爬蟲:一段自動抓取互聯網信息的程序,從互聯網上抓取對于我們有價值的信息,一般來說,Python爬蟲程序很多時候都要使用(飛豬IP)代理的IP地址來爬取程序,但是默認的urlopen是無法使用代理的IP的,我就來分享一下Python爬蟲怎樣使用代理IP的經驗。(推薦飛豬代理IP注冊可免費使用,瀏覽器搜索可找到)

1、劃重點,小編我用的是Python3哦,所以要導入urllib的request,然后我們調用ProxyHandler,它可以接收代理IP的參數。代理可以根據自己需要選擇,當然免費的也是有的,但是可用率可想而知的。(飛豬IP)
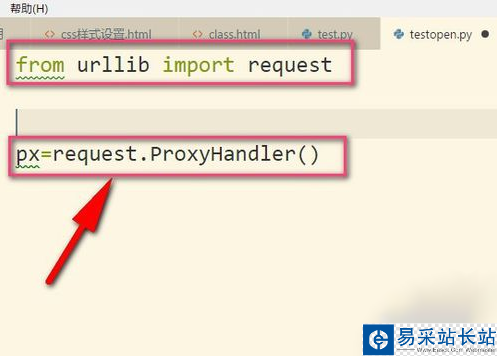
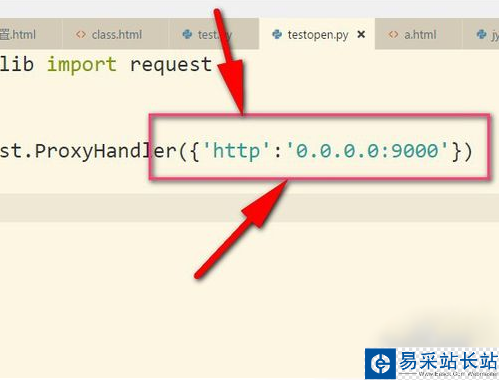
2、接著把IP地址以字典的形式放入其中,這個IP地址是我亂寫的,只是用來舉例。設置鍵為http,當然有些是https的,然后后面就是IP地址以及端口號(9000),具體看你的IP地址是什么類型的,不同IP端口號可能不同根據你在飛豬提取的端口為準。
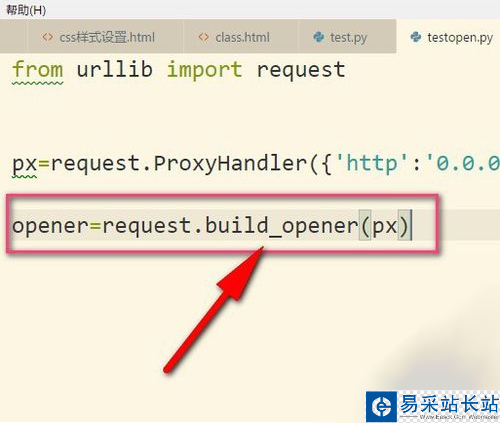
3、接著再用build_opener()來構建一個opener對象。
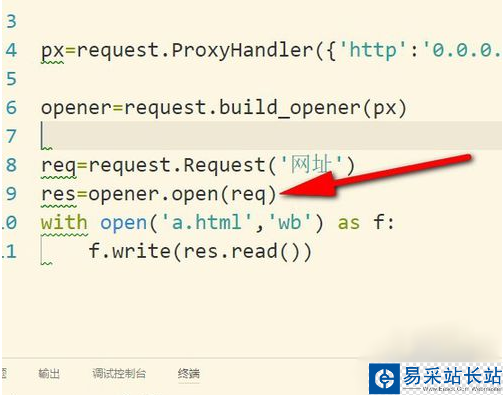
4、然后調用構建好的opener對象里面的open方法來發生請求。實際上urlopen也是類似這樣使用內部定義好的opener.open(),這里就相當于我們自己重寫。
5、當然了,如果我們使用install_opener(),就可以把之前自定義的opener設置成全局的。
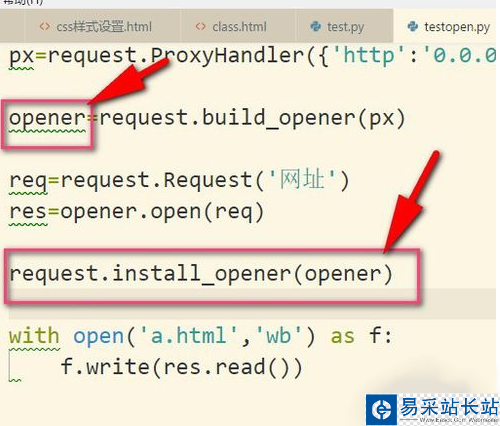
6、設置成全局之后,如果我們再使用urlopen來發送請求,那么發送請求使用的IP地址就是代理IP,而不是本機的IP地址了。
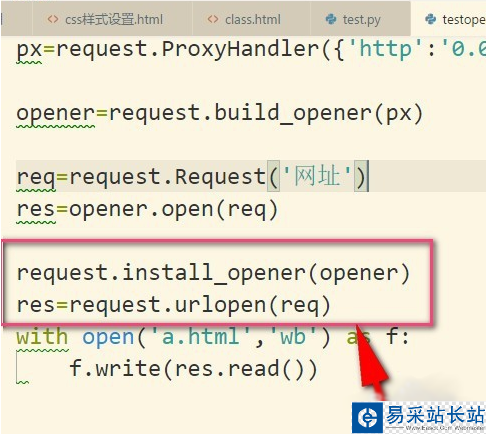
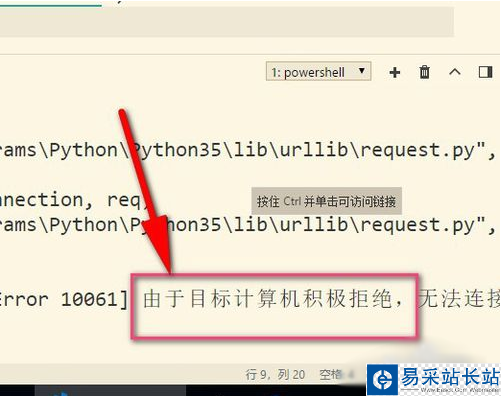
7、最后再來說說使用代理遇到的錯誤,提示目標計算機積極拒絕,這就說明可能是代理IP無效,或者端口號錯誤,這就需要使用有效的IP才行哦。(這邊現在是亂填寫的IP地址)可選擇飛豬的代理IP。
總結:以上就是本次關于Python數據抓取爬蟲代理防封IP方法,感謝大家的閱讀和對武林站長站的支持。
新聞熱點






疑難解答













