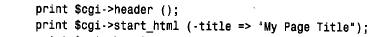,歡迎訪問網頁設計愛好者web開發。 迄今為止,我們編寫的dbi 腳本用于命令行環境中的命令解釋程序,但dbi 在其他環境下也是有用的,例如在基于web 的應用程序的開發中。當編寫能從web 瀏覽器調用的dbi腳本時,就打開了新鮮而有趣的與數據庫交互的性能。 例如,如果以表格的形式顯示數據,則可以很容易地把每個列標題轉換為可以選擇的連接,以便將該列的數據重新排序。它允許單擊一次就可以以不同的方式查看數據,而又不必鍵入任何查詢。或者可以提供一種用戶可以為數據庫搜索而鍵入的標準格式,然后,顯示含 有搜索結果的頁面。像這種簡單的能力能夠特別地改變為訪問數據庫內容而提供的交互性的水平。除此之外,web 瀏覽器的顯示能力比在終端窗口獲得的能力要明顯地更好一些,所以,輸出也經常看起來更漂亮。 在這部分,我們將創建下面的基于web 的腳本: samp_db 數據庫中表的通用瀏覽器。這與我們想對這個數據庫完成的任何特定的任務無關,但是它舉例說明了若干web 程序設計概念,并提供了一種查看這些表所含有的信息的方便方式。 允許我們查看任何給定的測驗或測試分數的分數瀏覽器。它作為回顧評分事件結果的快速方式是很方便的,并且當我們需要創建測試的等級曲線時,它是有用的,所以我們可以以字母等級來標記試卷。 尋找分享共同興趣的歷史同盟成員的腳本。通過允許用戶輸入搜索短語來完成它,然后在member 表的interests 域來搜索短語。我們已經編寫了一個行命令腳本來做這些,但是,基于web 的版本提供了有指導意義的參考觀點,允許對同一任務比較兩種方法。 我們將使用cgi.pm perl 模塊來編寫這些腳本,這個模塊是將dbi 腳本連接到web 上最容易的方法(有關獲得cgi.pm 模塊的說明,請參閱附錄a)。之所以稱為c g i . p m,是因為它有助于編寫使用公共網關協議的腳本,這個協議定義了web 服務器如何與其他程序通信。cgi.pm 處理涉及了許多通用內務處理的任務細節,如收集通過web 服務器傳遞到腳本的作為輸出的參數值。cgi.pm 也提供了生成html 輸出的便利方法,與編寫自己原始的h t m l 標記相比,它減少了編寫難看的html 的機會。 在本章中,您將學到足夠有關cgi.pm 的知識來編寫自己的web 應用程序,但是,當然不是它所包括的所有性能。要想學習有關這個模塊的更多知識,請參閱lincoln stein (john wiley 1998 出版) 撰寫的《o fficial guide to programming with cgi.pm》,或在以下網址查閱聯機文檔: http://stein.cshl.org/www/software/cgi/
設置cgi 腳本的apache
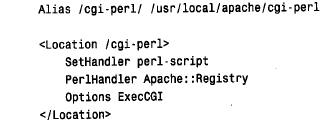
除了dbi 和cgi.pm 之外,編寫基于web 的腳本還需要有一個以上的組件:web 服務器。這里的說明適合apache 服務器使用腳本,但是,如果愿意,稍微改編一點這些說明,就可以使用不同的服務器。 一般來說,apache 裝置的各個部分位于/usr/local/apache 目錄。對我們的目的來講,這個目錄中最重要的子目錄為h t d o c s(html 文檔樹)、cgi-bin (可執行的腳本和we b服務器調用的程序),和c o n f(配置文件)。這些目錄也可能放在系統中的其他地方。如果是這樣,則要對下面的注意事項做適當的調整。 應該驗證cgi-bin 目錄不在apache 文檔樹的內部,以便它內部的這些腳本不能作為無格式文本來請求。這是個安全的防范方法。您也不愿意讓懷有惡意的客戶機程序檢查您的腳本,通過提取這些腳本的文本并研究它們來作為安全的突破口。 