這篇文章主要介紹了詳解SQLite中的查詢規(guī)劃器,SQLite是一個(gè)開源的嵌入式數(shù)據(jù)庫,需要的朋友可以參考下
1.0 介紹
查詢規(guī)劃器的任務(wù)是找到最好的算法或者說“查詢計(jì)劃”來完成一條SQL語句。早在SQLite 3.8.0版本,查詢規(guī)劃器的組成部分已經(jīng)被重寫使它可以運(yùn)行更快并且生成更好的查詢計(jì)劃。這種重寫被稱作“下一代查詢規(guī)劃器”或者“NGQP”。
這篇文章重新概括了查詢規(guī)劃的重要性,提出來一些查詢規(guī)劃固有的問題,并且概括了NGQP是如何解決這些問題。
我們知道的是,NGQP(下一代查詢規(guī)劃器)幾乎總是比舊版本的查詢規(guī)劃器好。然而,也許有的應(yīng)用程序在舊版本的查詢規(guī)劃器中已經(jīng)不知不覺依賴了一些不確定或者不是很好的特性,這時(shí)候?qū)⒉樵円?guī)劃器更新升級到NGQP,這些應(yīng)用程序可能會導(dǎo)致程序閃退現(xiàn)象。NGQP必須考慮這種風(fēng)險(xiǎn),提供一系列的檢查項(xiàng)來減小風(fēng)險(xiǎn)和解決可能會引起的問題。
在NGOP上關(guān)注此文檔。對于更一般的sqlite查詢規(guī)劃器以及涵蓋sqlite整個(gè)歷史的概述,請參閱:“sqlite查詢優(yōu)化程序概述”。
2.0 背景
對于用簡單的幾個(gè)指數(shù)對單個(gè)表的查詢,通常會有一個(gè)明顯的最佳的算法選擇。但是對于更大更復(fù)雜的查詢,諸如眾多指數(shù)與子查詢的多路連接,對于計(jì)算結(jié)果,可能有數(shù)百,數(shù)千或者數(shù)百萬的合理算法。如此查詢規(guī)劃的工作是選擇一個(gè)單一的“最好”的有眾多可能性的查詢計(jì)劃。
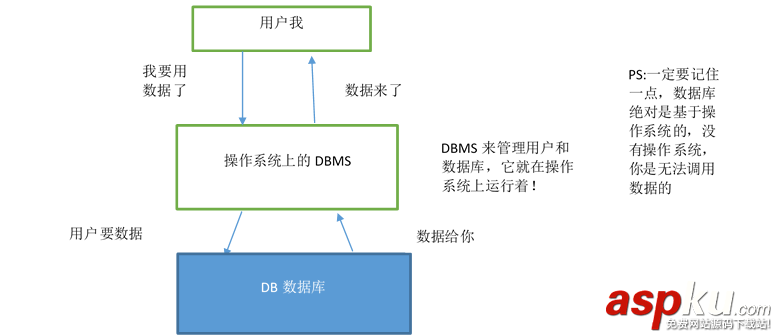
查詢規(guī)劃器是什么使得SQL數(shù)據(jù)庫引擎變得如此驚人的有用與強(qiáng)大。(這是真正的所有的sql數(shù)據(jù)庫引擎,不只是sqlite。)查詢規(guī)劃器使得編程人員從苦差事中選擇一個(gè)特定的查詢計(jì)劃之中釋放出來。從而允許程序員在更高級別的應(yīng)用問題里和向最終端用戶提供更多的價(jià)值之上可以關(guān)注更多的心理能量。對于簡單的查詢,查詢計(jì)劃的選擇是顯而易見的,雖然是方便的,但并不是很重要的。但是作為應(yīng)用程序,架構(gòu)與查詢將會變得越來越復(fù)雜化。一個(gè)聰明的查詢規(guī)劃可以大大地加速和簡化應(yīng)用程序開發(fā)的工作。它告訴數(shù)據(jù)庫引擎有什么內(nèi)容需求是有著驚人的力量的,然后,讓數(shù)據(jù)庫引擎找出最好的辦法檢索那些內(nèi)容。
寫一個(gè)好的查詢規(guī)劃器是藝術(shù)多于科學(xué)。查詢規(guī)劃器必須要有不完整的信息。它不能決定將多久采取任何特別的計(jì)劃,而實(shí)際上無需運(yùn)行此計(jì)劃。因此,當(dāng)比較兩個(gè)或多個(gè)計(jì)劃時(shí),找出哪些是“最好的”,查詢規(guī)劃器會做出一些假設(shè)和猜測,那些假設(shè)和猜測有時(shí)候會出錯(cuò)。一個(gè)好的查詢計(jì)劃要求能找到正確的解決方案,而這些問題是程序員很少考慮的。
