本文示例源代碼或素材下載
摘要:sql server 2005 中基于表的分區(qū)功能為簡(jiǎn)化分區(qū)表的創(chuàng)建和維護(hù)過(guò)程提供了靈活性和更好的性能。追溯從邏輯分區(qū)表和手動(dòng)分區(qū)表的功能到最新分區(qū)功能的發(fā)展歷程,探索為什么、何時(shí)以及如何使用 sql server 2005 設(shè)計(jì)、實(shí)現(xiàn)和維護(hù)分區(qū)表。
為什么要進(jìn)行分區(qū)?什么是分區(qū)?為什么要使用分區(qū)?簡(jiǎn)單的回答是:為了改善大型表以及具有各種訪問(wèn)模式的表的可伸縮性和可管理性。通常,創(chuàng)建表是為了存儲(chǔ)某種實(shí)體(例如客戶(hù)或銷(xiāo)售)的信息,并且每個(gè)表只具有描述該實(shí)體的屬性。一個(gè)表對(duì)應(yīng)一個(gè)實(shí)體是最容易設(shè)計(jì)和理解的,因此不需要優(yōu)化這種表的性能、可伸縮性和可管理性,尤其是在表變大的情況下。
大型表是由什么構(gòu)成的呢?超大型數(shù)據(jù)庫(kù) (vldb) 的大小以數(shù)百 gb 計(jì)算,甚至以 tb 計(jì)算,但這個(gè)術(shù)語(yǔ)不一定能夠反映數(shù)據(jù)庫(kù)中各個(gè)表的大小。大型數(shù)據(jù)庫(kù)是指無(wú)法按照預(yù)期方式運(yùn)行的數(shù)據(jù)庫(kù),或者運(yùn)行成本或維護(hù)成本超出預(yù)定維護(hù)要求或預(yù)算要求的數(shù)據(jù)庫(kù)。這些要求也適用于表;如果其他用戶(hù)的活動(dòng)或維護(hù)操作限制了數(shù)據(jù)的可用性,則可以認(rèn)為表非常大。例如,如果性能?chē)?yán)重下降,或者每天、每周甚至每個(gè)月的維護(hù)期間有兩個(gè)小時(shí)無(wú)法訪問(wèn)數(shù)據(jù),則可以認(rèn)為銷(xiāo)售表非常大。有些情況下,周期性的停機(jī)時(shí)間是可以接受的,但是通過(guò)更好的設(shè)計(jì)和分區(qū)實(shí)現(xiàn),通常可以避免或最大程度地減少這種情況的發(fā)生。雖然術(shù)語(yǔ) vldb 僅適用于數(shù)據(jù)庫(kù),但對(duì)分區(qū)來(lái)說(shuō),了解表的大小更重要。
除了大小之外,當(dāng)表中的不同行集擁有不同的使用模式時(shí),具有不同訪問(wèn)模式的表也可能會(huì)影響性能和可用性。盡管使用模式并不總是在變化(這也不是進(jìn)行分區(qū)的必要條件),但在使用模式發(fā)生變化時(shí),通過(guò)分區(qū)可以進(jìn)一步改善管理、性能和可用性。還以銷(xiāo)售表為例,當(dāng)前月份的數(shù)據(jù)可能是可讀寫(xiě)的,但以往月份的數(shù)據(jù)(通常占表數(shù)據(jù)的大部分)是只讀的。在數(shù)據(jù)使用發(fā)生變化的類(lèi)似情況下,或在維護(hù)成本隨著在表中讀寫(xiě)數(shù)據(jù)的次數(shù)增加而變得異常龐大的情況下,表響應(yīng)用戶(hù)請(qǐng)求的能力可能會(huì)受到影響。相應(yīng)地,這也限制了服務(wù)器的可用性和可伸縮性。
此外,如果以不同的方式使用大量數(shù)據(jù)集,則需要經(jīng)常對(duì)靜態(tài)數(shù)據(jù)執(zhí)行維護(hù)操作。這可能會(huì)造成代價(jià)高昂的影響,例如性能問(wèn)題、阻塞問(wèn)題、備份(空間、時(shí)間和運(yùn)營(yíng)成本),還可能會(huì)對(duì)服務(wù)器的整體可伸縮性產(chǎn)生負(fù)面影響。
分區(qū)可以帶來(lái)什么幫助?當(dāng)表和索引變得非常大時(shí),分區(qū)可以將數(shù)據(jù)分為更小、更容易管理的部分,從而提供一定的幫助。本文重點(diǎn)介紹橫向分區(qū),在橫向分區(qū)中,大量的行組存儲(chǔ)在多個(gè)相互獨(dú)立的分區(qū)中。分區(qū)集的定義根據(jù)需要進(jìn)行自定義、定義和管理。microsoft sql server 2005 允許您根據(jù)特定的數(shù)據(jù)使用模式,使用定義的范圍或列表對(duì)表進(jìn)行分區(qū)。sql server 2005 還圍繞新的表和索引結(jié)構(gòu)設(shè)計(jì)了幾種新功能,為分區(qū)表和索引的長(zhǎng)期管理提供了大量的選項(xiàng)。
