前言
對(duì)于一些原理性文章園中已有大量的文章尤其是關(guān)于索引這一塊,我也是花費(fèi)大量時(shí)間去學(xué)習(xí),對(duì)于了解索引原理對(duì)于后續(xù)理解查詢(xún)計(jì)劃和性能調(diào)優(yōu)有很大的幫助,而我們只是一些內(nèi)容進(jìn)行概括和總結(jié),這一節(jié)我們開(kāi)始正式步入學(xué)習(xí)SQL中簡(jiǎn)單的查詢(xún)語(yǔ)句,簡(jiǎn)短的內(nèi)容,深入的理解。
簡(jiǎn)單查詢(xún)語(yǔ)句
所有復(fù)雜的語(yǔ)句都是由簡(jiǎn)單的語(yǔ)句組成基本都是由SELECT、FROM、WHERE、GROUP BY、HAVING、ORDER BY等組成,當(dāng)然還包括一些謂詞等等。比如當(dāng)我們要查詢(xún)某表中所有數(shù)據(jù)時(shí)我們會(huì)像如下進(jìn)行。
SELECT * FROM TABLE
到這里是不是查詢(xún)就是從SELECT開(kāi)始呢?我們應(yīng)該從實(shí)際生活舉例,如我們需要到菜市場(chǎng)買(mǎi)菜,我們想買(mǎi)芹菜,我們應(yīng)該是到有芹菜的攤位上去買(mǎi),也就是從哪里去買(mǎi),到這里我們會(huì)發(fā)現(xiàn)上述查詢(xún)數(shù)據(jù)的順序應(yīng)該是先FROM然后是SELECT。在SQL 2012基礎(chǔ)教程中列出子句是按照以下順序進(jìn)行邏輯處理。
FROMWHEREGROUP BYHAVINGSELECTORDER BY
比如我們要查詢(xún)篩選客戶(hù)71下的訂單,我們會(huì)進(jìn)行如下查詢(xún)。
SELECT empid, YEAR(orderdate) AS orderyear, COUNT(*) AS numbers FROM Sales.OrdersWHERE custid = '71'GROUP BY empid, YEAR(orderdate)HAVING COUNT(*) > 1ORDER BY empid, orderyear
但是實(shí)際上按照我們上述所說(shuō)的順序,其邏輯化的子句是這樣的。
FROM Sales.OrdersWHERE custid = 71GROUP BY empid, YEAR(orderdate)HAVING COUNT(*) > 1SELECT empid, YEAR(orderdate) AS orderyear, COUNT(*) AS numberordersORDER BY empid, orderyear
對(duì)于博主的SQL系列并非會(huì)將SELECT、HAVING等語(yǔ)句單獨(dú)拿來(lái)講,針對(duì)的是有了一定基礎(chǔ)的人群,后續(xù)內(nèi)容也是如此,所以到了這里我們算是將簡(jiǎn)單查詢(xún)語(yǔ)句敘述完畢。但是我一直強(qiáng)調(diào)的是簡(jiǎn)短的內(nèi)容,深入的理解,所以接下來(lái)看看有些需要注意的地方。
