hexdump命令一般用來查看"二進(jìn)制"文件的十六進(jìn)制編碼,從手冊(cè)上查看,其查看的內(nèi)容還要很多,諸如:ascii, decimal, hexadecimal, octal
參數(shù):
hexdump [-bcCdovx] [-e format_string] [-f format_file] [-n length] [-s skip] file
示例:
新增一個(gè)文本文件,在test 文本中添加如下內(nèi)容:
[root@node61 test]# cat test abcdeABCDE
1)最簡(jiǎn)單的查看
[root@node61 test]# hexdump test 0000000 6261 6463 0a65 4241 4443 0a45 000000c
第一列:表示文件文件偏移量
第二列:已兩個(gè)字節(jié)為一組的十六進(jìn)制
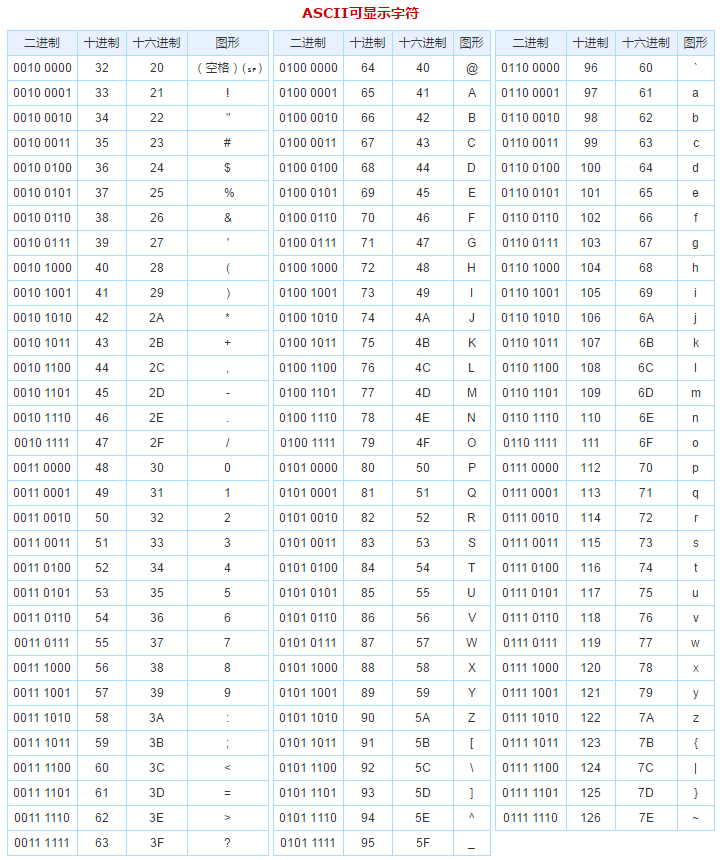
通過上面的輸出,翻譯成文本為:badc0aeBADC0aE(注意:在Linux中換行符/n 的十六進(jìn)制為0a,在windows中,換行為/r/n的十六進(jìn)制編碼為:0d 0a),另:下圖為ASC碼表對(duì)應(yīng)的進(jìn)制編碼
細(xì)心的讀者可能已經(jīng)發(fā)現(xiàn)了,為什么翻譯成文本成倒序了呢?文本中的內(nèi)容不是:abcde
ABCDE 嗎?
其實(shí)這是X86的CPU架構(gòu)所致,又進(jìn)行了一番研究:字節(jié)序
字節(jié)序:其實(shí)就是字節(jié)的順序,這里是針對(duì)大于兩個(gè)字節(jié)來說,一個(gè)字節(jié)就沒有排序而言了,然而,在大部分的工作中,我們都很少直接和字節(jié)序打交道。
字節(jié)序分類兩類:Big-Endian 和Little-Endian
相關(guān)定義如下:
i) Little-Endian就是低位字節(jié)排放在內(nèi)存的低地址端,高位字節(jié)排放在內(nèi)存的高地址端。(X86 CPU系列采用的位序)
ii) Big-Endian就是高位字節(jié)排放在內(nèi)存的低地址端,低位字節(jié)排放在內(nèi)存的高地址端。
iii) 網(wǎng)絡(luò)字節(jié)序:TCP/IP各層協(xié)議將字節(jié)序定義為Big-Endian,因此TCP/IP協(xié)議中使用的字節(jié)序通常稱之為網(wǎng)絡(luò)字節(jié)序。
下面的這個(gè)程序是用來判斷CPU采用的是哪種模式?
#include<stdio.h>int main(){union w { int a; char b; } c; c.a = 1; if (c.b==1){printf("The CPU is Litle-Endian/n");}else{printf("The CPU is Big-Endian/n");}return 0;} /* end checkCPU*/gcc -o checkCPU.o checkCPU.c[root@node61 test]# ./checkCPU.o The CPU is Litle-Endian本人本地虛擬機(jī)的是X86的小端模式的
至此上面使用hexdump為什么是順序是倒著的原因了
有沒有更加較便于方便的查看方式了?有,這也是較常用的方式,見下面的b)介紹;
b)以16進(jìn)制和相應(yīng)的ASCII字符顯示文件里的字符
[root@node61 test]# hexdump -C test #常用00000000 61 62 63 64 65 0a 41 42 43 44 45 0a |abcde.ABCDE.|0000000c
這里既能顯示16進(jìn)制也能顯示ascii碼
c)以偏移量格式輸出,參數(shù) -s
[root@node61 test]# hexdump -C test 00000000 61 62 63 64 65 0a 41 42 43 44 45 0a |abcde.ABCDE.|0000000c[root@node61 test]# hexdump -C -s 6 test 00000006 41 42 43 44 45 0a |ABCDE.|0000000c
第一行的abcde換行 的字符都沒有了
其他hexdump還有很多的用法,具體可以參看man hexdump
以上就是本篇文章的全部?jī)?nèi)容,如果還有其他問題和不明白的地方可以給我們投稿或者在下方留言。
新聞熱點(diǎn)






疑難解答
圖片精選