此外,如果具有多個(gè) cpu 的系統(tǒng)中存在一個(gè)大型表,則對(duì)該表進(jìn)行分區(qū)可以通過(guò)并行操作獲得更好的性能。通過(guò)對(duì)各個(gè)并行子集執(zhí)行多項(xiàng)操作,可以改善在極大型數(shù)據(jù)集(例如數(shù)百萬(wàn)行)中執(zhí)行大規(guī)模操作的性能。通過(guò)分區(qū)改善性能的例子可以從以前版本中的聚集看出。例如,除了聚集成一個(gè)大型表外,sql server 還可以分別處理各個(gè)分區(qū),然后將各個(gè)分區(qū)的聚集結(jié)果再聚集起來(lái)。在 sql server 2005 中,連接大型數(shù)據(jù)集的查詢(xún)可以通過(guò)分區(qū)直接受益;sql server 2000 支持對(duì)子集進(jìn)行并行連接操作,但需要?jiǎng)討B(tài)創(chuàng)建子集。在 sql server 2005 中,已分區(qū)為相同分區(qū)鍵和相同分區(qū)函數(shù)的相關(guān)表(如 order 和 orderdetails 表)被稱(chēng)為已對(duì)齊。當(dāng)優(yōu)化程序檢測(cè)到兩個(gè)已分區(qū)且已對(duì)齊的表連接在一起時(shí),sql server 2005 可以先將同一分區(qū)中的數(shù)據(jù)連接起來(lái),然后再將結(jié)果合并起來(lái)。這使 sql server 2005 可以更有效地使用具有多個(gè) cpu 的計(jì)算機(jī)。
分區(qū)的發(fā)展歷史分區(qū)的概念對(duì) sql server 來(lái)說(shuō)并不陌生。實(shí)際上,此產(chǎn)品的每個(gè)版本中都可以實(shí)現(xiàn)不同形式的分區(qū)。但是,由于沒(méi)有為了幫助用戶(hù)創(chuàng)建和維護(hù)分區(qū)架構(gòu)而專(zhuān)門(mén)設(shè)計(jì)一些功能,因此分區(qū)一直是一個(gè)很繁瑣的過(guò)程,沒(méi)有得到充分的利用。而且,用戶(hù)和開(kāi)發(fā)人員對(duì)此架構(gòu)存在誤解(由于其數(shù)據(jù)庫(kù)設(shè)計(jì)比較復(fù)雜),低估了它的優(yōu)點(diǎn)。但是,由于概念中固有的重要性能改善,sql server 7.0 開(kāi)始通過(guò)分區(qū)視圖實(shí)現(xiàn)各種分區(qū)方式,以此來(lái)改進(jìn)這種功能。現(xiàn)在,sql server 2005 為通過(guò)分區(qū)表對(duì)大型數(shù)據(jù)集進(jìn)行分區(qū)又邁出了最大的一步。
對(duì) sql server 7.0 之前的版本中的對(duì)象進(jìn)行分區(qū)
在 sql server 6.5 及以前的版本中,分區(qū)只能通過(guò)設(shè)計(jì)來(lái)完成,還必須內(nèi)置到所有數(shù)據(jù)訪問(wèn)編碼和查詢(xún)方法中。通過(guò)創(chuàng)建多個(gè)表,然后通過(guò)存儲(chǔ)過(guò)程、視圖或客戶(hù)端應(yīng)用程序管理對(duì)正確表的訪問(wèn),通常可以改善某些操作的性能,但代價(jià)是增加了設(shè)計(jì)的復(fù)雜性。每個(gè)用戶(hù)和開(kāi)發(fā)人員都必須知道(并正確引用)正確的表。單獨(dú)創(chuàng)建和管理每個(gè)分區(qū),而使用視圖來(lái)簡(jiǎn)化訪問(wèn);但是這種解決方案對(duì)性能并沒(méi)有太大的改善。使用聯(lián)合視圖簡(jiǎn)化用戶(hù)和應(yīng)用程序訪問(wèn)時(shí),查詢(xún)處理器必須訪問(wèn)每個(gè)基礎(chǔ)表才能確定結(jié)果集所需的數(shù)據(jù)。如果只需要基礎(chǔ)表的有限子集,則每個(gè)用戶(hù)和開(kāi)發(fā)人員都必須了解此設(shè)計(jì),以便只引用相應(yīng)的表。