2.1 sqlite之中的查詢規(guī)劃器
sqlite的計(jì)算使用嵌套循環(huán)聯(lián)接,一個(gè)循環(huán)中每個(gè)標(biāo)的連接(額外的循環(huán)可能會在WHERE句子中插入IN和OR運(yùn)算符。sqlite認(rèn)為那些考慮太多啦,但為了簡單起見,我們可以在這篇文章之中可以忽略它。)在每次循環(huán)時(shí),一個(gè)或者更多的指數(shù)被使用,并被加速搜索,或者一個(gè)循環(huán)可能是“全表掃描”讀取表中每一行。因此,查詢規(guī)劃分解成兩個(gè)子任務(wù):
采摘的各種循環(huán)的嵌套順序。
選擇每個(gè)循環(huán)的良好指數(shù)。
采摘嵌套順序一般是更具挑戰(zhàn)性地問題。
一旦建立連接的嵌套順序,每個(gè)循環(huán)指數(shù)的選擇通常是顯而易見的。
2.2 SQLite查詢規(guī)劃器穩(wěn)定性保證
對于給出的任何SQL語句,SQLite 通常情況下會選擇相同的查詢規(guī)劃假如:
數(shù)據(jù)庫的schema沒有明顯的改變,例如添加或刪除索引(indices),
ANALYZE命令沒有返回
SQLite在編譯時(shí)沒有使用SQLITE_ENABLE_STAT3或者SQLITE_ENABLE_STAT4,并且
使用相同版本的SQLite
SQLite的穩(wěn)定性保證意味著你在測試中高效的運(yùn)行查詢操作,并且你的應(yīng)用沒有更改schema,那么SQLite不會突然選擇開始使用一個(gè)不同的查詢規(guī)劃,那樣有可能在你把你的應(yīng)用發(fā)布給用戶之后造成性能問題。如果在實(shí)驗(yàn)室里你的應(yīng)用是工作的,那它在部署之后同樣可以工作。
企業(yè)級的客戶端/服務(wù)器SQL數(shù)據(jù)庫通常不能做這樣的保證。在客戶端/服務(wù)器SQL數(shù)據(jù)庫引擎里,服務(wù)器跟蹤統(tǒng)計(jì)表的大小和索引(indices)的數(shù)量,查詢規(guī)劃器根據(jù)這些統(tǒng)計(jì)信息選擇最優(yōu)的規(guī)劃。一旦在數(shù)據(jù)庫的內(nèi)容通過增刪改改變,統(tǒng)計(jì)信息的改變有可能引起對于某些特定的查詢,查詢規(guī)劃器使用不同的查詢規(guī)劃。通常新的規(guī)劃對于更改過的數(shù)據(jù)結(jié)構(gòu)來說更好。但有時(shí)新的查詢規(guī)劃會導(dǎo)致性能的下降。在使用客戶端/服務(wù)器數(shù)據(jù)庫引擎時(shí),通常會有一個(gè)數(shù)據(jù)庫管理員(DBA)來處理這些罕見的問題。但是DBA們不能在像SQLite這樣的嵌入式數(shù)據(jù)庫中修復(fù)該問題,所以SQLite需要小心的確保查詢規(guī)劃在部署之后不會被意外的改變。
SQLite穩(wěn)定性保證適用于傳統(tǒng)的查詢規(guī)劃和NGQP。
