對于一個net開發這爬蟲真真的以前沒有寫過。這段時間開始學習python爬蟲,今天周末無聊寫了一段代碼爬取上海租房圖片,其實很簡短就是利用爬蟲的第三方庫Requests與BeautifulSoup。python 版本:python3.6 ,IDE :pycharm。其實就幾行代碼,但希望沒有開發基礎的人也能一下子看明白,所以大神請繞行。
第三方庫首先安裝
我是用的pycharm所以另為的腳本安裝我這就不介紹了。
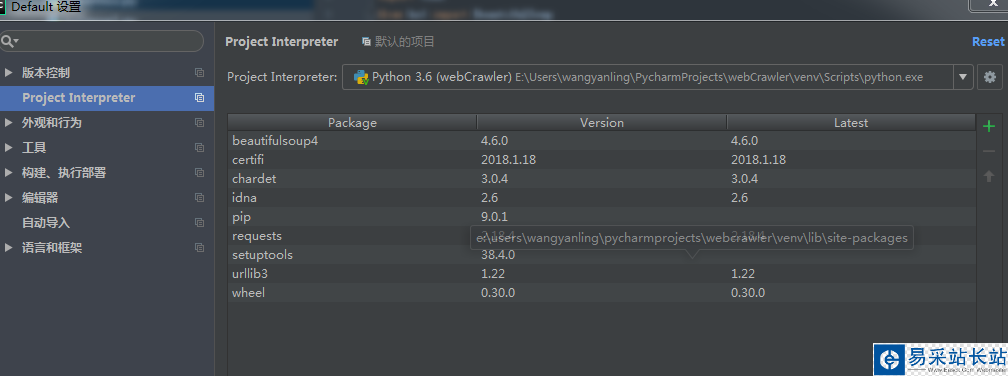
如上圖打開默認設置選擇Project Interprecter,雙擊pip或者點擊加號,搜索要安裝的第三方庫。其中如果建立的項目多記得Project Interprecter要選擇正確的安裝位置不然無法導入。
Requests庫
requests庫的官方定義:Requests 唯一的一個非轉基因的 Python HTTP 庫,人類可以安全享用。其實他就是請求網絡獲取網頁數據的。
import requestsheader={'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36'}res=requests.get('http://sh.58.com/zufang/',headers=header)try: print(res.text);except ConnectionError: print('訪問被拒絕!!!')結果如下:
其中Request Headers的參數如下:
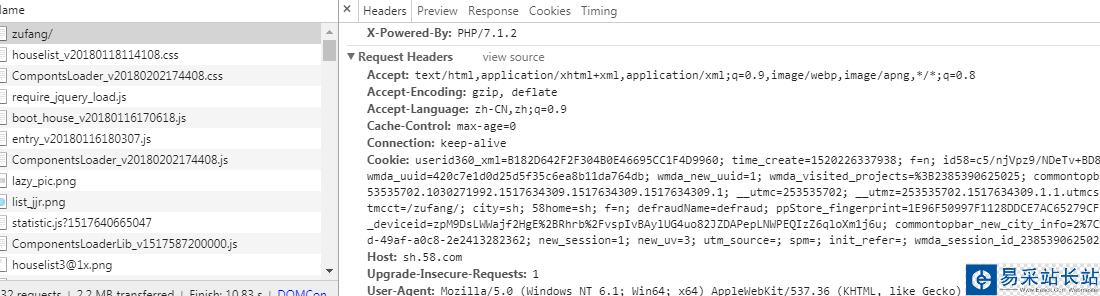
#headers的一些屬性:#Accept:指定客戶端能夠接收的內容類型,內容類型的先后次序表示客戶都接收的先后次序#Accept-Lanuage:指定HTTP客戶端瀏覽器用來展示返回信息優先選擇的語言#Accept-Encoding指定客戶端瀏覽器可以支持的web服務器返回內容壓縮編碼類型。表示允許服務器在將輸出內容發送到客戶端以前進行壓縮,以節約帶寬。而這里設置的就是客戶端瀏覽器所能夠支持的返回壓縮格式。#Accept-Charset:HTTP客戶端瀏覽器可以接受的字符編碼集# User-Agent : 有些服務器或 Proxy 會通過該值來判斷是否是瀏覽器發出的請求# Content-Type : 在使用 REST 接口時,服務器會檢查該值,用來確定 HTTP Body 中的內容該怎樣解析。# application/xml : 在 XML RPC,如 RESTful/SOAP 調用時使用# application/json : 在 JSON RPC 調用時使用# application/x-www-form-urlencoded : 瀏覽器提交 Web 表單時使用# 在使用服務器提供的 RESTful 或 SOAP 服務時, Content-Type 設置錯誤會導致服務器拒絕服務
BeautifulSoup庫
BeautifulSoup可以輕松的解析Requests庫請求的頁面,并把頁面源代碼解析為Soup文檔,一邊過濾提取數據。這是bs4.2的文檔。
Beautiful Soup支持Python標準庫中的HTML解析器,還支持一些第三方的解析器,如果我們不安裝它,則 Python 會使用 Python默認的解析器,其中lxml 據說是相對而言比較強大的我下面的暗示是python 標準庫的。
新聞熱點






疑難解答