sql server 7.0 中的分區(qū)視圖
在 sql server 7.0 之前的版本中,手動(dòng)創(chuàng)建分區(qū)所面臨的挑戰(zhàn)主要與性能有關(guān)。盡管視圖可以簡(jiǎn)化應(yīng)用程序設(shè)計(jì)、用戶(hù)訪問(wèn)和查詢(xún)的編寫(xiě),但卻無(wú)法改善性能。而在 sql server 7.0 版本中,視圖結(jié)合了約束,允許查詢(xún)優(yōu)化程序從查詢(xún)計(jì)劃中刪除不相關(guān)的表(即分區(qū)消除),大大降低了聯(lián)合視圖訪問(wèn)多個(gè)表時(shí)的總計(jì)劃成本。
請(qǐng)參見(jiàn)圖 1 中的 yearlysales 視圖。您可以定義十二個(gè)單獨(dú)的表(如 salesjanuary2003、salesfebruary2003 等),然后定義每個(gè)季度的視圖以及全年的視圖 yearlysales,而不是將所有銷(xiāo)售數(shù)據(jù)放到一個(gè)大型表中。
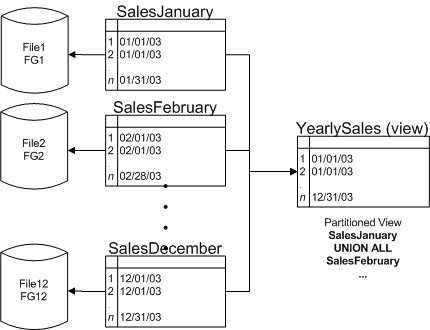
圖 1:sql server 7.0/2000 中的分區(qū)視圖
使用以下查詢(xún)?cè)L問(wèn) yearlysales 視圖的用戶(hù)只會(huì)被引導(dǎo)至 salesjanuary2003 表。
select ys.*
from dbo.yearlysales as ys
where ys.salesdate = '20030113'只要約束可信并且訪問(wèn)視圖的查詢(xún)使用 where 子句根據(jù)分區(qū)鍵(定義約束的列)限制查詢(xún)結(jié)果,sql server 就會(huì)只訪問(wèn)必需的基礎(chǔ)表。受信任的約束是指 sql server 能夠確保所有數(shù)據(jù)符合該約束所定義的屬性的約束。創(chuàng)建約束時(shí),默認(rèn)行為是創(chuàng)建約束 with check。此設(shè)置將導(dǎo)致對(duì)表執(zhí)行架構(gòu)鎖定,以便根據(jù)約束驗(yàn)證數(shù)據(jù)。如果驗(yàn)證結(jié)果表明現(xiàn)有數(shù)據(jù)有效,則添加約束;一旦解除架構(gòu)鎖定,后續(xù)的插入、更新和刪除操作都必須符合正在應(yīng)用的約束。通過(guò)使用此過(guò)程創(chuàng)建受信任的約束,開(kāi)發(fā)人員無(wú)需直接訪問(wèn)(甚至不需要知道)他們感興趣的表,從而大大降低了使用視圖的設(shè)計(jì)的復(fù)雜性。通過(guò)受信任的約束,sql server 可以從執(zhí)行計(jì)劃中刪除不需要的表,從而改善性能。
注意:約束可以通過(guò)各種方式變得“不可信任”;例如,如果未指定 check_constraints 參數(shù)即執(zhí)行批量插入,或者使用 nocheck 創(chuàng)建約束。如果約束不可信任,查詢(xún)處理器將轉(zhuǎn)而掃描所有基礎(chǔ)表,因?yàn)樗鼰o(wú)法確定所請(qǐng)求的數(shù)據(jù)是否真的位于正確的基礎(chǔ)表中。
sql server 2000 中的分區(qū)視圖
盡管 sql server 7.0 大大簡(jiǎn)化了設(shè)計(jì)并改善了 select 語(yǔ)句的性能,但是并沒(méi)有為數(shù)據(jù)修改語(yǔ)句帶來(lái)任何好處。insert、update 和 delete 語(yǔ)句只能針對(duì)基礎(chǔ)表,而不能直接針對(duì)用于聯(lián)合表的視圖。在 sql server 2000 中,數(shù)據(jù)修改語(yǔ)句還可以受益于 sql server 7.0 中引入的分區(qū)視圖功能。