聚類
今天說(shuō)K-means聚類算法,但是必須要先理解聚類和分類的區(qū)別,很多業(yè)務(wù)人員在日常分析時(shí)候不是很嚴(yán)謹(jǐn),混為一談,其實(shí)二者有本質(zhì)的區(qū)別。
分類其實(shí)是從特定的數(shù)據(jù)中挖掘模式,作出判斷的過(guò)程。比如Gmail郵箱里有垃圾郵件分類器,一開(kāi)始的時(shí)候可能什么都不過(guò)濾,在日常使用過(guò)程中,我人工對(duì)于每一封郵件點(diǎn)選“垃圾”或“不是垃圾”,過(guò)一段時(shí)間,Gmail就體現(xiàn)出一定的智能,能夠自動(dòng)過(guò)濾掉一些垃圾郵件了。這是因?yàn)樵邳c(diǎn)選的過(guò)程中,其實(shí)是給每一條郵件打了一個(gè)“標(biāo)簽”,這個(gè)標(biāo)簽只有兩個(gè)值,要么是“垃圾”,要么“不是垃圾”,Gmail就會(huì)不斷研究哪些特點(diǎn)的郵件是垃圾,哪些特點(diǎn)的不是垃圾,形成一些判別的模式,這樣當(dāng)一封信的郵件到來(lái),就可以自動(dòng)把郵件分到“垃圾”和“不是垃圾”這兩個(gè)我們?nèi)斯ぴO(shè)定的分類的其中一個(gè)。
聚類的的目的也是把數(shù)據(jù)分類,但是事先我是不知道如何去分的,完全是算法自己來(lái)判斷各條數(shù)據(jù)之間的相似性,相似的就放在一起。在聚類的結(jié)論出來(lái)之前,我完全不知道每一類有什么特點(diǎn),一定要根據(jù)聚類的結(jié)果通過(guò)人的經(jīng)驗(yàn)來(lái)分析,看看聚成的這一類大概有什么特點(diǎn)。
1、概述
k-means是一種非常常見(jiàn)的聚類算法,在處理聚類任務(wù)中經(jīng)常使用。K-means算法是集簡(jiǎn)單和經(jīng)典于一身的基于距離的聚類算法
采用距離作為相似性的評(píng)價(jià)指標(biāo),即認(rèn)為兩個(gè)對(duì)象的距離越近,其相似度就越大。
該算法認(rèn)為類簇是由距離靠近的對(duì)象組成的,因此把得到緊湊且獨(dú)立的簇作為最終目標(biāo)。
2、核心思想
通過(guò)迭代尋找k個(gè)類簇的一種劃分方案,使得用這k個(gè)類簇的均值來(lái)代表相應(yīng)各類樣本時(shí)所得的總體誤差最小。
k個(gè)聚類具有以下特點(diǎn):各聚類本身盡可能的緊湊,而各聚類之間盡可能的分開(kāi)。
k-means算法的基礎(chǔ)是最小誤差平方和準(zhǔn)則,
其代價(jià)函數(shù)是:

式中,μc(i)表示第i個(gè)聚類的均值。
各類簇內(nèi)的樣本越相似,其與該類均值間的誤差平方越小,對(duì)所有類所得到的誤差平方求和,即可驗(yàn)證分為k類時(shí),各聚類是否是最優(yōu)的。
上式的代價(jià)函數(shù)無(wú)法用解析的方法最小化,只能有迭代的方法。
3、算法步驟圖解
下圖展示了對(duì)n個(gè)樣本點(diǎn)進(jìn)行K-means聚類的效果,這里k取2。
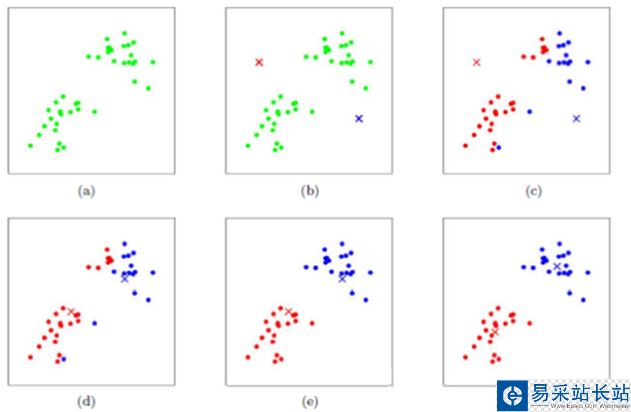
4、算法實(shí)現(xiàn)步驟
k-means算法是將樣本聚類成 k個(gè)簇(cluster),其中k是用戶給定的,其求解過(guò)程非常直觀簡(jiǎn)單,具體算法描述如下:
1)隨機(jī)選取 k個(gè)聚類質(zhì)心點(diǎn)
新聞熱點(diǎn)






疑難解答
圖片精選













