概述
語音識別是當前人工智能的比較熱門的方向,技術也比較成熟,各大公司也相繼推出了各自的語音助手機器人,如百度的小度機器人、阿里的天貓精靈等。語音識別算法當前主要是由RNN、LSTM、DNN-HMM等機器學習和深度學習技術做支撐。但訓練這些模型的第一步就是將音頻文件數據化,提取當中的語音特征。
MP3文件轉化為WAV文件
錄制音頻文件的軟件大多數都是以mp3格式輸出的,但mp3格式文件對語音的壓縮比例較重,因此首先利用ffmpeg將轉化為wav原始文件有利于語音特征的提取。其轉化代碼如下:
from pydub import AudioSegmentimport pydubdef MP32WAV(mp3_path,wav_path): """ 這是MP3文件轉化成WAV文件的函數 :param mp3_path: MP3文件的地址 :param wav_path: WAV文件的地址 """ pydub.AudioSegment.converter = "D://ffmpeg//bin//ffmpeg.exe" MP3_File = AudioSegment.from_mp3(file=mp3_path) MP3_File.export(wav_path,format="wav")
讀取WAV語音文件,對語音進行采樣
利用wave庫對語音文件進行采樣。
代碼如下:
import waveimport jsondef Read_WAV(wav_path): """ 這是讀取wav文件的函數,音頻數據是單通道的。返回json :param wav_path: WAV文件的地址 """ wav_file = wave.open(wav_path,'r') numchannel = wav_file.getnchannels() # 聲道數 samplewidth = wav_file.getsampwidth() # 量化位數 framerate = wav_file.getframerate() # 采樣頻率 numframes = wav_file.getnframes() # 采樣點數 print("channel", numchannel) print("sample_width", samplewidth) print("framerate", framerate) print("numframes", numframes) Wav_Data = wav_file.readframes(numframes) Wav_Data = np.fromstring(Wav_Data,dtype=np.int16) Wav_Data = Wav_Data*1.0/(max(abs(Wav_Data))) #對數據進行歸一化 # 生成音頻數據,ndarray不能進行json化,必須轉化為list,生成JSON dict = {"channel":numchannel, "samplewidth":samplewidth, "framerate":framerate, "numframes":numframes, "WaveData":list(Wav_Data)} return json.dumps(dict)繪制聲波折線圖與頻譜圖
代碼如下:
from matplotlib import pyplot as pltdef DrawSpectrum(wav_data,framerate): """ 這是畫音頻的頻譜函數 :param wav_data: 音頻數據 :param framerate: 采樣頻率 """ Time = np.linspace(0,len(wav_data)/framerate*1.0,num=len(wav_data)) plt.figure(1) plt.plot(Time,wav_data) plt.grid(True) plt.show() plt.figure(2) Pxx, freqs, bins, im = plt.specgram(wav_data,NFFT=1024,Fs = 16000,noverlap=900) plt.show() print(Pxx) print(freqs) print(bins) print(im)
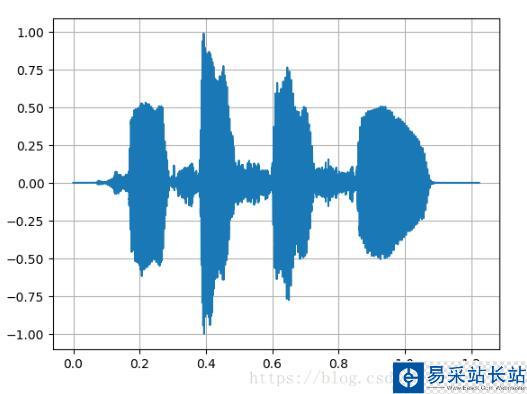
首先利用百度AI開發平臺的語音合API生成的MP3文件進行上述過程的結果。
聲波折線圖
頻譜圖
新聞熱點






疑難解答