由于數(shù)據(jù)修改語(yǔ)句可以使用相同的分區(qū)視圖結(jié)構(gòu),因此,sql server 可以通過(guò)視圖將修改定向至相應(yīng)的基礎(chǔ)表。為了正確配置此設(shè)置,需要對(duì)分區(qū)鍵及其創(chuàng)建設(shè)置額外的限制;但是,基本原理是相同的,因?yàn)?select 查詢(xún)與修改都會(huì)直接發(fā)送給相應(yīng)的基礎(chǔ)表。有關(guān)在 sql server 2000 中進(jìn)行分區(qū)的限制、設(shè)置、配置和最佳方法的詳細(xì)信息,請(qǐng)參見(jiàn) using partitions in a microsoft sql server 2000 data warehouse。
sql server 2005 中的分區(qū)表
盡管 sql server 7.0 和 sql server 2000 中的改進(jìn)大大改善了使用分區(qū)視圖時(shí)的性能,但是并沒(méi)有簡(jiǎn)化分區(qū)數(shù)據(jù)集的管理、設(shè)計(jì)或開(kāi)發(fā)。使用分區(qū)視圖時(shí),必須單獨(dú)創(chuàng)建和管理每個(gè)基礎(chǔ)表(在其中定義視圖的表)。盡管簡(jiǎn)化了應(yīng)用程序設(shè)計(jì)并為用戶(hù)帶來(lái)了好處(用戶(hù)不再需要知道直接訪問(wèn)哪個(gè)基礎(chǔ)表),但是由于要管理的表太多,而且必須為每個(gè)表管理數(shù)據(jù)完整性約束,管理工作變得更復(fù)雜。因?yàn)楣芾矸矫娴膯?wèn)題,通常只有在需要存檔或加載數(shù)據(jù)時(shí)才使用分區(qū)視圖來(lái)分離表。當(dāng)數(shù)據(jù)被移動(dòng)到只讀表或從只讀表中刪除后,操作的代價(jià)變得十分高昂,不僅花費(fèi)時(shí)間、占據(jù)日志空間,通常還會(huì)導(dǎo)致系統(tǒng)阻塞。
另外,由于以前版本中的分區(qū)策略需要開(kāi)發(fā)人員創(chuàng)建各個(gè)表和索引,然后通過(guò)視圖將它們聯(lián)合起來(lái),因此優(yōu)化程序需要驗(yàn)證并確定每個(gè)分區(qū)的計(jì)劃(因?yàn)樗饕赡芤寻l(fā)生變化)。這樣一來(lái),sql server 2000 中的查詢(xún)優(yōu)化時(shí)間通常會(huì)隨著處理的分區(qū)數(shù)增加而直線上升。
在 sql server 2005 中,從定義上講,每個(gè)分區(qū)都擁有相同的索引。例如,請(qǐng)考慮這樣一種方案,即當(dāng)前月份的聯(lián)機(jī)事務(wù)處理 (oltp) 數(shù)據(jù)需要移動(dòng)到每個(gè)月末的分析表中。分析表(用于只讀查詢(xún))是具有一個(gè)群集索引和兩個(gè)非群集索引的表;批量加載 1 gb 數(shù)據(jù)(加載到已建立索引并激活的一個(gè)表中)將使當(dāng)前用戶(hù)遭受系統(tǒng)阻塞的情況,因?yàn)楸砗?或索引變得支離破碎和/或被鎖定。另外,因?yàn)槊總魅胍恍卸夹枰S護(hù)表和索引,所以加載過(guò)程還將耗費(fèi)大量的時(shí)間。雖然可以通過(guò)多種方法加快批量加載的速度,但這些方法可能會(huì)直接影響所有其他用戶(hù),因?yàn)樽非笏俣榷鵁o(wú)法實(shí)現(xiàn)并發(fā)操作。
如果將這些數(shù)據(jù)單獨(dú)放到一個(gè)新創(chuàng)建的(空)且未建立索引(堆)的表中,則可以先加載數(shù)據(jù),而在加載數(shù)據(jù)之后建立索引。通常情況下,使用這種架構(gòu)可以獲得十倍或更好的性能。實(shí)際上,通過(guò)加載未建立索引的表可以利用多個(gè) cpu,因?yàn)榭梢圆⑿屑虞d多個(gè)數(shù)據(jù)文件或從同一個(gè)文件中加載多個(gè)數(shù)據(jù)塊(通過(guò)開(kāi)始和結(jié)束行位置來(lái)定義)。由于兩個(gè)操作都可以通過(guò)并行獲益,因此可以更進(jìn)一步改善性能。
