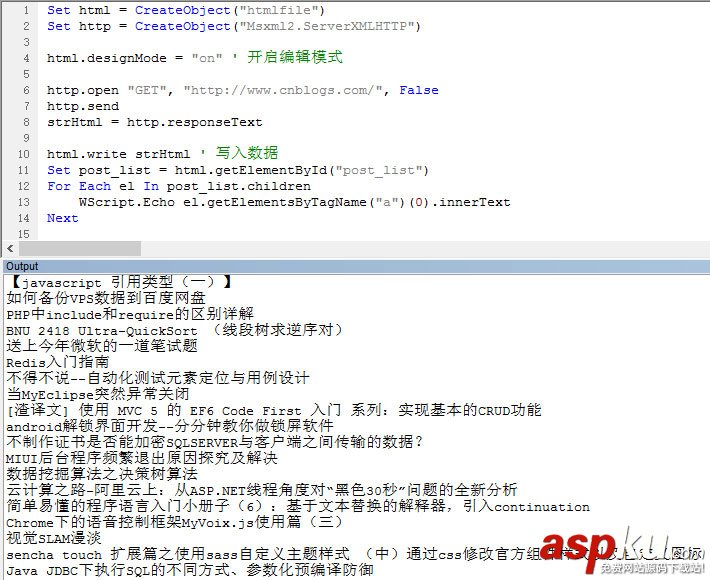
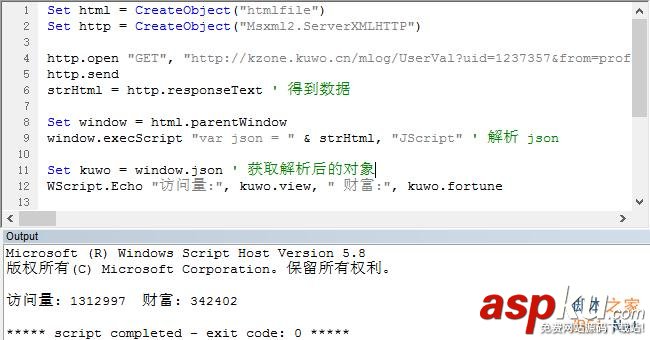
是自寫的采集程序。
經過搜索以后,查到一些沒有用的結果,后來發現,用Msxml2.ServerXMLHTTP替換掉Msxml2.XMLHTTP,問題成功解決。
以下是分析排錯過程。
老是采集一段時間就掛了,指定資源下載失敗,或者拒絕訪問。
后來直接全部是拒絕訪問。
一開始,認為,對方服務器做了防采集設置,比如有時間限制之類的。
于是更改程序,原先是直接獲取列表頁,然后持續循環獲得文章列表。改了采集文件結構,
原來是就一個文件,類,數據庫連接,數據處理全部在一個文件里,再采集某一篇文章的時候,后天加了一個時間循環。等待5秒的。代碼如下
復制代碼代碼如下:
sTime=Timer()
dTime=Timer()-sTime
do while dTime < 5
dTime=Timer()-sTime
loop
確實是能等待5秒鐘,但是很快就發現,這個循環太過消耗CPU資源,一到這個循環,CPU占用率持續100%,于是馬上放棄這個方案。
另做了一個文件。只根據文章URL抓取文章的相關內容并寫入數據庫,寫入完畢后輸出自動跳轉代碼。
核心思想就是用了<meta http-equiv="refresh" content="5;url=someurl.asp">
這是一個定時跳轉的代碼,相信大家都很熟悉。
我的原理做法就是,用一開始的文件,抓取所有的文章連接地址,以及相關導航代碼,保存到數據庫中。
然后用新做的抓取文章內容的程序,讀取數據庫記錄,逐條進行采集。
數據庫記錄中有一個flag標記,tinyint類型,默認是0,采集成功更新為1,失敗更新為2
這樣,每次從數據庫中讀取一條未采集的數據,也就是讀取flag=0的數據,進行操作。操作完畢等待5秒跳轉到自身。
想法跟思路是很好的。文章URL數據庫也采集準備好了,一上采集文章具體內容,又出錯了。一直是msxml3.dll 錯誤 '80070005'
拒絕訪問的錯誤。
那個郁悶,想開一晚上機器,自動采集,破滅。
今天早上來搜索查詢資料,查詢到的絕大多數都是無用信息。
基本上都是說權限問題。
msxml3.dll 錯誤 '80070005'
拒絕訪問。
解決辦法:
賦予程序所在文件夾 internet 來賓帳號(IUSR_WEB)可寫。
做法:
選擇cachefile-屬性-安全-添加(IUSR_WEB)-寫入
都是這么說的。莫名其妙的,我的是FAT32的不存在NTFS格式的那種安全權限問題,IIS設置也正常,
我的問題是采集一部分就拒絕訪問。肯定不是這個問題。
繼續搜索,找到另一個方案說是,用Msxml2.XMLHTTP替換掉Microsoft.XMLHTTP,我本來用的就是Msxml2.XMLHTTP的
繼續搜索。找到最終解決方案應該是用Msxml2.ServerXMLHTTP
先前也搜到這個結果,由于大意,沒有及時注意到,以下是搜索過程找到的有用的相關資料。
代碼如下:
復制代碼代碼如下:
PostUrl=http://www.xxx.com/
Server.ScriptTimeOut=20
Set oXMLHttp = createObject("Microsoft.XMLHTTP")
Call oXMLHttp.Open("get", PostUrl, false)
Call oXMLHttp.Send("")
sHtmlStr = oXMLHttp.responseBody
Set oXMLHttp = nothing
初步判定可能是打開的頁面有跳轉的原因,解決辦法是用
MSXML2.ServerXMLHTTP
替換掉