需要注意的很重要的一點(diǎn)是SQLite版本的改變可能引起查詢規(guī)劃的改變。同版本的SQLite通常會選擇相同的查詢規(guī)劃,但是如果你把你的應(yīng)用重新連接到了不同版本的SQLite上,那么查詢規(guī)劃可能會改變。在很罕見的情況下,SQLite版本的改變會引起性能衰減。這是一個(gè)你應(yīng)該考慮把你的應(yīng)用靜態(tài)的連接到SQLite而不是使用一個(gè)系統(tǒng)范圍(system-wide)的SQLite共享庫的原因,因?yàn)樗锌赡茉谀悴恢榛蛘卟荒芸刂频那闆r下改變。
3.0 一個(gè)棘手的情況
"TPC-H Q8"是一個(gè)來自于Transaction Processing Performance Council的測試查詢。查詢規(guī)劃器在3.7.17以及之前版本的SQLite中沒有為TPC-H Q8選擇一個(gè)好的規(guī)劃。并且被認(rèn)定再怎么調(diào)整傳統(tǒng)查詢規(guī)劃器也不能修復(fù)這個(gè)問題。為了給TPC-H Q8查詢尋找一個(gè)好的好的解決方案,并且能夠持續(xù)的改進(jìn)SQLite查詢規(guī)劃器的質(zhì)量,我們有必要重新設(shè)計(jì)查詢規(guī)劃器。這個(gè)部分將解釋為什么重新設(shè)計(jì)是有必要的,NGQP有什么不同和設(shè)法解決TPC-H Q8問題。
3.1 查詢細(xì)節(jié)
TPC-H Q8 是一個(gè)8路的join。基于以上所看到的,查詢規(guī)劃器的主要任務(wù)是確定這八次循環(huán)最好的嵌套順序,從而將完成join操作的工作量最小化。下圖就是TPC-H Q8例子的簡單模型:
劃器")
在這個(gè)圖表中,在查詢語句中的from從句部分的8個(gè)表都被表示成一個(gè)大的圓形,并用from從句的名字標(biāo)識:N2, S, L, P, O, C, N1 和R。圖中的弧線代表計(jì)算圓弧起點(diǎn)的表格做外連接所對應(yīng)的預(yù)估開銷。舉個(gè)例子,S內(nèi)連接L的開銷是2.30,S外連接L的開銷是9.17。
這兒的“資源消耗”是通過對數(shù)運(yùn)算算出來的。由于循環(huán)是嵌套的,因此總的資源消耗是相乘得到的,而不是相加。通常都認(rèn)為圖帶的是要累加的權(quán)重,然而這兒的圖顯示的是各種資源消耗求對數(shù)后的值。上圖顯示S位于L內(nèi)部要少消耗大約6.87,轉(zhuǎn)換后就是S循環(huán)位于L循環(huán)內(nèi)部的查詢比S循環(huán)位于L循環(huán)外部的查詢要運(yùn)行快大約963倍。
從標(biāo)記為“*”的小圓圈開始的箭頭表示單獨(dú)運(yùn)行每個(gè)循環(huán)所消耗的資源。外循環(huán)一定消耗的是“*”所消耗資源。內(nèi)循環(huán)可以選擇消耗"*"所消耗的資源,或者選擇其余項(xiàng)中的一個(gè)為外部循環(huán)所消耗的資源,無論選擇哪個(gè)都是為了得到最低的資源消耗。你可以把“*”所消耗的資源看作是圖中其他節(jié)點(diǎn)中的任意一個(gè)到當(dāng)前節(jié)點(diǎn)的多個(gè)弧線的簡寫表示。因此說這樣的圖是“完整的”,也就是說圖中的每一對節(jié)點(diǎn)間都有兩個(gè)方向的弧線(一些是非常明顯的,一些則是隱含的)。
尋找最佳查詢規(guī)劃的問題就等同于尋找圖中訪問每個(gè)節(jié)點(diǎn)僅僅一次的最小消耗路徑。