在 sql server 的任何版本中,分區(qū)都使您可以獲得更精確的控制,而且不需要將所有數(shù)據(jù)放到一個(gè)位置;但是,需要?jiǎng)?chuàng)建和管理許多對(duì)象。在以前的版本中,通過(guò)動(dòng)態(tài)創(chuàng)建表、刪除表以及修改聯(lián)合視圖,可以實(shí)現(xiàn)功能性分區(qū)策略。但是,sql server 2005 中的解決方案更加完善:您可以輕松地移入新填充的分區(qū)(作為現(xiàn)有分區(qū)架構(gòu)的額外分區(qū)),還可以移出任何舊分區(qū)。整個(gè)過(guò)程只需要很短的時(shí)間即可完成,通過(guò)使用并行批量加載和并行索引建立,還可以進(jìn)一步提高效率。更重要的是,因?yàn)榉謪^(qū)是在表范圍之外進(jìn)行管理的,所以添加分區(qū)之前不會(huì)對(duì)所查詢(xún)的表造成任何影響。結(jié)果是,添加一個(gè)分區(qū)通常只需要幾秒鐘。
|||需要?jiǎng)h除數(shù)據(jù)時(shí)的性能改善也很顯著。如果一個(gè)數(shù)據(jù)庫(kù)需要一個(gè)滑動(dòng)窗口數(shù)據(jù)集,用于移植新數(shù)據(jù)(例如當(dāng)前月份的數(shù)據(jù))并刪除最早的數(shù)據(jù)(可能是上一年同一月份的數(shù)據(jù)),那么使用分區(qū)可以將數(shù)據(jù)移植的性能提高幾個(gè)數(shù)量級(jí)。雖然這看起來(lái)好像很大,但考慮了未分區(qū)的區(qū)別;當(dāng)所有數(shù)據(jù)位于一個(gè)表中時(shí),刪除 1 gb 的舊數(shù)據(jù)需要對(duì)表及其相關(guān)索引進(jìn)行逐行處理。刪除數(shù)據(jù)的過(guò)程將創(chuàng)建大量的日志活動(dòng),不允許在刪除的過(guò)程中出現(xiàn)日志截?cái)鄦?wèn)題(注意,刪除是一個(gè)自動(dòng)提交的事務(wù);但是,可以通過(guò)盡可能地執(zhí)行多個(gè)刪除操作來(lái)控制事務(wù)的大小),因此,可能需要更大的日志。但是,如果使用分區(qū),刪除相同數(shù)量的數(shù)據(jù)需要從分區(qū)表中刪除特定的分區(qū)(一種元數(shù)據(jù)操作),然后刪除或截?cái)嗒?dú)立的表。
此外,如果不知道如何才能最好地設(shè)計(jì)分區(qū),則不可能認(rèn)識(shí)到將文件組與分區(qū)結(jié)合使用是實(shí)現(xiàn)分區(qū)的理想選擇。文件組允許您將各個(gè)表放置到不同的物理磁盤(pán)上。如果一個(gè)表包含多個(gè)文件(使用文件組),則無(wú)法預(yù)測(cè)數(shù)據(jù)的物理位置。對(duì)于不需要使用并行操作的系統(tǒng)來(lái)說(shuō),sql server 可以在文件組之間更平均地使用所有磁盤(pán),使數(shù)據(jù)具體放在什么位置變得不是那么重要,從而提高系統(tǒng)的性能。
注意:在圖 2 中,一個(gè)文件組包含三個(gè)文件。此文件組中放置了兩個(gè)表,即 orders 和 orderdetails。將表放置到文件組中時(shí),sql server 將根據(jù)文件組中的對(duì)象需要的空間,從每個(gè)文件中獲得盤(pán)區(qū)分配(64-kb 塊,相當(dāng)于八個(gè) 8-kb 頁(yè)面),按比例填充文件組中的文件。創(chuàng)建 orders 和 orderdetails 表時(shí),文件組是空的。創(chuàng)建訂單時(shí),數(shù)據(jù)被輸入到 orders 表中(每個(gè)訂單占據(jù)一行),并且按照每個(gè)明細(xì)項(xiàng)一行的方式輸入到 orderdetails 表中。sql server 將一個(gè)盤(pán)區(qū)分配給文件 1 中的 orders 表,將另一個(gè)盤(pán)區(qū)分配給文件 2 中的 orderdetails 表。orderdetails 表的增長(zhǎng)速度可能比 orders 表快,后續(xù)的分配將轉(zhuǎn)到下一個(gè)需要空間的表中。隨著 orderdetails 表的增長(zhǎng),它將從文件 3 中獲取下一個(gè)盤(pán)區(qū),而 sql server 將繼續(xù)在文件組的文件之間“循環(huán)”下去。在圖 2 中,就是從每個(gè)表到盤(pán)區(qū),再?gòu)拿總€(gè)盤(pán)區(qū)到相應(yīng)的文件組。盤(pán)區(qū)是按照需要的空間進(jìn)行分配的,而根據(jù)流程進(jìn)行編號(hào)。