要想安裝以apache 方式使用的cgi 腳本,則將它放在cgi-bin 目錄下,然后將這個腳本的所有權更改為運行apache 的用戶,并將它的模式更改為對該用戶為可執行的和只讀的模式。例如,如果apache 以名稱為www 的用戶方式運行,則使用下面的命令: % chown www script_name % chmod 500 script_name 可能需要用www 或root 運行這些命令。如果不允許在cgi-bin 目錄下安裝腳本,則可以請求系統管理員代表您來這樣做。 安裝這個腳本之后,通過向web 服務器發送適當的u r l,可以請求瀏覽器上的這個腳本。典型的url 是這樣的: http://your.host.name/cgi-bin/script_name 從web 瀏覽器請求腳本會導致web 服務器執行它。返回腳本的輸出,結果作為we b 頁面出現在瀏覽器中。 如果為尋求更好的性能而使用具有mod_perl 的cgi 腳本,則可以這樣做: 1) 確保至少有以下版本的必需軟件: perl 5.004、cgi.pm 2.36和mod_perl 1.07。 2) 確保將mod_perl 編譯為apache 可執行的文件。 3) 建立一個存儲腳本的目錄。我使用了/usr/local/apache/cgi-perl。cgi-bin 不應該位于apache文檔樹的內部,出于同樣的安全原因, cgi-perl目錄也不應該在那里。 4) 告知apache,與位于cgi-perl 目錄中的腳本mod_perl 相關聯: 如果正在使用apache 的當前版本,這個版本使用單個的配置文件,則將所有這些指示放在httpd.conf 中。如果apache 的版本使用三個舊文件的方法來配置信息,則將a l i a s指示放入srm.conf 中,將location 行放入access.conf 中。對于cgi-perl 目錄,不要啟用m o d _ per l、perlsendheader 或perlsetupenv 指示。這些由cgi.pm 自動地處理,啟用它們可能導致處理沖突。 mod_perl 腳本的url 與標準的cgi 腳本的url 相類似。唯一的不同之處在于指定cgi - perl 而不是cgi - bin。 http://your.host.name/cgi-perl/script_name 有關的詳細信息,請參閱下面地址的apache web 站點的mod_perl 區域: http://perl.apache.org/
cgi.pm 的簡要介紹
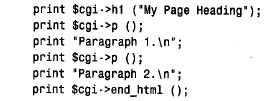
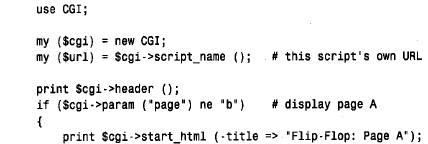
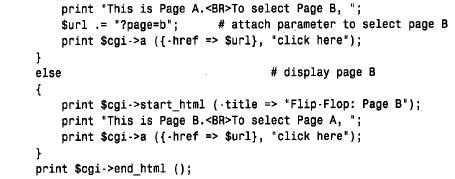
為了編寫使用cgi.pm 模塊的perl 腳本,將use 行放在這個腳本的開頭附近,然后創建讓您訪問cgi.pm 方法和變量的cgi對象: use cgi; my($cgi)=new cgi; 我們的cgi 腳本使用了cgi.pm 的性能,它通過使用$cgi 變量調用方法來實現。例如,為了生成級別1標題,我們將這樣使用h1( ) 方法: print $cgi->h1("my heading"); cgi.pm 也支持允許以函數調用它的方法的使用風格,而不用前導的‘ $ c g i - >’。在這里,我沒有使用這個語法,是因為‘ $ c g i - >’符號更類似于使用dbi 的方式,還因為它防止c g i . p m函數名與可以定義的任何函數名產生沖突。 1. 檢查輸入參數,并編寫輸出 cgi.pm 所做的事情之一就是照看所有丑陋的細節,這些細節涉及到收集由we b服務器向腳本提供的輸入信息。為了獲得那些信息,所需做的就是調用param( ) 方法。