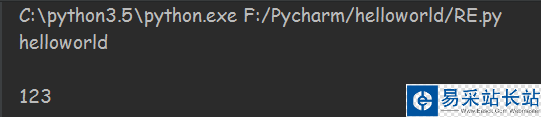
這是一個最簡單的圖像識別,將圖片加載后直接利用Python的一個識別引擎進行識別
將圖片中的數字通過 pytesseract.image_to_string(image)識別后將結果存入到本地的txt文件中
#-*-encoding:utf-8-*- import pytesseract from PIL import Image class GetImageDate(object): def m(self): image = Image.open(u"C://a.png") text = pytesseract.image_to_string(image) return text def SaveResultToDocument(self): text = self.m() f = open(u"C://Verification.txt","w") print text f.write(str(text)) f.close() g = GetImageDate() g.SaveResultToDocument()
具體想要實現上面的代碼需要安裝兩個包和一個引擎
在安裝之前需要先安裝好Python,pip并配置好環境變量
所有包的安裝都是通過pip來安裝的,需要在windows PowerShell中進行,并且是在 C:/Python27/Scripts目錄下
1.第一個包: pytesseract
pip install pytesseract
若是出現安裝錯誤的情況,安裝不了的時候,可以將命令改為 pip.exe install pytesseract來安裝
若是將pip修改為pip.exe安裝成功后,那么下文的所有pip都需要改為pip.exe
2.第二個包:PIL安裝
pip install PIL
若是失敗了可以如下修改 pip install PILLOW
3.安裝識別引擎tesseract-ocr
下載 tesseract-ocr,進行默認安裝
安裝完成后需要配置環境變量,在系統變量path后增加 tesseract-ocr的安裝地址C:/Program Files (x86)/Tesseract-OCR;
一切都安裝完成后運行上述代碼,會發現報錯,此時需要
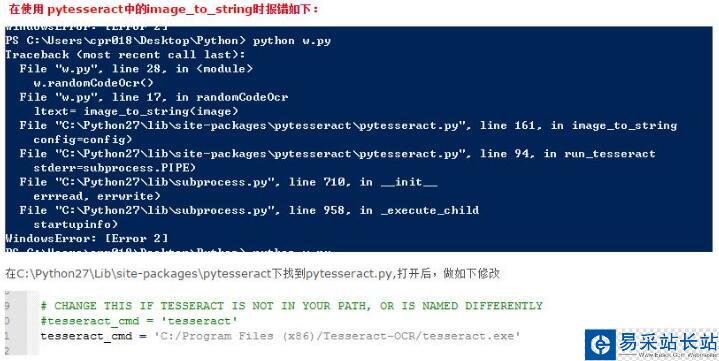
至此結束。
以上就是本文的全部內容,希望對大家的學習有所幫助,也希望大家多多支持武林站長站。
新聞熱點






疑難解答