(附注:TPC-H Q8圖里的資源消耗的評估是由SQLite 3.7.16里的 查詢規(guī)劃器計(jì)算,并使用自然對數(shù)轉(zhuǎn)換得來的 。)
3.2 復(fù)雜性
上面所展示的查詢規(guī)劃器問題是簡化版的。資源的消耗可以估計(jì)出來。我們只有實(shí)際運(yùn)行了循環(huán)之后才能知道運(yùn)行這個(gè)循環(huán)真正的資源消耗是多少 。SQLite是根據(jù)WHERE子句的約束和可以使用的索引來估計(jì)運(yùn)行循環(huán)的資源消耗的。這樣的估計(jì)通常都八九不離十,不過有時(shí)候估計(jì)的結(jié)果卻脫離現(xiàn)實(shí)。使用ANALYZE命令收集數(shù)據(jù)庫的其他統(tǒng)計(jì)信息有時(shí)候可以讓SQLite對消耗的資源的評估更準(zhǔn)確。
消耗的資源是由多個(gè)數(shù)字組成的,而不是像上圖一樣只是有一個(gè)單獨(dú)的數(shù)字組成。SQLite針對每個(gè)循環(huán)的不同階段計(jì)算出幾個(gè)不同的評估的消耗的資源。例如 ,“初始化”資源耗費(fèi)僅僅發(fā)生在查詢啟動(dòng)的哪個(gè)時(shí)候。初始化消耗的資源是對沒有索引的表進(jìn)行自動(dòng)索引所消耗的資源 。接著是運(yùn)行循環(huán)的每一步所消耗的資源。最后評估循環(huán)自動(dòng)生成的行數(shù),行數(shù)是評估內(nèi)循環(huán)所消耗資源所必需的信息。如果查詢含有ORDER BY子句,那么排序所消耗的資源也要考慮。
常用的查詢里的依賴并不一定在一個(gè)單獨(dú)的循環(huán)上,因此依賴的模型可能無法用圖來表示。例如,WHERE子句的約束之一可能是S.a=L.b+P.c,這就隱含地說S循環(huán)一定是L和P的內(nèi)循環(huán)。這樣的依賴不可能用圖來表示 ,因?yàn)闆]有辦法繪出同時(shí)從兩個(gè)或者兩個(gè)以上節(jié)點(diǎn)出發(fā)的一條弧線。
如果查詢包含有ORDER BY子句或者GROUP BY子句,或者查詢使用了DISTINCT關(guān)鍵字,那么就會自動(dòng)對行進(jìn)行排序,形成一個(gè)圖,選擇遍歷這個(gè)圖的路徑就顯得尤為便利,因此也不需要單獨(dú)進(jìn)行排序了。自動(dòng)刪除ORDER BY子句可以讓性能有巨大的變化,因此要完成規(guī)劃器的完整實(shí)現(xiàn),這也是一個(gè)需要考慮的因素。
在TPC-H Q8查詢里,所有的初始化資源消耗是微不足道的,各個(gè)節(jié)點(diǎn)之前都存在依賴,而且沒有ORDER BY,GROUP BY或者DISTINCT子句。因此,對TPC-H Q8來說,上圖足以表示計(jì)算資源消耗所需的東西。通常的查詢可能涉及到許多其他復(fù)雜的情形,為了能夠清晰的說明問題,這篇文章的后續(xù)部分就忽略了使問題復(fù)雜化的許多因素。
3.3 尋找最佳查詢規(guī)劃
