前言:
作為一名從小就看籃球的球迷,會經(jīng)常逛虎撲籃球及濕乎乎等論壇,在論壇里面會存在很多精美圖片,包括NBA球隊、CBA明星、花邊新聞、球鞋美女等等,如果一張張右鍵另存為的話真是手都點疼了。作為程序員還是寫個程序來進行吧!
所以我通過Python+Selenium+正則表達式+urllib2進行海量圖片爬取。
運行效果:
http://photo.hupu.com/nba/tag/馬刺
http://photo.hupu.com/nba/tag/陳露
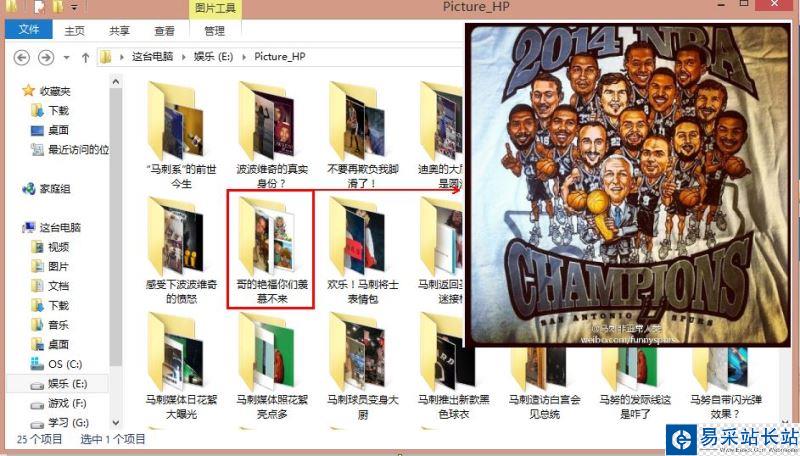
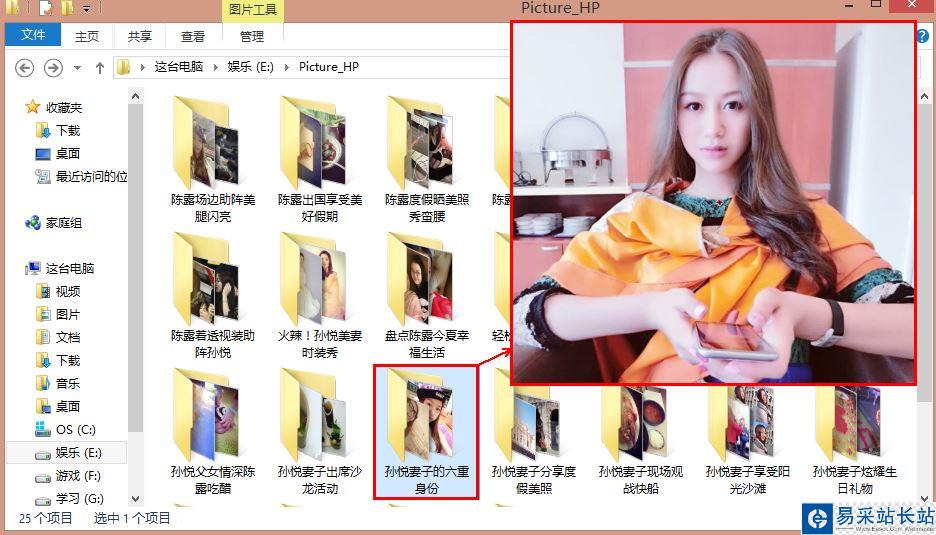
源代碼:
# -*- coding: utf-8 -*- """ Crawling pictures by selenium and urlliburl: 虎撲 馬刺 http://photo.hupu.com/nba/tag/%E9%A9%AC%E5%88%BAurl: 虎撲 陳露 http://photo.hupu.com/nba/tag/%E9%99%88%E9%9C%B2Created on 2015-10-24@author: Eastmount CSDN """ import time import re import os import sys import urllib import shutil import datetime from selenium import webdriver from selenium.webdriver.common.keys import Keys import selenium.webdriver.support.ui as ui from selenium.webdriver.common.action_chains import ActionChains #Open PhantomJS driver = webdriver.PhantomJS(executable_path="G:/phantomjs-1.9.1-windows/phantomjs.exe")#driver = webdriver.Firefox() wait = ui.WebDriverWait(driver,10) #Download one Picture By urllib def loadPicture(pic_url, pic_path): pic_name = os.path.basename(pic_url) #刪除路徑獲取圖片名字 pic_name = pic_name.replace('*','') #去除'*' 防止錯誤 invalid mode ('wb') or filename urllib.urlretrieve(pic_url, pic_path + pic_name) #爬取具體的圖片及下一張def getScript(elem_url, path, nums): try: #由于鏈接 http://photo.hupu.com/nba/p29556-1.html #只需拼接 http://..../p29556-數(shù)字.html 省略了自動點擊"下一張"操作 count = 1 t = elem_url.find(r'.html') while (count <= nums): html_url = elem_url[:t] + '-' + str(count) + '.html' #print html_url ''' driver_pic.get(html_url) elem = driver_pic.find_element_by_xpath("http://div[@class='pic_bg']/div/img") url = elem.get_attribute("src") ''' #采用正則表達式獲取第3個<div></div> 再獲取圖片URL進行下載 content = urllib.urlopen(html_url).read() start = content.find(r'<div class="flTab">') end = content.find(r'<div class="comMark" style>') content = content[start:end] div_pat = r'<div.*?>(.*?)<//div>' div_m = re.findall(div_pat, content, re.S|re.M) #print div_m[2] link_list = re.findall(r"(?<=href=/").+?(?=/")|(?<=href=/').+?(?