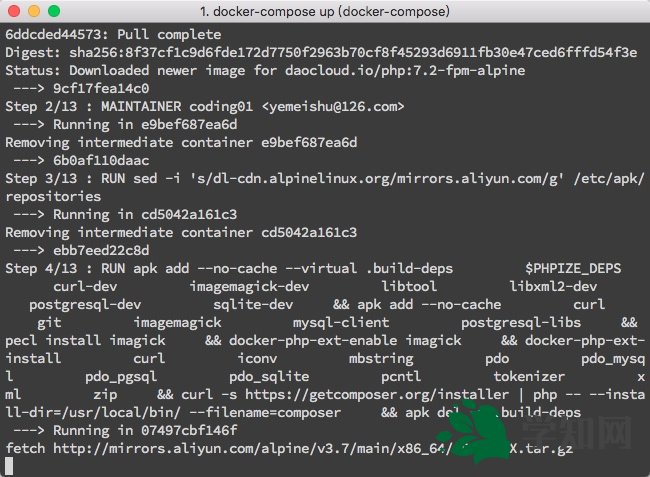
本程序是抓取知乎的用戶數(shù)據(jù),要能訪問用戶個人頁面,需要用戶登錄后的才能訪問。當(dāng)我們在瀏覽器的頁面中點(diǎn)擊一個用戶頭像鏈接進(jìn)入用戶個人中心頁面的時(shí)候,之所以能夠看到用戶的信息,是因?yàn)樵邳c(diǎn)擊鏈接的時(shí)候,瀏覽器幫你將本地的cookie帶上一齊提交到新的頁面,所以你就能進(jìn)入到用戶的個人中心頁面。因此實(shí)現(xiàn)訪問個人頁面之前需要先獲得用戶的cookie信息,然后在每次curl請求的時(shí)候帶上cookie信息。在獲取cookie信息方面,我是用了自己的cookie,在頁面中可以看到自己的cookie信息:
一個個地復(fù)制,以"__utma=?;__utmb=?;"這樣的形式組成一個cookie字符串。接下來就可以使用該cookie字符串來發(fā)送請求。
初始的示例:
$url = 'http://www.zhihu.com/people/mora-hu/about'; //此處mora-hu代表用戶ID $ch = curl_init($url); //初始化會話 curl_setopt($ch, CURLOPT_HEADER, 0); curl_setopt($ch, CURLOPT_COOKIE, $this->config_arr['user_cookie']); //設(shè)置請求COOKIE curl_setopt($ch, CURLOPT_USERAGENT, $_SERVER['HTTP_USER_AGENT']); curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); //將curl_exec()獲取的信息以文件流的形式返回,而不是直接輸出。 curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1); $result = curl_exec($ch); return $result; //抓取的結(jié)果
運(yùn)行上面的代碼可以獲得mora-hu用戶的個人中心頁面。利用該結(jié)果再使用html' target='_blank'>正則表達(dá)式對頁面進(jìn)行處理,就能獲取到姓名,性別等所需要抓取的信息。
圖片防盜鏈
在對返回結(jié)果進(jìn)行正則處理后輸出個人信息的時(shí)候,發(fā)現(xiàn)在頁面中輸出用戶頭像時(shí)無法打開。經(jīng)過查閱資料得知,是因?yàn)橹鯇D片做了防盜鏈處理。解決方案就是請求圖片的時(shí)候在請求頭里偽造一個referer。
在使用正則表達(dá)式獲取到圖片的鏈接之后,再發(fā)一次請求,這時(shí)候帶上圖片請求的來源,說明該請求來自知乎網(wǎng)站的轉(zhuǎn)發(fā)。具體例子如下:
function getImg($url, $u_id){ if (file_exists('./images/' . $u_id . ".jpg")) { return "images/$u_id" . '.jpg'; } if (empty($url)) { return ''; } $context_options = array( 'http' => array( 'header' => "Referer:http://www.zhihu.com"//帶上referer參數(shù) ) ); $context = stream_context_create($context_options); $img = file_get_contents('http:' . $url, FALSE, $context); file_put_contents('./images/' . $u_id . ".jpg", $img); return "images/$u_id" . '.jpg';}爬取更多用戶
不同的用戶的這個url幾乎是一樣的,不同的地方就在于用戶名那里。用正則匹配拿到用戶名列表,一個一個地拼url,然后再逐個發(fā)請求(當(dāng)然,一個一個是比較慢的,下面有解決方案,這個稍后會說到)。進(jìn)入到新用戶的頁面之后,再重復(fù)上面的步驟,就這樣不斷循環(huán),直到達(dá)到你所要的數(shù)據(jù)量。
linux統(tǒng)計(jì)文件數(shù)量
腳本跑了一段時(shí)間后,需要看看究竟獲取了多少圖片,當(dāng)數(shù)據(jù)量比較大的時(shí)候,打開文件夾查看圖片數(shù)量就有點(diǎn)慢。腳本是在linux環(huán)境下運(yùn)行的,因此可以使用linux的命令來統(tǒng)計(jì)文件數(shù)量:
其中,ls -l是長列表輸出該目錄下的文件信息(這里的文件可以是目錄、鏈接、設(shè)備文件等);grep "^-"過濾長列表輸出信息,"^-" 只保留一般文件,如果只保留目錄是"^d";wc -l是統(tǒng)計(jì)輸出信息的行數(shù)。下面是一個運(yùn)行示例:

