從實時視頻流中識別出人臉區域,從原理上看,其依然屬于機器學習的領域之一,本質上與谷歌利用深度學習識別出貓沒有什么區別。程序通過大量的人臉圖片數據進行訓練,利用數學算法建立建立可靠的人臉特征模型,如此即可識別出人臉。幸運的是,這些工作OpenCV已經幫我們做了,我們只需調用對應的API函數即可,先給出代碼:
#-*- coding: utf-8 -*-import cv2import sysfrom PIL import Imagedef CatchUsbVideo(window_name, camera_idx): cv2.namedWindow(window_name) #視頻來源,可以來自一段已存好的視頻,也可以直接來自USB攝像頭 cap = cv2.VideoCapture(camera_idx) #告訴OpenCV使用人臉識別分類器 classfier = cv2.CascadeClassifier("/usr/local/share/OpenCV/haarcascades/haarcascade_frontalface_alt2.xml") #識別出人臉后要畫的邊框的顏色,RGB格式 color = (0, 255, 0) while cap.isOpened(): ok, frame = cap.read() #讀取一幀數據 if not ok: break #將當前幀轉換成灰度圖像 grey = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY) #人臉檢測,1.2和2分別為圖片縮放比例和需要檢測的有效點數 faceRects = classfier.detectMultiScale(grey, scaleFactor = 1.2, minNeighbors = 3, minSize = (32, 32)) if len(faceRects) > 0: #大于0則檢測到人臉 for faceRect in faceRects: #單獨框出每一張人臉 x, y, w, h = faceRect cv2.rectangle(frame, (x - 10, y - 10), (x + w + 10, y + h + 10), color, 2) #顯示圖像 cv2.imshow(window_name, frame) c = cv2.waitKey(10) if c & 0xFF == ord('q'): break #釋放攝像頭并銷毀所有窗口 cap.release() cv2.destroyAllWindows() if __name__ == '__main__': if len(sys.argv) != 2: print("Usage:%s camera_id/r/n" % (sys.argv[0])) else: CatchUsbVideo("識別人臉區域", int(sys.argv[1]))先看一下程序輸出結果:
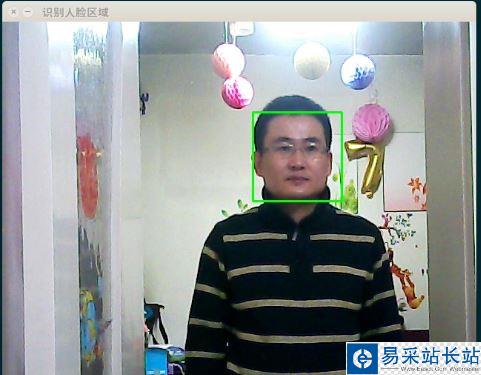
程序正確的識別出了我的臉,加上空白行不到50行代碼,還是很簡單的。當然,絕大部分的工作OpenCV已經默默地替我們做了,所以我們用起來才這么簡單。關于代碼有幾個地方需要重點交代,首先就是人臉分類器這行:
#告訴OpenCV使用人臉識別分類器classfier = cv2.CascadeClassifier("/usr/local/share/OpenCV/haarcascades/haarcascade_frontalface_alt2.xml")這行代碼指定OpenCV選擇使用哪種分類器(注意,一定習慣分類這個說法,ML的監督學習研究的就是各種分類問題),OpenCV提供了多種分類器:
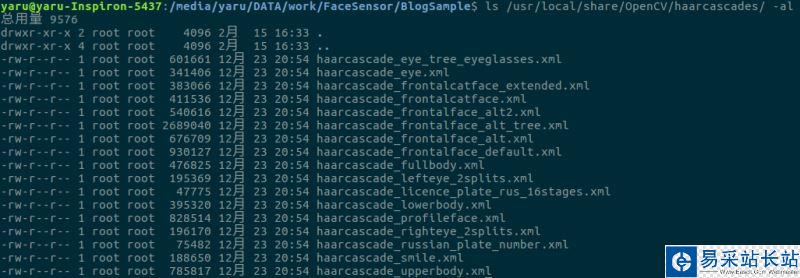
上圖為我的電腦上安裝的OpenCV3.2提供的所有分類器,有識別眼睛的(甚至包括左右眼),有識別身體的,有識別笑臉的,甚至還有識別貓臉的,有興趣的可以逐個試試。關于人臉識別,OpenCV提供多個分類器選擇使用,其中haarcascade_frontalface_alt_tree.xml是最嚴格的分類器,光線、帶個帽子都有可能識別不出人臉。其它的稍微好點,default那個識別最寬松,某些情況下我家里的燈籠都會被識別成人臉;)。另外安裝環境不同,分類器的安裝路徑也有可能不同,請在安裝完OpenCV后根據分類器的實際安裝路徑修改代碼。另外再多說一句,如果我們想構建自己的分類器,比如檢測火焰(火災報警)、汽車(確定路口汽車數量),我們依然可以使用OpenCV訓練構建,詳細說明參見OpenCV的官方文檔。
新聞熱點






疑難解答