,歡迎訪問(wèn)網(wǎng)頁(yè)設(shè)計(jì)愛(ài)好者web開(kāi)發(fā)。|||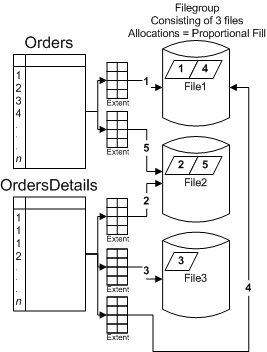
圖 2:使用文件組進(jìn)行分區(qū)填充
sql server 繼續(xù)在文件組中的所有對(duì)象之間平衡分配。如果增加給定操作使用的磁盤(pán)數(shù),雖然 sql server 可以更有效地運(yùn)行,但從管理或維護(hù)的角度來(lái)說(shuō),增加磁盤(pán)數(shù)并非最佳選擇,尤其是在使用模式幾乎可以預(yù)測(cè)(且已隔離)的情況下。因?yàn)閿?shù)據(jù)在磁盤(pán)上的位置并不明確,所以您無(wú)法隔離數(shù)據(jù)以執(zhí)行備份等維護(hù)操作。
通過(guò) sql server 2005 中的分區(qū)表,可以對(duì)表進(jìn)行設(shè)計(jì)(使用函數(shù)和架構(gòu)),從而將具有相同分區(qū)鍵的所有行都直接放置到(且總是轉(zhuǎn)到)特定的位置。函數(shù)用于定義分區(qū)邊界以及放置第一個(gè)值的分區(qū)。在使用 left 分區(qū)函數(shù)時(shí),第一個(gè)值將作為第一個(gè)分區(qū)中的上邊界。在使用 right 分區(qū)函數(shù)時(shí),第一個(gè)值將作為第二個(gè)分區(qū)的下邊界(本文后面將更詳細(xì)地介紹分區(qū)函數(shù))。定義函數(shù)后即可創(chuàng)建分區(qū)架構(gòu),以定義分區(qū)到其數(shù)據(jù)庫(kù)位置的物理映射(根據(jù)分區(qū)函數(shù))。當(dāng)多個(gè)表使用同一個(gè)函數(shù)(但不一定使用同一個(gè)架構(gòu))時(shí),將按類(lèi)似的方式對(duì)具有相同分區(qū)鍵的行進(jìn)行分組。此概念稱(chēng)為對(duì)齊。通過(guò)將來(lái)自多個(gè)表但具有相同分區(qū)鍵的行對(duì)齊到相同或不同的物理磁盤(pán)上,sql server 可以(如果優(yōu)化程序做出此選擇)只處理每個(gè)表中必要的數(shù)據(jù)組。要實(shí)現(xiàn)對(duì)齊,兩個(gè)分區(qū)表或索引所在的相應(yīng)分區(qū)之間必須具有某種對(duì)應(yīng)性。它們必須為分區(qū)列使用等效的分區(qū)函數(shù)。如果滿(mǎn)足以下條件,兩個(gè)分區(qū)函數(shù)則可以用來(lái)對(duì)齊數(shù)據(jù):
• 兩個(gè)分區(qū)函數(shù)使用相同數(shù)量的參數(shù)和分區(qū)。• 每個(gè)函數(shù)中使用的分區(qū)鍵具有相同的類(lèi)型(包括長(zhǎng)度和精度,如果適用,還包括縮放和排序)。
• 邊界值相等(包括 left/right 邊界標(biāo)準(zhǔn))。
注意:即使兩個(gè)分區(qū)函數(shù)都用于對(duì)齊數(shù)據(jù),但如果沒(méi)有在與分區(qū)表相同的列上分區(qū),最后的索引也可能無(wú)法對(duì)齊。