=/')", div_m[2]) #print link_list url = link_list[0] #僅僅一條url鏈接 loadPicture(url, path) count = count + 1 except Exception,e: print 'Error:',e finally: print 'Download ' + str(count) + ' pictures/n' #爬取主頁圖片集的URL和主題 def getTitle(url): try: #爬取URL和標題 count = 0 print 'Function getTitle(key,url)' driver.get(url) wait.until(lambda driver: driver.find_element_by_xpath("http://div[@class='piclist3']")) print 'Title: ' + driver.title + '/n' #縮略圖片url(此處無用) 圖片數(shù)量 標題(文件名) 注意順序 elem_url = driver.find_elements_by_xpath("http://a[@class='ku']/img") elem_num = driver.find_elements_by_xpath("http://div[@class='piclist3']/table/tbody/tr/td/dl/dd[1]") elem_title = driver.find_elements_by_xpath("http://div[@class='piclist3']/table/tbody/tr/td/dl/dt/a") for url in elem_url: pic_url = url.get_attribute("src") html_url = elem_title[count].get_attribute("href") print elem_title[count].text print html_url print pic_url print elem_num[count].text #創(chuàng)建圖片文件夾 path = "E://Picture_HP//" + elem_title[count].text + "http://" m = re.findall(r'(/w*[0-9]+)/w*', elem_num[count].text) #爬蟲圖片張數(shù) nums = int(m[0]) count = count + 1 if os.path.isfile(path): #Delete file os.remove(path) elif os.path.isdir(path): #Delete dir shutil.rmtree(path, True) os.makedirs(path) #create the file directory getScript(html_url, path, nums) #visit pages except Exception,e: print 'Error:',e finally: print 'Find ' + str(count) + ' pages with key/n' #Enter Function def main(): #Create Folder basePathDirectory = "E://Picture_HP" if not os.path.exists(basePathDirectory): os.makedirs(basePathDirectory) #Input the Key for search str=>unicode=>utf-8 key = raw_input("Please input a key: ").decode(sys.stdin.encoding) print 'The key is : ' + key #Set URL List Sum:1-2 Pages print 'Ready to start the Download!!!/n/n' starttime = datetime.datetime.now() num=1 while num<=1: #url = 'http://photo.hupu.com/nba/tag/%E9%99%88%E9%9C%B2?p=2&o=1' url = 'http://photo.hupu.com/nba/tag/%E9%A9%AC%E5%88%BA' print '第'+str(num)+'頁','url:'+url #Determine whether the title contains key getTitle(url) time.sleep(2) num = num + 1 else: print 'Download Over!!!' #get the runtime endtime = datetime.datetime.now() print 'The Running time : ',(endtime - starttime).seconds main()
新聞熱點






疑難解答