可以如下獲得所有可用的參數名: my (@param)=$cgi->param(); 為了檢索特定參數的值,只命名感興趣的參數: cgi.pm還提供生成傳送給客戶機瀏覽器的輸出方法。考慮下面的html文檔: 這個代碼使用$cgi來產生等價的文檔: 使用cgi.pm 生成輸出,而不是編寫自己原始的h t m l,這樣做的一些優點是,可以按邏輯單元考慮,而不是按單獨的組成標識來考慮,而且html 不太可能含有錯誤(我說“不太可能”的原因是cgi.pm 不禁止做古怪的事情,如含有一列內部的標題)。除此之外,對于 編寫的非標記文本,cgi.pm 提供自動的字符轉義,如html 中指定的‘<’和‘>’。 如果愿意,cgi.pm 生成輸出方法的使用并不排斥編寫自己原始的h t m l。可以將這兩種方法混合起來,組合調用具有生成文字標識的顯示語句的cgi.pm 方法。 2. 轉義的html 和url 文本 如果經cgi.pm 方法,如start_html( ) 或h1( ),編寫非標記的文本,則自動地轉義文本中的特定字符。例如,如果使用下面的語句生成標題,則標題文本中的‘ &’字符將由c g i . p m 轉換為‘& a m p ;’: print $cgi->start_html (-title=>"a,b&c"); 如果不使用cgi.pm 生成輸出的方法編寫非標記的文本,則可能應該先讓它經過escapehtml( ) ,以便確保可以正確地轉義任何指定的字符。當構造可能含有特定字符的url 時也是這樣,盡管在那種情況下應該使用escape( ) 方法來代替它。使用適當的編碼方法是很重要的,因為每種方法都將不同的字符集作為特殊的字符來對待,并使用彼此不同的格式來對待特殊的字符編碼。考慮下面簡短的perl 腳本: 如果運行這個腳本,則它生成下面的輸出,從這里可以看到html 文本的編碼不同于url 的編碼: 3. 編寫多目的頁面 編寫基于web 的腳本來生成h t m l,而不是編寫靜態的html 文檔的主要原因之一是,根據調用方式,腳本可以產生不同類型的頁面。我們將要編寫的所有cgi 腳本都有這種特性。每一個都像下面這樣操作: 1) 當從瀏覽器第一次請求這個腳本時,它生成一個初始頁面,允許選擇想要的信息類型。 2) 當做了選擇以后,重新調用這個腳本,但是,這次它在第二頁檢索,并顯示請求的特定信息。 這里的主要問題是想從第一頁的選擇中確定第二頁的內容,但是,通常web 頁面是彼此獨立的,除非安排某些特定排列的次序。這個竅門是讓腳本生成頁面,這個頁面給參數設置一個值,告訴這個腳本的下一個調用想要的內容。當第一次調用這個腳本時,這個參數沒有 值;告訴這個腳本給出它的初始頁面。當指出想看的信息內容時,這個頁面再一次調用這個腳本,但是,將參數設為指示這個腳本做什么的一個值。 將說明從頁面傳送回腳本有不同的方式。一種方式是提供一種用戶填寫的表格。當用戶提交這張表格時,將它的內容提交給web 服務器。服務器將信息傳遞給腳本,這個腳本通過調用param( ) 方法,能夠找出提交的內容。這就是我們對第三個cgi 腳本所做的事情(允許用戶輸入搜索歷史同盟目錄的關鍵字)。 對腳本指定說明的另外一種方法是,當請求腳本時,將信息作為發送到we b服務器的u r l的一部分來傳遞。這就是我們對于samp_db 表瀏覽器和分數瀏覽器腳本要做的事情。這種工作方式是腳本生成含有超鏈接的頁面。選擇一個連接,再次調用這個腳本,但是,這次 指定參數值,這個參數值指示這個腳本做什么。實際上,這個腳本以不同的方式調用它本身,來提供不同類型的結果,這取決于用戶所選擇的連接。 腳本可以允許通過向瀏覽器向它自己的url 傳送一個含有超鏈接的頁面來調用它本身。例如,腳本my_script 可以編寫含有如下這樣連接的頁面: <a href="/cgi-bin/my_script">click me!</a> 當用戶敲入文本“ click me!”