測試代碼1:
def test(self): data = {"add": {"doc": {"id": "100001", "*字段名*": u"我是一個大好人"}}} params = {"boost": 1.0, "overwrite": "true", "commitWithin": 1000} url = 'http://127.0.0.1:8983/solr/mycore/update?wt=json' headers = {"Content-Type": "application/json"} r = requests.post(url, json=data, params=params, headers=headers) print r.text def Index_data(self): solr = pysolr.Solr('http://127.0.0.1:8983/solr/mycore/', timeout=10) # How you'd index data. result = solr.add([ { "id": "doc_1", "title": "A test document", }, { "id": "doc_2", "title": "The Banana: Tasty or Dangerous?", }, ]) print result測試代碼2:
實際數據:
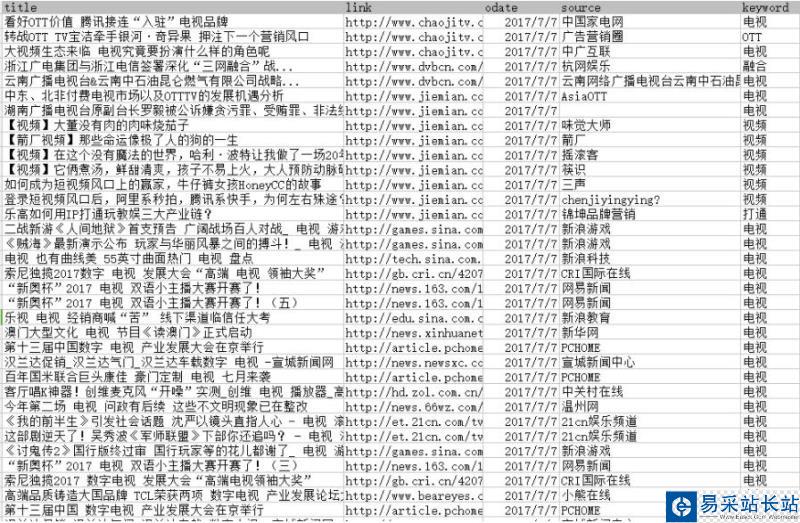
def Index_Data_FromCSV(self, csvfile): ''' 從CSV文件中讀取數據,并索引到solr中 :param csvfile: csv文件,包括完整路徑 :return: ''' list = CSVOP.ReadCSV(csvfile) index = 0 doc = {} params = {"boost": 1.0, "overwrite": "true", "commitWithin": 1000} url = 'http://127.0.0.1:8983/solr/mycore/update?wt=json' headers = {"Content-Type": "application/json"} for item in list: if index > 0: # 第一行是標題 try: doc['title'] = item[0].decode('GB2312') doc['link'] = item[1] # doc['date'] = item[2] doc['source'] = item[3].decode('GB2312') doc['keyword'] = item[4].decode('GB2312') data = {"add": {"doc": doc}} r = requests.post(url, json=data, params=params, headers=headers) print r.text except Exception,e: print e.message print index index += 1#pysolr客戶端代碼 def pysolr_Index_Data_FromCSV(self, csvfile,url='http://127.0.0.1:8983/solr/mycore/'): ''' 從CSV文件中讀取數據,并索引到solr中 :param csvfile: csv文件,包括完整路徑 :return: ''' list = CSVOP.ReadCSV(csvfile) index = 0 listdocs = [] for item in list: if index > 0: # 第一行是標題 doc = {} try: doc['title'] = item[0].decode('GB2312') doc['link'] = item[1] # doc['date'] = item[2] doc['source'] = item[3].decode('GB2312') doc['keyword'] = item[4].decode('GB2312') listdocs.append(doc) except Exception,e: print e.message index += 1 solr = pysolr.Solr(url, timeout=10) result = solr.add(listdocs) print result查詢代碼:
def search_data(self,message='視頻'): url = 'http://127.0.0.1:8983/solr/mycore/select?q=title:"/%s"&wt=json&indent=true' % message r = requests.get(url, verify=False) print r.text r = r.json()['response']['numFound'] print message + ":" + str(r) #pysolr客戶端 def search_data(self,where='視頻',url='http://127.0.0.1:8983/solr/mycore/'): solr = pysolr.Solr(url, timeout=10) dict = {'start':10,'rows': 30,'fl':'title,keyword,source,link'} result = solr.search('title:視頻',**dict) # result = solr.search('title:視頻') # print result.raw_response['response']['numFound'] for item in result: print 'keyword: %s'% item['keyword'] print 'title: %s'% item['title'] print 'source: %s'% item['source'] print 'link: %s'% item['link'] print '
新聞熱點






疑難解答