,歡迎訪問(wèn)網(wǎng)頁(yè)設(shè)計(jì)愛(ài)好者web開(kāi)發(fā)。|||排序是一種更強(qiáng)大的對(duì)齊方式,通過(guò)排序,兩個(gè)對(duì)齊的對(duì)象將用一個(gè) equi-join 謂詞連接起來(lái)(equi-join 位于分區(qū)列上)。在可能出現(xiàn) equi-join 謂詞的查詢(xún)、子查詢(xún)或其他類(lèi)似結(jié)構(gòu)的上下文中,這變得很重要。排序之所以重要,因?yàn)樵诜謪^(qū)列上連接表的查詢(xún)一般都非常快。以圖 2 中的 orders 和 orderdetails 表為例,除了按比例填充文件之外,還可以創(chuàng)建映射到三個(gè)文件組的分區(qū)架構(gòu)。定義 orders 和 orderdetails 表時(shí),將它們定義為使用相同的架構(gòu)。具有相同分區(qū)鍵值的相關(guān)數(shù)據(jù)將被放置到同一個(gè)文件中,而將必要的數(shù)據(jù)隔離出來(lái)以便進(jìn)行連接。如果來(lái)自多個(gè)表的相關(guān)行都按照相同的方式進(jìn)行分區(qū),sql server 則可以連接分區(qū),而無(wú)需在整個(gè)表或多個(gè)分區(qū)中(如果表使用了不同的分區(qū)函數(shù))搜索匹配的行。在這種情況下,不僅可以對(duì)齊對(duì)象(因?yàn)樗鼈兪褂孟嗤逆I),還可以按存儲(chǔ)位置對(duì)齊(因?yàn)橄嗤臄?shù)據(jù)位于相同的文件中)。
圖 3 顯示兩個(gè)對(duì)象可以使用相同的分區(qū)架構(gòu),而具有相同分區(qū)鍵的所有數(shù)據(jù)行最后將位于同一個(gè)文件組中。對(duì)齊相關(guān)數(shù)據(jù)后,sql server 2005 可以有效地并行處理大型數(shù)據(jù)集。例如,1 月份的所有銷(xiāo)售數(shù)據(jù)(包括 orders 和 orderdetails 表中的數(shù)據(jù))都位于第一個(gè)文件組中,2 月份的數(shù)據(jù)位于第二個(gè)文件組中,依此類(lèi)推。
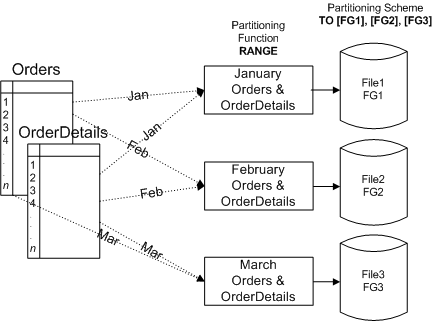
圖 3:按存儲(chǔ)位置對(duì)齊的表
sql server 允許根據(jù)范圍進(jìn)行分區(qū),還允許將表和索引都設(shè)計(jì)為使用相同的架構(gòu),以便更好地對(duì)齊。好的設(shè)計(jì)可以大大提高整體性能,但是,如果數(shù)據(jù)的使用隨著時(shí)間而發(fā)生變化,該怎么辦?如果需要額外的分區(qū),又該怎么辦?簡(jiǎn)化從分區(qū)表外部添加分區(qū)、刪除分區(qū)和管理分區(qū)等方面的管理工作是 sql server 2005 的主要設(shè)計(jì)目標(biāo)。
國(guó)內(nèi)最大的酷站演示中心!sql server 2005 已經(jīng)考慮了如何簡(jiǎn)化分區(qū)的管理、開(kāi)發(fā)和使用。它在性能和可管理性方面有以下優(yōu)點(diǎn):
• 簡(jiǎn)化了需要進(jìn)行分區(qū)以改善性能或可管理性的大型表的設(shè)計(jì)和實(shí)現(xiàn)。
• 將數(shù)據(jù)加載到現(xiàn)有分區(qū)表的新分區(qū)中時(shí),最大程度地減少了對(duì)其他分區(qū)中的數(shù)據(jù)訪問(wèn)的影響。
• 將數(shù)據(jù)加載到現(xiàn)有分區(qū)表的新分區(qū)中時(shí),性能相當(dāng)于將同樣的數(shù)據(jù)加載到新的空表中。
• 在存檔和/或刪除分區(qū)表的一個(gè)分區(qū)時(shí),最大程度地減少了對(duì)表中其他分區(qū)的訪問(wèn)的影響。
• 允許通過(guò)將分區(qū)移入和移出分區(qū)表來(lái)維護(hù)分區(qū)。
• 提供了更好的伸縮性和并行性,可以對(duì)多個(gè)相關(guān)表執(zhí)行大量操作。
• 改善了所有分區(qū)的性能。
• 縮短了查詢(xún)優(yōu)化時(shí)間,因?yàn)椴恍枰獑为?dú)優(yōu)化每個(gè)分區(qū)。
定義和術(shù)語(yǔ)