時,用戶瀏覽器就請求將my_script 發送回web 服務器。當然,所有這些會導致腳本再次發送出同一個頁面,因為它不支持其他信息。然而,如果將一個參數附加到url 上,則當用戶選擇這個連接時,將這個參數送回web 瀏覽器。服務器 調用這個腳本,這個腳本可以調用param ( ) 來偵測設置的參數,并根據它的值采取行動。 為了把參數附到url 的末尾,加一個“?”字符放到名稱/值的前面。為了附上多個參數,用字符“&”分隔。例如: /cgi-bin/my_script?name=value /cgi-bin/my_script?name=value&name2=value2 為了構造帶有附加參數的自引用的u r l,c g i腳本應該通過調用script_name ( ) 方法獲得自己的u r l來開始,然后像按照如下方法添加參數: 在構造u r l之后,通過使用cgi.pm 的a( ) 方法,可以生成一個包括它的超鏈接<a> 標記: print $cgi->a ({.href=>$url},"click me!); 通過檢查一個簡短的cgi 腳本來查看如何工作會更容易。第一次調用時,下面的腳本f l i p _ f l o p,給出了一個含有單個超鏈接的稱為頁面a 的頁面。選擇這個連接再次調用這個腳本,但是設置page 參數,告訴它顯示頁面b。頁面b也包括對腳本的連接,但是page 參數沒有值。因此,在頁面b中選擇這個連接導致重新顯示原始頁面。隨后的腳本調用將頁面在腳本a和腳本b之間來回切換: 如果另一個客戶機程序出現并請求f l i p _ f l o p,就給出初始頁面,因為不同客戶機的瀏覽器并不互相影響。 實際上,$url 的值被前面的樣例設置成漂亮的風格。在把它們放在url 之后以免包括特殊字符時,使用escape( ) 方法對參數名和值進行編碼是比較好的。這里有一個較好的方法來用附加的參數值來構造u r l:
從web 腳本連接到mysql服務器
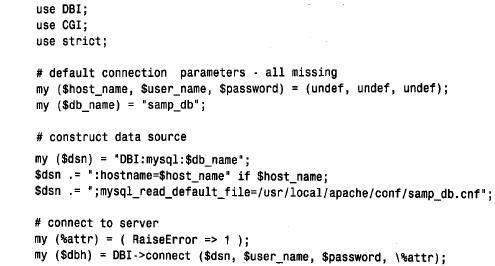
我們在前一節“運行dbi”中開發的命令行腳本,為建立到mysql服務器的連接共享了一個通用的前文。cgi 腳本也共享了一些代碼,但是有一些不同: 這個前文與命令行腳本使用的前文的不同之處在于以下幾個方面: 第一部分現在含有一條use cgi 語句。 不再分析命令行的參數。 代碼仍然在可選文件中尋找連接參數,但是,在用戶執行腳本的主目錄中不使用.my.cnf 文件(也就web 服務器用戶的主目錄)。web 服務器可能運行訪問其他數據庫的腳本,沒有理由假設所有腳本會使用同一連接參數。相反,我們尋找不同位置存放的可選文件( / us r / l o c a l / a p a c h e / c o n f / samp_db . c n f)。如果想使用不同的文件,應該修改可選文件的路徑名。 通過web 服務器調用的腳本作為web 服務器用戶,而不是作為您來運行。這就提出了一些安全問題,因為在web 服務器接管之后您就不再控制了。應該把可選文件的所有權交給運行web 服務器的用戶(可能是www 或者nobody 或者一些類似的用戶),并將模式設置為4 0 0 或6 0 0,以便其他用戶不能讀取。不幸的是,可以安裝這個web 服務器的腳本來執行的任何人仍然能夠讀取這個文件。他們要做的所有事情就是編寫一個腳本,顯式地打開可選文件,并在we b頁面上顯示它的內容。因為他們的腳本作為we b服務器用戶來運行,所以它將有足夠的權利來讀取這個文件。 由于這個原因,創建一個對samp_db 數據庫具有只讀( s e l e c t)權限的mysql用戶,然后在samp_db.cnf 文件中列出這個用戶的名稱和口令,而不是您自己的名稱和口令,這種行為是很謹慎的。作為有權修改數據庫的表的用戶,這種方式不會冒險允許腳本連接到數據庫。