插入MySQL時(shí)重復(fù)數(shù)據(jù)的處理
程序運(yùn)行了一段時(shí)間后,發(fā)現(xiàn)有很多用戶的數(shù)據(jù)是重復(fù)的,因此需要在插入重復(fù)用戶數(shù)據(jù)的時(shí)候做處理。處理方案如下:
1)插入數(shù)據(jù)庫之前檢查數(shù)據(jù)是否已經(jīng)存在數(shù)據(jù)庫;
2)添加唯一索引,插入時(shí)使用INSERT INTO ... ON DUPliCATE KEY UPDATE...
3)添加唯一索引,插入時(shí)使用INSERT INGNO
RE INTO...
4)添加唯一索引,插入時(shí)使用REPLACE INTO...
使用curl_multi實(shí)現(xiàn)I/O復(fù)用抓取頁面
剛開始單進(jìn)程而且單個curl去抓取數(shù)據(jù),速度很慢,掛機(jī)爬了一個晚上只能抓到2W的數(shù)據(jù),于是便想到能不能在進(jìn)入新的用戶頁面發(fā)curl請求的時(shí)候一次性請求多個用戶,后來發(fā)現(xiàn)了curl_multi這個好東西。curl_multi這類函數(shù)可以實(shí)現(xiàn)同時(shí)請求多個url,而不是一個個請求,這是一種I/O復(fù)用的機(jī)制。下面是使用curl_multi爬蟲的示例:
$mh = curl_multi_init(); //返回一個新cURL批處理句柄 for ($i = 0; $i < $max_size; $i++) { $ch = curl_init(); //初始化單個cURL會話 curl_setopt($ch, CURLOPT_HEADER, 0); curl_setopt($ch, CURLOPT_URL, 'http://www.zhihu.com/people/' . $user_list[$i] . '/about'); curl_setopt($ch, CURLOPT_COOKIE, self::$user_cookie); curl_setopt($ch, CURLOPT_USERAGENT, 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/44.0.2403.130 Safari/537.36'); curl_setopt($ch, CURLOPT_RETURNTRANSFER, true); curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1); $requestMap[$i] = $ch; curl_multi_add_handle($mh, $ch); //向curl批處理會話中添加單獨(dú)的curl句柄 } $user_arr = array(); do { //運(yùn)行當(dāng)前 cURL 句柄的子連接 while (($cme = curl_multi_exec($mh, $active)) == CURLM_CALL_MULTI_PERFORM); if ($cme != CURLM_OK) {break;} //獲取當(dāng)前解析的cURL的相關(guān)傳輸信息 while ($done = curl_multi_info_read($mh)) { $info = curl_getinfo($done['handle']); $tmp_result = curl_multi_getcontent($done['handle']); $error = curl_error($done['handle']); $user_arr[] = array_values(getUserInfo($tmp_result)); //保證同時(shí)有$max_size個請求在處理 if ($i < sizeof($user_list) && isset($user_list[$i]) && $i < count($user_list)) { $ch = curl_init(); curl_setopt($ch, CURLOPT_HEADER, 0); curl_setopt($ch, CURLOPT_URL, 'http://www.zhihu.com/people/' . $user_list[$i] . '/about'); curl_setopt($ch, CURLOPT_COOKIE, self::$user_cookie); curl_setopt($ch, CURLOPT_USERAGENT, 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/44.0.2403.130 Safari/537.36'); curl_setopt($ch, CURLOPT_RETURNTRANSFER, true); curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1); $requestMap[$i] = $ch; curl_multi_add_handle($mh, $ch); $i++; } curl_multi_remove_handle($mh, $done['handle']); } if ($active) curl_multi_select($mh, 10); } while ($active); curl_multi_close($mh); return $user_arr;HTTP 429 Too Many Requests
