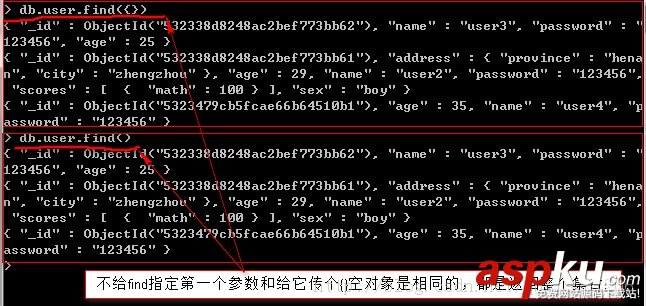
準(zhǔn)備
在此之前,我們先在我們的數(shù)據(jù)庫中插入10萬條數(shù)據(jù)。數(shù)據(jù)的格式是這樣的:
{ "name":"your name", "age":22, "gender":"male", "grade":2}explain
explain方法是用來查看db.collecion.find()的一些查詢信息的。例如:
db.collectionName.find().explain()
explain方法有個可選的參數(shù)verbose,是個字符串,他表示的是verbose的模式。一共分為3種模式:
queryPlanner:默認(rèn)參數(shù),詳細(xì)說明查詢優(yōu)化器選擇的計劃并列出被拒絕的計劃。例如:
db.students.find({grade:1}).explain() 
executionStats:MongoDB運(yùn)行查詢優(yōu)化器選擇獲勝的計劃,執(zhí)行計劃,完成并返回成功,統(tǒng)計描述的勝利計劃的執(zhí)行。例如:
db.students.find({grade:1}).explain("executionStats") 
allPlansExecution:MongoDB返回描述獲獎計劃的執(zhí)行以及對其他候選人統(tǒng)計計劃選擇方案時捕獲的統(tǒng)計。
我們的目的是要記錄執(zhí)行find方法的耗時時間,所以用executionStats模式就可以了。
返回的結(jié)果也是只關(guān)注executionStats就可以了,如下圖:

其他的屬性在這里就不多說了,記錄耗時我們只取executionTimeMills.
Profiling
上面提到的方法好像是只適用find方法,對于一些聚合查詢之類的查詢方法就無法統(tǒng)計耗時時間了。這里再介紹一個profiling方法記錄查詢耗時時間。
開啟 Profiling 功能
有兩種方式可以控制 Profiling 的開關(guān)和級別,第一種是直接在啟動參數(shù)里直接進(jìn)行設(shè)置。
db.setProfilingLevel(級別)命令來實(shí)時配置。可以通過db.getProfilingLevel()命令來獲取當(dāng)前的Profile級別。例如:
db.setProfilingLevel(2)db.getProfilingLevel()

Profiling一共分為3個級別:
Profile 記錄在級別1時會記錄慢命令,那么這個慢的定義是什么?上面我們說到其默認(rèn)為100ms,當(dāng)然有默認(rèn)就有設(shè)置,其設(shè)置方法和級別一樣有兩種,一種是通過添 加–slowms啟動參數(shù)配置。第二種是調(diào)用db.setProfilingLevel時加上第二個參數(shù):
db.setProfilingLevel( level , slowms)db.setProfilingLevel( 1 , 10 );
查詢 Profiling 記錄
開啟profiling功能后,系統(tǒng)會把相關(guān)命令詳細(xì)信息記錄到當(dāng)前數(shù)據(jù)庫的system.profile集合里。查詢方法也是跟普通的集合查詢一樣。
db.system.profile.find()

其中,mills就是命令耗時記錄。
由于我們設(shè)置的級別是2,所以所有命令都有記錄,現(xiàn)在我們把他改為級別1,且只記錄耗時20毫秒以上的記錄:
db.setProfilingLevel( 1 , 20)

然后我們再執(zhí)行一下聚合查詢,查看下耗時時間:
db.students.aggregate( {$group:{_id:"$grade",avgAge:{$avg:"$age"}}} ) 
db.system.profile.find().pretty()

可以看出,我們的這聚合查詢耗時70毫秒。
profile 部分字段解釋
下面介紹幾個常用的查詢命令:
列出執(zhí)行時間長于某一限度(例如:20ms)的 Profile 記錄.
db.system.profile.find({millis:{$gt:50}}) 
查看最新的 3條Profile 記錄:
db.system.profile.find().sort({$natural:-1}).limit(3) 
查看關(guān)于某個collection的相關(guān)慢查詢操作:
db.system.profile.find({ns:'mydb.students'})MongoDB 查詢優(yōu)化
docsExamined(掃描的記錄數(shù))遠(yuǎn)大于nreturned(返回結(jié)果的記錄數(shù))的話,那么我們就要考慮通過加索引來優(yōu)化記錄定位了。
responseLength 如果過大,那么說明我們返回的結(jié)果集太大了,這時請查看find函數(shù)的第二個參數(shù)是否只寫上了你需要的屬性名。(類似 于MySQL中不要總是select)
對于創(chuàng)建索引的建議是:如果很少讀,那么盡量不要添加索引,因?yàn)樗饕蕉啵瑢懖僮鲿铰H绻x量很大,那么創(chuàng)建索引還是比較劃算的。
Profiler 的效率
Profiling 功能肯定是會影響效率的,但是不太嚴(yán)重,原因是他使用的是system.profile 來記錄,而system.profile 是一個capped collection 這種collection 在操作上有一些限制和特點(diǎn),但是效率更高。
總結(jié)
以上就是這篇文章的全部內(nèi)容了,希望本文的內(nèi)容對大家的學(xué)習(xí)或者工作具有一定的參考學(xué)習(xí)價值,如果有疑問大家可以留言交流,謝謝大家對VEVB武林網(wǎng)的支持。
新聞熱點(diǎn)






疑難解答