我們看到過(guò)很多文章一直在講SQL性能問(wèn)題,比如在查詢(xún)所有數(shù)據(jù)時(shí)要列出所有列而非SELECT *,所以在本系列中,我也會(huì)在適當(dāng)?shù)娜ブv性能問(wèn)題,比如本節(jié)要講的SELECT 1和SELECT *的性能問(wèn)題。
SELECT 1和SELECT *性能探討
在數(shù)據(jù)庫(kù)中查看執(zhí)行計(jì)劃時(shí)我們通常會(huì)點(diǎn)擊【顯示估計(jì)的執(zhí)行計(jì)劃】快捷鍵是Ctrl+L,這里我們可以看到它已經(jīng)表明顯示的只是估計(jì)的執(zhí)行計(jì)劃,所以是不準(zhǔn)確的,所以為了顯示實(shí)際的執(zhí)行計(jì)劃,我們應(yīng)該啟動(dòng)【包括實(shí)際的執(zhí)行計(jì)劃】,快捷鍵是Ctrl+M,這樣才能得到比較準(zhǔn)確的執(zhí)行計(jì)劃,如下
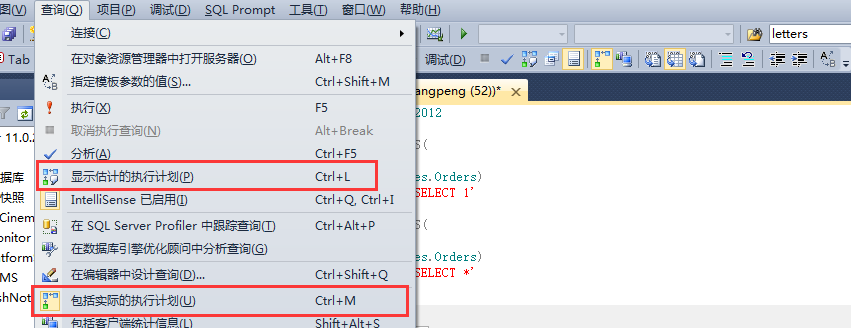
查詢(xún)方式一(整表查詢(xún))
USE TSQL2012GOIF EXISTS(SELECT 1FROM Sales.Orders)SELECT 'SELECT 1'GOIF EXISTS(SELECT *FROM Sales.Orders)SELECT 'SELECT *'GO
此時(shí)查看執(zhí)行計(jì)劃是相同的,如下:
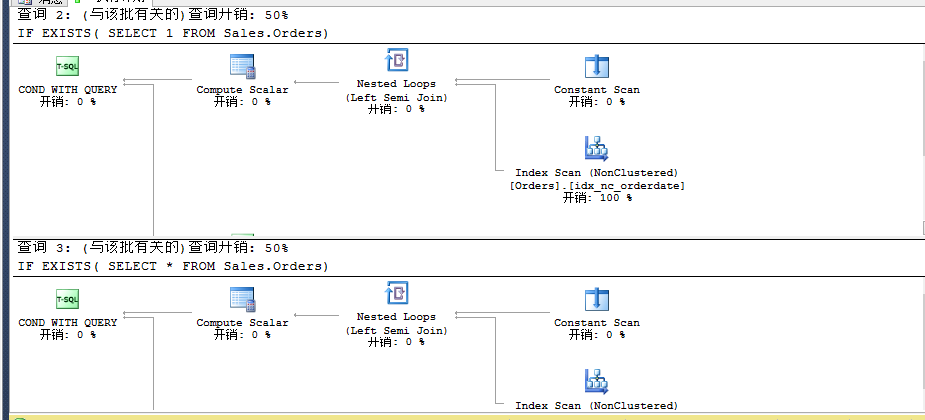
查詢(xún)方式二(在索引列上條件查找)
我們對(duì)某一列創(chuàng)建索引
CREATE INDEX ix_shipnameON Sales.Orders(shipname)
接下來(lái)繼續(xù)查看其執(zhí)行計(jì)劃。
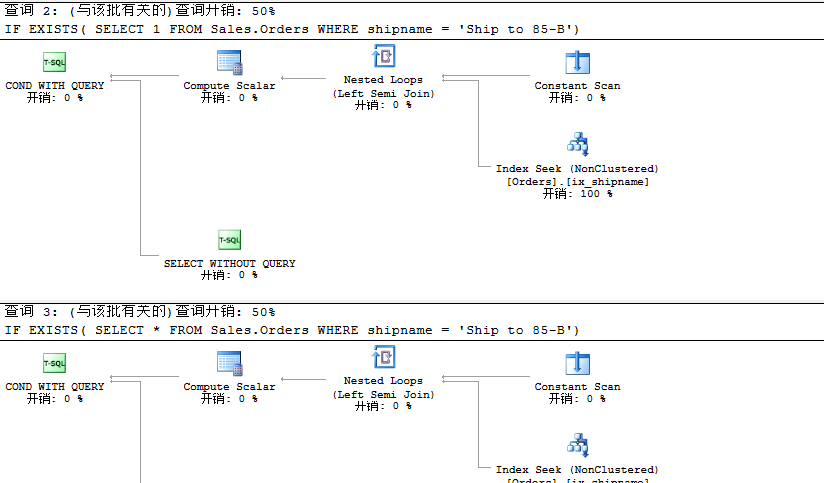
此時(shí)顯示查詢(xún)計(jì)劃依然一樣。我們?cè)賮?lái)看看其他查詢(xún)方式。
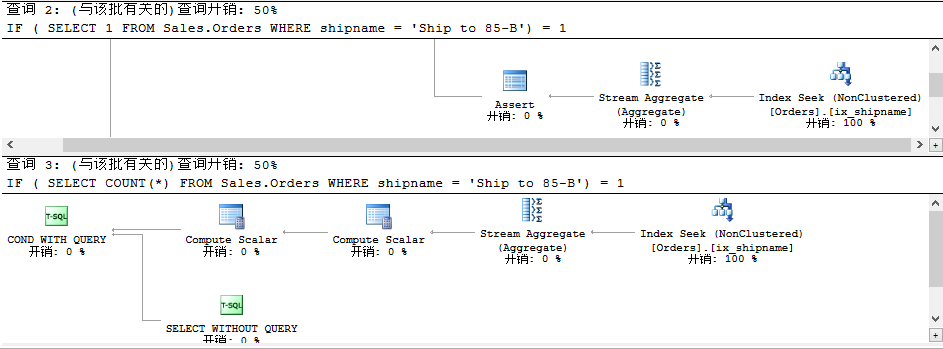
查詢(xún)方式三(使用聚合函數(shù))
USE TSQL2012GOIF (SELECT 1FROM Sales.OrdersWHERE shipname = 'Ship to 85-B') = 1SELECT 'SELECT 1'GOIF (SELECT COUNT(*)FROM Sales.OrdersWHERE shipname = 'Ship to 85-B') = 1SELECT 'SELECT *'GO
我們看到查詢(xún)計(jì)劃依然一樣。
查詢(xún)方式四(使用聚合函數(shù)Count在非索引列上查找)
USE TSQL2012GOIF (SELECT COUNT(1)FROM Sales.OrdersWHERE freight = '41.3400') = 1SELECT 'SELECT 1'GOIF (SELECT COUNT(*)FROM Sales.OrdersWHERE freight = '41.3400') = 1SELECT 'SELECT *'GO