使用curl_multi函數(shù)可以同時(shí)發(fā)多個請求,但是在執(zhí)行過程中使同時(shí)發(fā)200個請求的時(shí)候,發(fā)現(xiàn)很多請求無法返回了,即發(fā)現(xiàn)了丟包的情況。進(jìn)一步分析,使用curl_getinfo函數(shù)打印每個請求句柄信息,該函數(shù)返回一個包含HTTP response信息的關(guān)聯(lián)數(shù)組,其中有一個字段是http_code,表示請求返回的HTTP狀態(tài)碼。看到有很多個請求的http_code都是429,這個返回碼的意思是發(fā)送太多請求了。我猜是知乎做了防爬蟲的防護(hù),于是我就拿其他的網(wǎng)站來做測試,發(fā)現(xiàn)一次性發(fā)200個請求時(shí)沒問題的,證明了我的猜測,知乎在這方面做了防護(hù),即一次性的請求數(shù)量是有限制的。于是我不斷地減少請求數(shù)量,發(fā)現(xiàn)在5的時(shí)候就沒有丟包情況了。說明在這個程序里一次性最多只能發(fā)5個請求,雖然不多,但這也是一次小提升了。
使用Redis保存已經(jīng)訪問過的用戶
抓取用戶的過程中,發(fā)現(xiàn)有些用戶是已經(jīng)訪問過的,而且他的關(guān)注者和關(guān)注了的用戶都已經(jīng)獲取過了,雖然在數(shù)據(jù)庫的層面做了重復(fù)數(shù)據(jù)的處理,但是程序還是會使用curl發(fā)請求,這樣重復(fù)的發(fā)送請求就有很多重復(fù)的網(wǎng)絡(luò)開銷。還有一個就是待抓取的用戶需要暫時(shí)保存在一個地方以便下一次執(zhí)行,剛開始是放到數(shù)組里面,后來發(fā)現(xiàn)要在程序里添加多進(jìn)程,在多進(jìn)程編程里,子進(jìn)程會共享程序代碼、函數(shù)庫,但是進(jìn)程使用的變量與其他進(jìn)程所使用的截然不同。不同進(jìn)程之間的變量是分離的,不能被其他進(jìn)程讀取,所以是不能使用數(shù)組的。因此就想到了使用Redis緩存來保存已經(jīng)處理好的用戶以及待抓取的用戶。這樣每次執(zhí)行完的時(shí)候都把用戶push到一個already_request_queue隊(duì)列中,把待抓取的用戶(即每個用戶的關(guān)注者和關(guān)注了的用戶列表)push到request_queue里面,然后每次執(zhí)行前都從request_queue里pop一個用戶,然后判斷是否在already_request_queue里面,如果在,則進(jìn)行下一個,否則就繼續(xù)執(zhí)行。
在PHP中使用redis示例:
<?php $redis = new Redis(); $redis->connect('127.0.0.1', '6379'); $redis->set('tmp', 'value'); if ($redis->exists('tmp')) { echo $redis->get('tmp') . "/n"; }使用PHP的pcntl擴(kuò)展實(shí)現(xiàn)多進(jìn)程
改用了curl_multi函數(shù)實(shí)現(xiàn)多線程抓取用戶信息之后,程序運(yùn)行了一個晚上,最終得到的數(shù)據(jù)有10W。還不能達(dá)到自己的理想目標(biāo),于是便繼續(xù)優(yōu)化,后來發(fā)現(xiàn)php里面有一個pcntl擴(kuò)展可以實(shí)現(xiàn)多進(jìn)程編程。下面是多編程編程的示例:
//PHP多進(jìn)程demo //fork10個進(jìn)程 for ($i = 0; $i < 10; $i++) { $pid = pcntl_fork(); if ($pid == -1) { echo "Could not fork!/n"; exit(1); } if (!$pid) { echo "child process $i running/n"; //子進(jìn)程執(zhí)行完畢之后就退出,以免繼續(xù)fork出新的子進(jìn)程 exit($i); } } //等待子進(jìn)程執(zhí)行完畢,避免出現(xiàn)僵尸進(jìn)程 while (pcntl_waitpid(0, $status) != -1) { $status = pcntl_wexitstatus($status); echo "Child $status completed/n"; }在linux下查看系統(tǒng)的cpu信息