第11章“常規的mysql管理”,討論了如何創建具有嚴格權限的mysql用戶賬戶。 另一種選擇,可以在apache 的suexec 機制下安排執行腳本。這就允許作為特殊權限的用戶執行腳本,然后編寫腳本,從只對那個用戶為只讀的可選文件中獲得連接參數。例如,需要編寫訪問數據庫的腳本,就可以這樣做。 還有另外一種方法就是編寫腳本,從客戶機用戶請求用戶姓名和口令,并使用這些值建立到mysql服務器的連接。這種方法對于為管理目的而創建腳本比對于為一般使用提供腳本更適合。無論如何,應該警惕用戶名和口令請求的一些方法受到一些人的攻擊,這些人可 能在您和服務器之間的網絡上安放竊聽器。 因為可以從前面的段落中搜集,所以web 腳本的安全性是個棘手的問題。很明顯,應該多讀一些有關安全的主題,因為它是一個大的主題,所以在這里我不能真正做得很全面。查看apache 手冊中有關安全性的資料是一種好的方法。您也可以查找www 安全性的faq 說 明,例如可以使用下面的網址: http://www.w3.org/security/faq/
samp_db數據庫瀏覽器
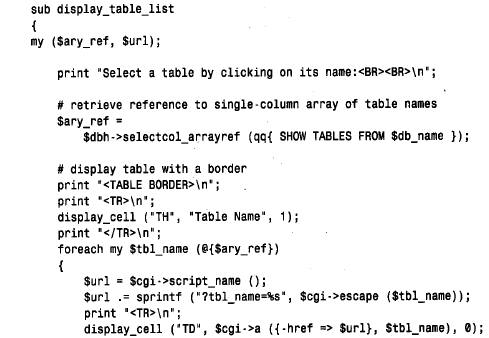
對于第一個基于web 的應用程序,我們將開發一個簡單的腳本— samp_db — 允許查看samp_db 數據庫中存在的表,并從web 瀏覽器中交互式地檢查這些表中的內容。samp_db的工作方式如下: 當首次從瀏覽器中請求samp_db 時,它連接到mysql服務器,在samp_db 數據庫中檢索一列表,并向瀏覽器發送一個頁面,在這個頁面中出現的每個表都作為可選擇的連接。當選擇這個頁面中的一個表名時,榔骶拖騑eb 服務器發送一個請求,請求samp_browse 顯示那個表的內容。 當調用samp_browse 時,如果它收到從web 服務器發來的一個表名,則它就檢索這個表的內容,并將信息顯示在web 瀏覽器上。數據每列的標題就是表中列的名稱。標題作為連接出現;如果選擇它們中的一個,則瀏覽器就向web 服務器發送一個請求,顯示同樣的表,但按選擇的列排序。 注意,這里有個警告: samp_db 表中的這些表相對較小,因此向瀏覽器發送表的全部內容并不是大問題。如果編輯samp_db,顯示包含大型表的不同數據庫中的表,則應該考慮向行檢索語句中增加一個l i m i t子句。 在samp_browse 腳本的主體中,我們創建了cgi 對象,并取消了web 頁面的初始部分。然后檢查是否按我們的假設,根據tbl_name 參數值顯示了一些特定的表: 很容易找出參數的值,因為cgi.pm 做了找出web 服務器傳遞給這個腳本信息的全部工作。我們只需調用具有我們感興趣的參數名的param( ),在s a m p _ b r o w s e的主體中,這個參數為tbl_name。如果它沒有定義或者為空,則它就是這個腳本的初始調用,我們顯示這個表列。否則,就顯示由tbl_name 參數命名的表的內容,由sort_column 參數命名的列值排序。顯示適當的信息之后,我們調用end_html( ) 消除結束的html 標志。 display_table_list( ) 函數生成初始頁面。display_table_list( ) 檢索這個表列并寫出在每個單元中都含有一個數據庫表名的單列的h t m l表: display_table_list( ) 生成的頁面含有如下連接: 當調用samp_browse 時,如果tbl_name 參數有值,則這個腳本將這個值傳遞給display_table( ),連同按名稱排序后的列名。如果沒有命名的列,則我們按第一列排序(我們可以通過位置引用列,因而很容易地使用order by 1子句來完成): 表顯示了與重新顯示該表的連接相關的列標題的頁面;這些連接包括sort _ c o l um n參數,它顯式地指定排序的列。