我們看到執(zhí)行計(jì)劃還是一樣。

查詢(xún)方式五(子查詢(xún))
我們看看在子查詢(xún)中二者性能如何
USE TSQL2012SELECT custid, companyname FROM Sales.Customers AS CWHERE country = N'USA' ANDEXISTS (SELECT * FROM Sales.Orders AS O WHERE O.custid = C.custid)GOSELECT custid, companyname FROM Sales.Customers AS CWHERE country = N'USA' ANDEXISTS (SELECT 1 FROM Sales.Orders AS O WHERE O.custid = C.custid)
此時(shí)結(jié)果二者查看執(zhí)行計(jì)劃還是一樣

查詢(xún)方式六(在視圖中查詢(xún))
我們創(chuàng)建視圖繼續(xù)來(lái)比較SELECT 1和SELECT *的性能
USE TSQL2012GoCREATE VIEW SaleOdersViewASSELECT shipaddress,shipname,(SELECT unitprice FROM Sales.OrderDetails AS sod where sod.orderid = so.orderid) as tc3FROM Sales.Orders AS soGO
進(jìn)行視圖查詢(xún)
USE TSQL2012SELECT 1 FROM dbo.SaleOdersViewgoSELECT * FROM dbo.SaleOdersViewgo
結(jié)果執(zhí)行計(jì)劃如下:

此時(shí)我們通過(guò)上述圖發(fā)現(xiàn)利用視圖查詢(xún)時(shí),SELECT *的性能是如此低下占有97%,而SELECT 1才3%,這是為何呢?不明白其中原因,希望有清楚其中原因的園友能夠留下你們的評(píng)論給出合理的解釋。
SELECT 所有列和SELECT *性能探討
一直以來(lái)所有教程都在講SELECT *性能比SELECT 所有列性能低,同時(shí)也給出了合理的理由,我也一直這樣認(rèn)為,但是在查資料學(xué)習(xí)過(guò)程中,發(fā)現(xiàn)如下一段話(huà)。
I don't think there is any difference, as long as the SELECT 1/* is inside EXISTS, which really doesn't return any rows 主站蜘蛛池模板: 张掖市| 新绛县| 蓬莱市| 常宁市| 建德市| 察雅县| 远安县| 右玉县| 页游| 大石桥市| 海门市| 军事| 鹤山市| 翁牛特旗| 贵溪市| 平乐县| 新建县| 新野县| 利川市| 英吉沙县| 灵宝市| 普陀区| 天柱县| 瑞金市| 昌都县| 葫芦岛市| 万安县| 镇巴县| 天峻县| 星座| 新安县| 潮州市| 合山市| 钟山县| 闽侯县| 丰镇市| 宜州市| 岐山县| 洛浦县| 临城县| 邯郸市|