前言
相信大家應(yīng)該都有所體會(huì),shell腳本可以說作用非常大,在服務(wù)器領(lǐng)域,用shell操作事務(wù)可比手動(dòng)點(diǎn)擊要方便快捷得多了。雖然只是文字界面,但是其強(qiáng)大的處理功能,會(huì)讓各種操作超乎想象。而且,也可以將這些習(xí)慣移植到日常的工作當(dāng)中,提升辦事效率。
其實(shí)shell語法很簡單,基本上就是綜合一下在命令行下,一個(gè)個(gè)的命令集合,然后就組成了shell腳本。當(dāng)然了,不懂語法的,百度搜索一下就好了嘛,畢竟,重要的是思想而非語法。
最近,剛接一需求,如下:
DBA會(huì)將一些服務(wù)規(guī)則的數(shù)據(jù)導(dǎo)出,然后一條條手動(dòng)去curl某應(yīng)用接口,從而完成相應(yīng)的業(yè)務(wù)要求。
那么問題來了,DBA導(dǎo)出的數(shù)據(jù)是格式化的,要curl的接口也是格式化的,需要的,只是將相應(yīng)的數(shù)據(jù)替換成對(duì)應(yīng)的值即可。注意,不保證所有的命令都能執(zhí)行成功,有可能需要重新跑接口。
很明顯,手動(dòng)一條條地去寫curl命令,然后一條條執(zhí)行,然后觀察結(jié)果,做出判斷,這對(duì)于少數(shù)幾個(gè)數(shù)據(jù)來說,是可行的。但是假設(shè),數(shù)據(jù)有幾百條、幾千條幾萬條呢,那就不可能人工一條條去搞了吧。因此,shell腳本就該出場(chǎng)了(當(dāng)然了,有同學(xué)說,我用其他語言也可以啊,甚至說我這個(gè)功能寫到代碼里就可以了,然而這些特殊無意義的代碼,是不需要長期保留下來的)。
該shell腳本只要做好三件事就行了:
1. 讀取源數(shù)據(jù)文件的內(nèi)容,替換接口的數(shù)據(jù)格式;
2. 執(zhí)行命令,完成業(yè)務(wù)操作;
3. 記錄完整的日志,以便后期排查對(duì)比;
需求很簡單,不懂語法沒關(guān)系,查一下嘛。參考代碼如下:
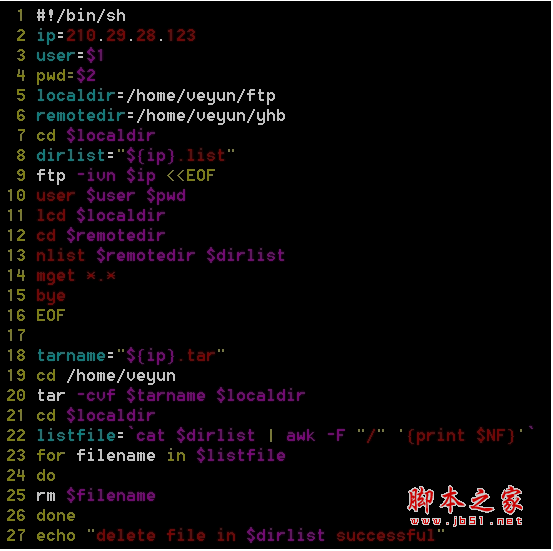
#!/bin/bashlog_file='result.log'param_file=$1 # 源數(shù)據(jù)在命令行中指定log_cmd="tee -a $log_file"i=1for line in `cat $param_file`;do echo "read line" $i ":" $line | tee -a $log_file let "i=$i+1" OLD_IFS=$IFS;IFS=","; arr=($line) # 分割數(shù)據(jù)到數(shù)組 IFS=$OLD_IFS; curl_cmd="curl -d 'uId=${arr[0]}&bid=${arr[1]}&bA=${arr[2]}&to=6&bP=30&fddays=5' http://localhost:8080/mi/api/ss/1.0.1/co/apply" echo `date "+%Y-%m-%d %H:%M:%S"` "start ===>> " $curl_cmd | tee -a $log_file eval "$curl_cmd 2>&1" | tee -a $log_file # 使用 eval 命令,把錯(cuò)誤日志和接口返回結(jié)果一并帶回,到后續(xù)console及日志存儲(chǔ) echo `date "+%Y-%m-%d %H:%M:%S"` "end <<===" $curl_cmd | tee -a $log_filedoneecho `date "+%Y-%m-%d %H:%M:%S"` "over: end of shell" | tee -a $log_file源數(shù)據(jù)格式參考如下:
234,201708222394083443,50004211,201782937493274932,300023,201749379583475934,2000
當(dāng)讀取的文件格式為空格分隔的文件時(shí),該讀取將發(fā)生異常,換成另一種方式讀取行:
#!/bin/bashlog_file='result.log'param_file=$1log_cmd="tee -a $log_file"i=1while read line;do echo "read line" $i ":" $line | tee -a $log_file let "i=$i+1" arr=($line) curl_cmd="curl -d 'uId=${arr[0]}&bid=${arr[1]}&bt=${arr[2]}&toBorrowType=6&borrowPeriod=30&fddays=5' http://localhost/mi/c/1.0.1/c/n" echo `date "+%Y-%m-%d %H:%M:%S"` "start ===>> " $curl_cmd | tee -a $log_file #`$curl_cmd` 2>&1 $log_file | tee -a $log_file eval "$curl_cmd 2>&1" | tee -a $log_file echo `date "+%Y-%m-%d %H:%M:%S"` "end <<===" $curl_cmd | tee -a $log_filedone < $param_fileecho `date "+%Y-%m-%d %H:%M:%S"` "over: end of shell" | tee -a $log_file這里有個(gè)技巧,即使用tee命令,既在console上顯示了訪問日志,也往文件里寫入了記錄。即有人工觀察,也有日志存儲(chǔ),以備查看。
如此,便實(shí)現(xiàn)了大家都不用手動(dòng)敲數(shù)據(jù),從而在這上面犯錯(cuò)的可能了。 DBA從數(shù)據(jù)導(dǎo)出格式化數(shù)據(jù),shell腳本直接讀取格式化數(shù)據(jù),保留記錄。這才是程序該干的事。
一句話,想辦法偷個(gè)懶,這是我們?cè)摳傻氖隆?/p>
但是應(yīng)該要注意,當(dāng)一個(gè)接口被腳本跑去執(zhí)行時(shí),你就行考慮并發(fā)問題,以服務(wù)器的壓問題了,也不要太相信代碼。做最壞的打算。
curl的命令請(qǐng)參考:https://curl.haxx.se/docs/manpage.html (你可以搜簡要中文描述,當(dāng)然)
總結(jié)
從前覺得1、2G的日志文件處理是個(gè)頭疼的問題,后來發(fā)現(xiàn) grep, awk, sed, less, salt 等工具組合起來,能讓你從幾十G甚至更多的千軍萬馬文件中,直取要害。這便是linux的厲害之處。
以上就是這篇文章的全部內(nèi)容了,希望本文的內(nèi)容對(duì)大家的學(xué)習(xí)或者工作能帶來一定的幫助,如果有疑問大家可以留言交流,謝謝大家對(duì)武林網(wǎng)的支持。
新聞熱點(diǎn)





疑難解答
圖片精選