1. apply與transform
首先講一下apply() 與transform()的相同點與不同點
相同點:
都能針對dataframe完成特征的計算,并且常常與groupby()方法一起使用。
不同點:
apply()里面可以跟自定義的函數,包括簡單的求和函數以及復雜的特征間的差值函數等(注:apply不能直接使用agg()方法 / transform()中的python內置函數,例如sum、max、min、'count‘等方法)
transform() 里面不能跟自定義的特征交互函數,因為transform是真針對每一元素(即每一列特征操作)進行計算,也就是說在使用 transform() 方法時,需要記得三點:
1、它只能對每一列進行計算,所以在groupby()之后,.transform()之前是要指定要操作的列,這點也與apply有很大的不同。
2、由于是只能對每一列計算,所以方法的通用性相比apply()就局限了很多,例如只能求列的最大/最小/均值/方差/分箱等操作
3、transform還有什么用呢?最簡單的情況是試圖將函數的結果分配回原始的dataframe。也就是說返回的shape是(len(df),1)。注:如果與groupby()方法聯合使用,需要對值進行去重
2. 各方法耗時
分別計算在同樣簡單需求下各組合方法的計算時長
2.1 transform() 方法+自定義函數
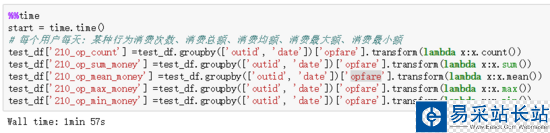
2.2 transform() 方法+python內置方法

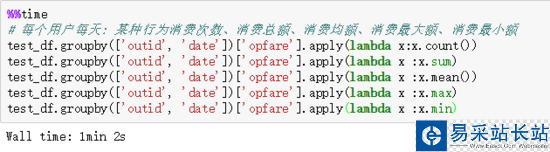
2.3 apply() 方法+自定義函數
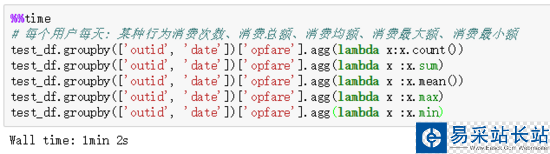
2.4 agg() 方法+自定義函數
新聞熱點






疑難解答













