首頁| 新聞| 娛樂| 游戲| 科普| 文學| 編程| 系統| 數據庫| 建站| 學院| 產品| 網管| 維修| 辦公| 熱點
顯卡壞了會出現什么情況
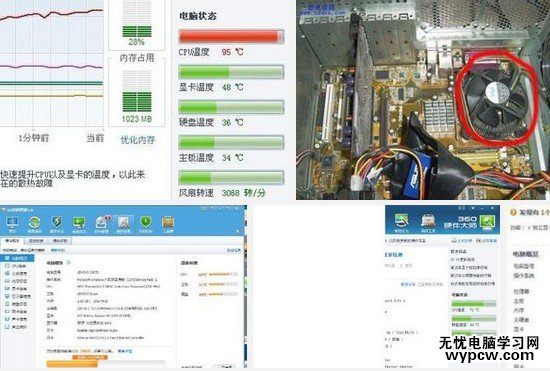
散熱問題引發的CPU高占用率問
內存條松動導致的故障現象及解決辦法
校園甜美的背影,洋溢著青春爛漫的回憶
芭蕾舞蹈表演,真實美到極致
游覽三河古鎮景點:望月閣、古民居、一人巷
大蜀山森林公園美景
肉食主義者的最愛美食烤肉圖片
夏日甜心草莓美食圖片
人逢知己千杯少,喝酒搞笑圖集
搞笑試卷,學生惡搞答題
新聞熱點
疑難解答
圖片精選
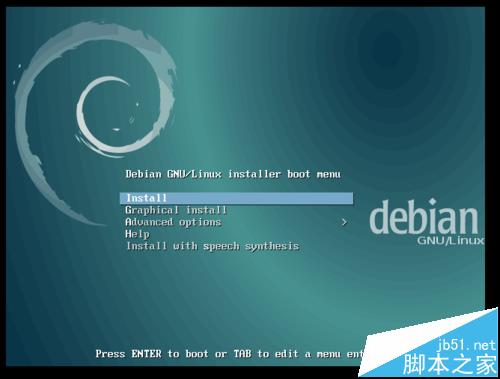
linux系統安裝出錯提示this kernel
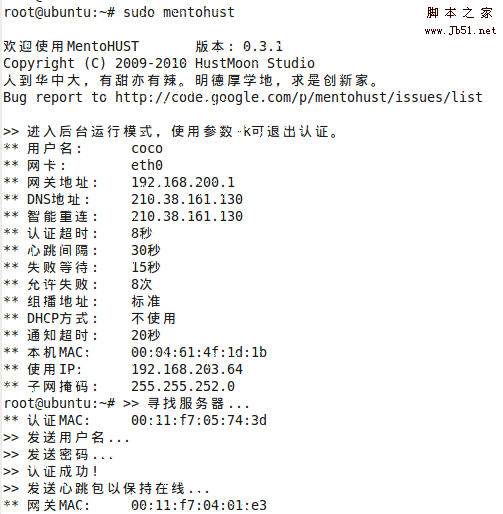
Linux下Dr.com(802.1x)撥號上網完
Linux中 如何查看Ubuntu內存信息?
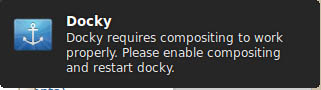
Linux下如何修復Lubuntu中的Docky
網友關注