例如,對于顯示event 表內容的頁面,列標題連接看起來如下所示: display_table_list( ) 和display_table( ) 都使用了display_cell( ),h t m l表中作為單元顯示值的實用程序函數。這個函數使用了一個小竅門,就是將空值轉換為不可分的空格(‘& n b s p ;’),因為在帶有邊框的表中,空單元不會正確地顯示邊框。將不可分的空格放入這個單元中解決了這個問題。display_cell( ) 還具有控制是否將單元值編碼的第三個參數。這是必需的,因為調用display_cell( ),顯示了一些已經編碼的單元值,如含有url 信息的列標題: 如果想編寫更通用的腳本,可以將samp_browse 更改為瀏覽多個數據庫。例如,在腳本開始時,可以顯示服務器上的一列數據庫,而不是一個特定數據庫中的一列表。然后,選出一個數據庫,獲得它的一列表,再從那里繼續。
學分保存方案分數瀏覽器
每當我們輸入測試的分數時,都需要生成一個有序的分數列表,以便確定等級曲線,并分配字母等級。請注意,對于這個列表我們將做的所有事情就是顯示它,以便能確定每個字母等級終止的位置。然后在返回給學生之前,在測試卷上標出等級分數。我們不在數據庫中 繼續記錄這個字母等級,因為在等級周期末尾的等級取決于數字分數,而不是字母等級。再請注意,嚴格地說,在創建檢索分數的方法之前,就應該有一個輸入分數的方法。我將輸入分數的腳本一直保存到下一章。在這期間,在數據庫中,我們已經從早期的等級周期部分中 得到了幾組分數。即使沒有方便的分數輸入方法,我們也可以使用具有那些分數的腳本。 我們瀏覽分數的腳本score_browse 與samp_browse 有些類似,但是希望查看給定測試或測驗的分數這種更特定的目標。初始頁面給出一列可以從中選擇的可能的等級事件,允許用戶選擇它們中的任何一個,來查看與事件相關的分數。給定事件的分數按照高分在前的順序按分數排序,因此可以顯示出結果,并用它確定等級曲線。 score _ b r o w s e只需要檢查一個參數e v e n t _ i d,查看是否指定了特定事件。如果不是,則score_browse 就顯示event 表中的行,以便用戶可以選擇其中的一個。否則,就顯示與所選事件相關的分數: 使用請求表列標題的列名,函數display_events( ) 從event 表中抽取信息,并以表格形式顯示它。在每行的內部,顯示event_id 值,作為可以選擇的連接,以觸發檢索相應事件分數的查詢。每個事件的url 都只是到具有附加參數score _ b r o w s e的路徑,這個參數指定事件號碼: /cgi-bin/score_browse?event_id=number display_events( ) 函數編寫如下: 當用戶選擇事件時,瀏覽器發送一個具有附加事件id 值的score_browse 請求。score_browse 找到event_id 參數集,并調用display_scores( ) 列出所有特定事件的分數。這個頁面也顯示了文本“ show event list”,作為返回初始頁面的連接,以便用戶能很容易地返回事件列表頁面。這個連接的url 引用了score_browse 腳本,但不指定event_id 參數的任何值。display_scores( )子程序如下所示: display_scores( ) 運行的查詢與我們以前在第1章的1. 4 . 8節中的“從多個表中檢索信息”小節中開發的說明如何編寫連接的查詢極為類似。在那一章中,我們請求給定日期的分數,因為日期比事件的id值更有意義。相反,當我們使用score_browse 時,知道了精確的事件id。那不是因為我們按照事件id 考慮(我們沒有),而是因為腳本給了我們一列可從中選擇的事件id。可以看到這種類型的接口減少了了解特定細節的需要。我們不必了解事件的id;只需要識別出想要的事件。