實(shí)現(xiàn)了多進(jìn)程編程之后,就想著多開幾條進(jìn)程不斷地抓取用戶的數(shù)據(jù),后來開了8調(diào)進(jìn)程跑了一個晚上后發(fā)現(xiàn)只能拿到20W的數(shù)據(jù),沒有多大的提升。于是查閱資料發(fā)現(xiàn),根據(jù)系統(tǒng)優(yōu)化的CPU性能調(diào)優(yōu),程序的最大進(jìn)程數(shù)不能隨便給的,要根據(jù)CPU的核數(shù)和來給,最大進(jìn)程數(shù)最好是cpu核數(shù)的2倍。因此需要查看cpu的信息來看看cpu的核數(shù)。在linux下查看cpu的信息的命令:

其中,model name表示cpu類型信息,cpu cores表示cpu核數(shù)。這里的核數(shù)是1,因?yàn)槭窃?a href='http://m.survivalescaperooms.com/tag/xuniji_6629_1.html' target='_blank'>虛擬機(jī)下運(yùn)行,分配到的cpu核數(shù)比較少,因此只能開2條進(jìn)程。最終的結(jié)果是,用了一個周末就抓取了110萬的用戶數(shù)據(jù)。
多進(jìn)程編程中Redis和MySQL連接問題
在多進(jìn)程條件下,程序運(yùn)行了一段時(shí)間后,發(fā)現(xiàn)數(shù)據(jù)不能插入到數(shù)據(jù)庫,會報(bào)mysql too many connections的錯誤,redis也是如此。
下面這段代碼會執(zhí)行失敗:
<?php for ($i = 0; $i < 10; $i++) { $pid = pcntl_fork(); if ($pid == -1) { echo "Could not fork!/n"; exit(1); } if (!$pid) { $redis = PRedis::getInstance(); // do something exit; } }根本原因是在各個子進(jìn)程創(chuàng)建時(shí),就已經(jīng)繼承了父進(jìn)程一份完全一樣的拷貝。對象可以拷貝,但是已創(chuàng)建的連接不能被拷貝成多個,由此產(chǎn)生的結(jié)果,就是各個進(jìn)程都使用同一個redis連接,各干各的事,最終產(chǎn)生莫名其妙的沖突。
解決方法:
程序不能完全保證在fork進(jìn)程之前,父進(jìn)程不會創(chuàng)建redis連接實(shí)例。因此,要解決這個問題只能靠子進(jìn)程本身了。試想一下,如果在子進(jìn)程中獲取的實(shí)例只與當(dāng)前進(jìn)程相關(guān),那么這個問題就不存在了。于是解決方案就是稍微改造一下redis類實(shí)例化的靜態(tài)方式,與當(dāng)前進(jìn)程ID綁定起來。
改造后的代碼如下:
<?php public static function getInstance() { static $instances = array(); $key = getmypid();//獲取當(dāng)前進(jìn)程ID if ($empty($instances[$key])) { $inctances[$key] = new self(); } return $instances[$key]; }
PHP統(tǒng)計(jì)腳本執(zhí)行時(shí)間
因?yàn)橄胫烂總€進(jìn)程花費(fèi)的時(shí)間是多少,因此寫個函數(shù)統(tǒng)計(jì)腳本執(zhí)行時(shí)間:
function microtime_float(){ list($u_sec, $sec) = explode(' ', microtime()); return (floatval($u_sec) + floatval($sec));}$start_time = microtime_float(); //do somethingusleep(100);$end_time = microtime_float();$total_time = $end_time - $start_time;$time_cost = sprintf("%.10f", $total_time);echo "program cost total " . $time_cost . "s/n";若文中有不正確的地方,望各位指出以便改正。
相關(guān)推薦:
nodejs爬蟲superagent和cheerio體驗(yàn)案例
NodeJS爬蟲詳解
Node.js爬蟲之網(wǎng)頁請求模塊詳解
以上就是PHP如何實(shí)現(xiàn)爬蟲的詳細(xì)內(nèi)容,更多請關(guān)注 其它相關(guān)文章!
鄭重聲明:本文版權(quán)歸原作者所有,轉(zhuǎn)載文章僅為傳播更多信息之目的,如作者信息標(biāo)記有誤,請第一時(shí)間聯(lián)系我們修改或刪除,多謝。
新聞熱點(diǎn)





疑難解答
圖片精選