在版本3.8.0之前,SQLite一直使用“最近鄰居” 或者“NN"試探法尋找最佳查詢規(guī)劃。NN試探法對圖進(jìn)行一次單獨(dú)的遍歷,總是選擇消耗最低的哪個(gè)弧線作為下一步。大多數(shù)情況下,NN試探法運(yùn)行的非常地好。而且,NN試探法也很快,因此SQLite即便是達(dá)到64個(gè)連接的情況下也能夠快速的找到很好的規(guī)劃。與此相反,可以運(yùn)行更大量搜索的其他數(shù)據(jù)庫引擎在同一連接中表的數(shù)目大于10或者15時(shí)就會停止不動(dòng)。
很不幸,NN試探法對TPC-H Q8所計(jì)算出的查詢規(guī)劃不是最佳的。由NN試探法計(jì)算出的規(guī)劃是R-N1-N2-S-C-O-L-P,其資源消耗是36.92。前一句的意思是: R表運(yùn)行在最外層循環(huán),N1是位于緊接著的內(nèi)部循環(huán),N2是位于第三個(gè)循環(huán),以此類推到P,它位于最內(nèi)層的循環(huán)。遍歷此圖的(由窮舉搜索可得到的)最短路徑是P-L-O-C-N1-R-S-N2,此時(shí)的資源耗費(fèi)是27.38。差異看起來似乎并不大,不過,要記得消耗的資源是經(jīng)過對數(shù)運(yùn)算計(jì)算出來的,因此最短路徑比由NN試探法得出的路徑快幾乎750倍。
這個(gè)問題的一個(gè)解決方法就是更改SQLite,讓它使用窮舉搜索獲取最佳路徑。然而,窮舉搜索所需要的時(shí)間與K成正比!(K是連接涉及的表數(shù)目),因此當(dāng)有10個(gè)以上的連接的時(shí)候,運(yùn)行sqlite3_prepare()所耗費(fèi)的時(shí)間丟非常大。
3.4 N個(gè)最近鄰居試探法或者"N3"試探法
下一代查詢規(guī)劃器使用新的試探法查找遍歷圖的最佳路徑:"N個(gè)最近鄰居試探法"(后面就叫"N3")。用N3的話,每一步就不是僅僅選擇一個(gè)最近鄰居,N3算法在每一步要跟蹤N個(gè)最佳路徑,這兒N是個(gè)小整數(shù)。
假設(shè)N=4,那么對TPC-H Q8圖來說 ,第一步找到可訪問任何單個(gè)節(jié)點(diǎn)的四個(gè)最短路徑:
R (cost: 3.56)
N1 (cost: 5.52)
N2 (cost: 5.52)
P (cost: 7.71)
第二步找到以前一步找到的四個(gè)最短路徑之一開始的可訪問兩個(gè)節(jié)點(diǎn)的四個(gè)最短路徑。這種情況下,兩個(gè)或者兩個(gè)以上的路徑是可以的(這樣的路徑具有相同的可訪問的節(jié)點(diǎn)集,可能順序不同),只要記住是必須保持第一步的路徑和最低資源消耗路徑就可以。我們找到以下路徑:
R-N1 (cost: 7.03)
R-N2 (cost: 9.08)
N2-N1 (cost: 11.04)
R-P {cost: 11.27}
第三步以可訪問兩個(gè)節(jié)點(diǎn)四個(gè)最短路徑為起點(diǎn),找到可訪問三個(gè)節(jié)點(diǎn)的四個(gè)最短路徑:
R-N1-N2 (cost: 12.55)
R-N1-C (cost: 13.43)
R-N1-P (cost: 14.74)
R-N2-S (cost: 15.08)
以此類推。TPC-H Q8查詢有8個(gè)節(jié)點(diǎn),因此如此的過程總共重復(fù)8次。在通常K個(gè)連接的情況下,存儲需求復(fù)雜度是O(N),計(jì)算的時(shí)間復(fù)雜度是O(K*N),它明顯比O(2 K)方案快多了。
