像服務器鏈路中段,隨后主服務器和見證服務器之間的鏈路也中斷了,那么主服務器被孤立。它看不到其他服務器并且失去了它的quorum。同時,鏡像服務器和見證服務器無法知道主服務器是否依然健在,因此server b擔當起主服務器,然后自動的故障轉移產生。圖12顯示了這些事件。
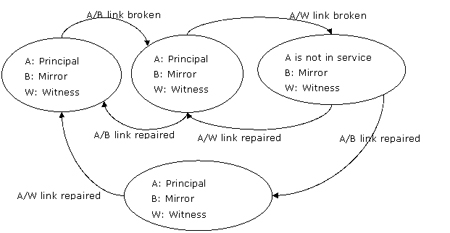
圖12:在高可用模式下, 主服務器/鏡像服務器鏈路中段,隨后主服務器/見證服務器鏈路中段,不產生故障轉移
當主服務器/鏡像服務器以及主服務器/見證服務器之間的通信鏈路相繼中斷有,server a被孤立并使其數據庫停止服務。server b和w無法形成quorum,因為server a可能執行了一些server b上沒有的工作。
如果主服務器/見證服務器 (a/w) 鏈路中斷首先修復,那么server a繼續擔當其主服務器角色,狀態為disconnected。但是不會進行數據庫鏡像,因為主服務器和鏡像服務器之間的連接還沒有修復。
如果主服務器/鏡像服務器 (a/b) 鏈路中斷首先修復,那么server a將繼續與server b的數據庫競相,即使沒有見證服務器,因此該會話是exposed。除非主服務器/見證服務器連接最終被修復,否則不會產生自動的故障轉移。
總結:高可用場景中通信失敗:三個站點
下表總結了使用三臺獨立物理服務器時單鏈路和雙-鏈路中斷的行為。
表中的初始條件是safety設置為full,服務器分別是:
a:主服務器, synchronized
b:鏡像服務器, synchronized
w:見證服務器, connected
使用灰色加亮顯示故障轉移路徑。
表13:總結:單條鏈路中斷和雙-鏈路中斷,高可用模式,三臺獨立服務器,safety設置為full
場景 hacl4:兩個站點,見證服務器位于鏡像服務器站點
如果所有服務器之間僅有一條通信連路,那么必須選擇見證服務器的位置。首先,假設見證服務器和鏡像數據庫服務器放置在一起。兩組服務器之間僅有一條通信連路,該鏈路可能中斷,如圖13所示。
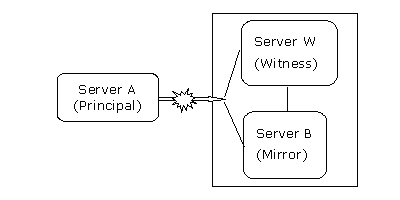
圖13:主服務器和鏡像服務器/見證服務器站點之間的通信連路中斷了
server a看不到見證服務器server w或者鏡像數據庫服務器server b,因此無法組成quorum。 server b和server w可以組成quorum,但二者均無法看見主服務器server a。鏈路中斷的結果顯示在圖14。
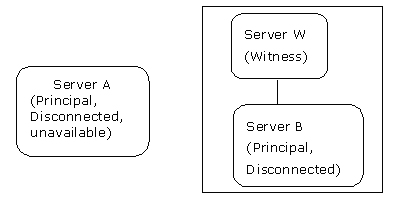
圖14:通信連路中斷并且見證服務器位于鏡像服務器站點,產生故障轉移
新聞熱點






疑難解答