要在 sql server 2005 中實(shí)現(xiàn)分區(qū),必須了解一些新的概念、術(shù)語(yǔ)和語(yǔ)法。要理解這些新概念,首先我們看一下與創(chuàng)建和放置操作有關(guān)的表結(jié)構(gòu)。在以前的版本中,表通常是一個(gè)物理和邏輯概念,但使用 sql server 2005 分區(qū)表和索引,您在存儲(chǔ)表的方式和位置方面就有了多種選擇。在 sql server 2005 中,可以使用以前版本中的相同語(yǔ)法創(chuàng)建表和索引,作為一個(gè)表結(jié)構(gòu)放置到 default 文件組或用戶(hù)定義的文件組中。另外,在 sql server 2005 中,還可以根據(jù)分區(qū)架構(gòu)創(chuàng)建表和索引。分區(qū)架構(gòu)可以將對(duì)象映射到一個(gè)或多個(gè)文件組。為了確定數(shù)據(jù)的相應(yīng)物理位置,分區(qū)架構(gòu)將使用了分區(qū)函數(shù)。分區(qū)函數(shù)定義了用來(lái)定向行的算法,而架構(gòu)則將分區(qū)與其相應(yīng)的物理位置(即文件組)相關(guān)聯(lián)。換句話說(shuō),表仍然是一個(gè)邏輯概念,但與以前的版本相比,表在磁盤(pán)上的物理位置有了很大的不同;表還可以擁有架構(gòu)。
|||范圍分區(qū)
范圍分區(qū)是按照特定和可定制的數(shù)據(jù)范圍定義的表分區(qū)。范圍分區(qū)的邊界由開(kāi)發(fā)人員選擇,還可以隨著數(shù)據(jù)使用模式的變化而變化。通常,這些范圍是根據(jù)日期或排序后的數(shù)據(jù)組進(jìn)行劃分的。
范圍分區(qū)主要用于數(shù)據(jù)存檔、決策支持(當(dāng)通常只需要特定范圍內(nèi)的數(shù)據(jù)時(shí),例如給定的月份或季度)以及組合的 oltp 和決策支持系統(tǒng) (dss)(數(shù)據(jù)使用在行的生命周期內(nèi)會(huì)發(fā)生變化)。sql server 2005 分區(qū)表和索引的最大優(yōu)點(diǎn),尤其是在存檔和維護(hù)方面,就是可以管理特定范圍內(nèi)的數(shù)據(jù)。通過(guò)范圍分區(qū),可以非常快速地存檔和替換舊的數(shù)據(jù)。當(dāng)數(shù)據(jù)訪問(wèn)通常用于對(duì)大范圍數(shù)據(jù)的決策支持時(shí),最適合使用范圍分區(qū)。在這種情況下,數(shù)據(jù)所在的具體位置至關(guān)重要,這樣才能在需要時(shí)只訪問(wèn)相應(yīng)的分區(qū)。另外,由于事務(wù)數(shù)據(jù)已經(jīng)可用,因此可以輕松快捷地添加數(shù)據(jù)。范圍分區(qū)最初定義起來(lái)很復(fù)雜,因?yàn)樾枰獮槊總€(gè)分區(qū)定義邊界條件。此外,還需要?jiǎng)?chuàng)建一個(gè)架構(gòu),將每個(gè)分區(qū)映射到一個(gè)或多個(gè)文件組。但是,它們通常具有一致的模式,因此,定義后很容易通過(guò)編程方式進(jìn)行維護(hù)(參見(jiàn)圖 4)。
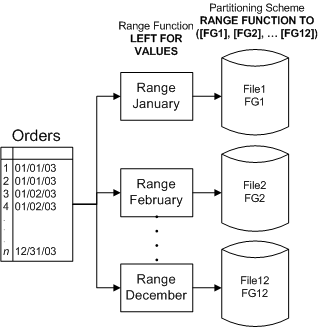
圖 4:具有 12 個(gè)分區(qū)的范圍分區(qū)表
定義分區(qū)鍵
對(duì)表和索引進(jìn)行分區(qū)的第一步就是定義分區(qū)的關(guān)鍵數(shù)據(jù)。分區(qū)鍵必須作為一個(gè)列存在于表中,還必須滿(mǎn)足一定的條件。分區(qū)函數(shù)定義鍵(也稱(chēng)為數(shù)據(jù)的邏輯分離)所基于的數(shù)據(jù)類(lèi)型。函數(shù)只定義鍵,而不定義數(shù)據(jù)在磁盤(pán)上的物理位置。數(shù)據(jù)的位置由分區(qū)架構(gòu)決定。換句話說(shuō),架構(gòu)將數(shù)據(jù)映射到一個(gè)或多個(gè)文件組,文件組將數(shù)據(jù)映射到特定的文件,文件又將數(shù)據(jù)映射到磁盤(pán)。分區(qū)架構(gòu)通常使用函數(shù)來(lái)實(shí)現(xiàn)此目的:如果函數(shù)定義了五個(gè)分區(qū),則架構(gòu)必須使用五個(gè)文件組。文件組不需要各不相同;但是,如果擁有多個(gè)磁盤(pán)(最好是多個(gè) cpu),使用不同的文件組可以獲得更好的性能。將架構(gòu)與表一起使用時(shí),您需要定義用作分區(qū)函數(shù)的參數(shù)的列。
新聞熱點(diǎn)






疑難解答
圖片精選