Microsoft.XMLHTTP
即可解決。
另外在CSDN上找到這么一段代碼
復制代碼代碼如下:
ServerURL=PostUrl
Set Mail1 = Server.CreateObject("CDO.Message")
Mail1.CreateMHTMLBody ServerURL,31
AA=Mail1.HTMLBody
Set Mail1 = Nothing
Response.Write AA
試了一下,也可以用,拷過來收藏
復制代碼代碼如下:
<%
' 定義變量
Dim objXmlHttp
Dim strHTML
'這是Msxml3.0中的一個穩定版本.
'使用Msxml2.ServerXMLHTTP,不使用Msxml2.XMLHTTP
Set objXmlHttp = Server.CreateObject("Msxml2.ServerXMLHTTP")
' 如果你發現以下錯誤
' msxml3.dll error '80070005'
' 存取被拒絕.
' 可能是上網時使用了代理產生了錯誤
' 使用 proxycfg.exe 工具. :
'
' proxycfg -d
' 檢查是否采用了代理上網
' 同時可以參看這個帖子: http://www.asp101.com/forum/display_message.asp?mid=51841
'
' 這個版本太舊且不穩定
'Set objXmlHttp = Server.CreateObject("Msxml2.XMLHTTP")
' 現在我們開始發送請求.
' 套用微軟的話來講: 初始化一個請求,并且指定該請求的方法(get,post等等),
' URL, 和權限驗證信息(用戶名,密碼,等等)。
' 格式:
' .open(bstrMethod, bstrUrl, bAsync, bstrUser, bstrPassword)
'objXmlHttp.open "GET", "http://www.yahoo.com", False
objXmlHttp.open "GET", "http://www.yahoo.com", False
' 以直接的方式發送請求出去.
objXmlHttp.send
' 打印返回狀態:
Response.Write "Status: " & objXmlHttp.status & " " _
& objXmlHttp.statusText & "<br />"
' 獲取響應返回的文本.
' 這個對象本身是用來操作XML的,所以具備以下屬性:
' responseBody, responseStream, 和 responseXML.
' 但是我們現在只需要文本信息
strHTML = objXmlHttp.responseText
' 但這個對象實例不再使用時,需要清除這個對象實例.
Set objXmlHttp = Nothing
' 現在我們要做的就是顯示我們獲取到的HTML.
' 首先看瀏覽器解釋的效果
' 然后顯示其源碼
' 下面的類似<h1>s 和 <table>s只是為了展現獲取到的內容,本身不屬于獲取的內容.
%>
<h1>Here's The Page:</h1>
<table border="1" bgcolor="#FFFFFF">
<tr><td>
<%= strHTML %>
</td></tr>
</table>
<br />
<h1>Here's The Code:</h1>
<table border="1" bgcolor="#FFFFFF">
<tr><td>
<pre>
<%= Server.HTMLEncode(strHTML) %>
</pre>
</td></tr>
</table>