寫在前面
上一篇文章Python實現識別手寫數字—圖像的處理中我們講了圖片的處理,將圖片經過剪裁,拉伸等操作以后將每一個圖片變成了1x10000大小的向量。但是如果只是這樣的話,我們每一次運行的時候都需要將他們計算一遍,當圖片特別多的時候會消耗大量的時間。
所以我們需要將這些向量存入一個文件當中,每次先看看圖庫中有沒有新增的圖片,如果有新增的圖片,那么就將新增的圖片變成1x10000向量再存入文件之中,然后從文件中讀取全部圖片向量即可。當圖庫中沒有新增圖片的時候,那么就直接調用文件中的圖片向量進行計算就好。這樣子算是節省了大量的時間。
所以本文就是從零開始建立一個這樣的圖片存儲管理系統。
實現邏輯
第一次讀入圖片
我們的圖庫中擁有一大堆圖片,每一張圖片上面都是一個手寫的數字,圖片的名稱為[數字內容]_[序號]。比如說一個圖片的名稱為2_3,代表這一張圖片里面的數字是2,并且是“數字是2的第3張圖片”。
存在一個csv文件作為我們的建議的圖片數據庫,名稱為Data.csv。
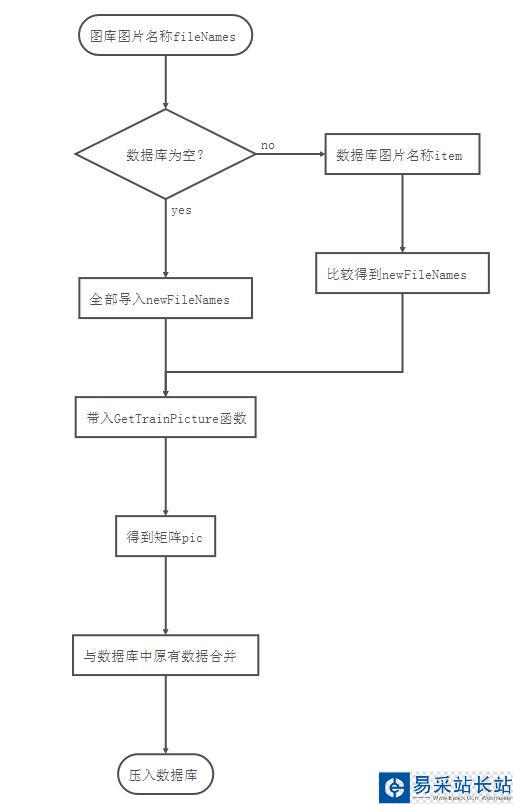
首先我們讀取圖庫中所有圖片的名稱,保存在fileNames中。然后讀取Data.csv中所有數據。
提取出Data.csv的最后一列(一共10002列,第10001列說明該數字是什么數字,第10002列是圖片的名稱),也就是數據庫中存儲的所有圖片的名稱,存儲在item中。
將新加入圖庫的圖片名稱保存在newFileNames中。如果Data.csv為空,那么就直接令newFileNames = fileNames。也就是說如果數據庫中什么也沒有,那么圖庫中所有圖片都是新加入的。
如果Data.csv不為空,那么就將item里面的內容與fileNames的內容比較,如果出現了fileNames里面有的名稱item中沒有,那么就將這些名稱放進newFileNames中。如果item里有的名稱fileNames中沒有,那就不管。
也就是說,我令我們的數據庫只進不出。
現在我們得到了新加入圖庫的圖片的名稱newFileNames。
將newFileNames中的名稱的圖片帶入上一文中函數GetTrainPicture進行處理,得到了一個nx10001的矩陣,每一行代表一個新加入的圖片,前10000列是圖片向量,第10001列是該圖片的數字,保存在pic中。
將這些圖片壓入到數據庫的后面。
讀取之前數據庫原有的圖片向量,并與pic合并,得到目前擁有的所有的訓練圖片向量pic。
以上就是本章寫的所有內容,下面放出代碼來詳細解釋一下。
代碼解析
主文件
import osimport numpy as npimport OperatePicture as OPimport OperateDataBase as ODimport csv##Essential vavriable 基礎變量#Standard size 標準大小N = 100#Gray threshold 灰度閾值color = 100/255#讀取原CSV文件reader = list(csv.reader(open('DataBase.csv', encoding = 'utf-8')))#清除讀取后的第一個空行del reader[0]#讀取num目錄下的所有文件名fileNames = os.listdir(r"./num/")#對比fileNames與reader,得到新增的圖片newFileNamesnewFileNames = OD.NewFiles(fileNames, reader)print('New pictures are: 'newFileNames)#得到newFilesNames對應的矩陣pic = OP.GetTrainPicture(newFileNames)#將新增圖片矩陣存入CSV中OD.SaveToCSV(pic, newFileNames)#將原數據庫矩陣與新數據庫矩陣合并pic = OD.Combination(reader, pic)
新聞熱點






疑難解答