然而,N選擇哪個(gè)值呢?你可以試試N=K,此時(shí)這種算法的復(fù)雜度是O(K2) ,實(shí)際上仍然非常相當(dāng)快,由于K的最大值為64,而且K很少超過10。不過這仍然不足以解決TPC-H Q8問題。如果TPC-H Q8查詢進(jìn)行時(shí)N=8,此時(shí)N3算法得到的查詢規(guī)劃是R-N1-C-O-L-S-N2-P,此時(shí)資源耗費(fèi)是29.78。這對NN算法進(jìn)行了很大的改進(jìn),不過仍然不是最佳的。當(dāng)N=10或者更大時(shí),N3才能找到TPC-H Q8查詢的最佳查詢規(guī)劃。
下一代查詢規(guī)劃的最初實(shí)現(xiàn)對簡單查詢選N=1,兩個(gè)連接就選N=5,三個(gè)或者更多表連接選擇N=10。后續(xù)的發(fā)布版可能要更改N值得選擇規(guī)則。
4.0 升級到下一代查詢規(guī)劃器的風(fēng)險(xiǎn)
對大多數(shù)應(yīng)用來說,從舊查詢規(guī)劃器升級到下一代查詢規(guī)劃器不需要多想,或者不需要花很多功夫就可以做到。只要簡單地把舊的SQLite版本換成較新的SQLite版本,然后重新編譯就行,此時(shí)運(yùn)行應(yīng)用就會快很多。不需要對復(fù)雜過程的API進(jìn)行更改或者修正。
然而,像其他查詢器更換一樣,升級到下一代查詢規(guī)劃器確實(shí)可以引起性能下降這樣的小風(fēng)險(xiǎn)。出現(xiàn)這種問題不是因?yàn)橄乱淮樵円?guī)劃器不正確、或者說漏洞多,或者說比舊的查詢規(guī)劃器差。假若選擇索引的信息確定,那么下一代查詢規(guī)劃器總能選擇一個(gè)比以前好的或者說更優(yōu)秀的規(guī)劃。存在的問題是某些應(yīng)用也許使用了低質(zhì)量的、沒有多少選擇性的索引,而且無法運(yùn)行ANALYZE。舊的查詢規(guī)劃器對每個(gè)查詢都查看了許多但比現(xiàn)在要少的可能的查詢實(shí)現(xiàn),因此如果運(yùn)氣好的話,這樣的規(guī)劃器可能就碰到好的規(guī)劃。而另一方面,下一代查詢規(guī)劃器查看了更多地查詢規(guī)劃實(shí)現(xiàn),所以理論上來講,它可能選擇另一個(gè)性能更好的查詢規(guī)劃,如果此時(shí)索引運(yùn)行良好,而實(shí)際運(yùn)行中性能卻有所下降,那么可能是數(shù)據(jù)的分布引起的.
技術(shù)要點(diǎn):
只要下一代查詢規(guī)劃器可以訪問SQLITE STAT1文件里準(zhǔn)確的ANALYZE數(shù)據(jù),那么它總是能找到與以前查詢規(guī)劃器等同的或者性能更好的查詢規(guī)劃。
只要查詢模式不包含最左邊字段具有相同值且有超過10或者20行的索引,那么下一代查詢規(guī)劃器總是能找到一個(gè)好的查詢規(guī)劃。
并不是所有的應(yīng)用都滿足上面條件。幸運(yùn)的是,即便不滿足這些條件,下一代查詢規(guī)劃器通常仍然能找到好的查詢規(guī)劃。不過,性能下降這種情況也有可能出現(xiàn)(不過很少)。
4.1范例分析:升級Fossil使用下一代查詢規(guī)器
Fossil DVCS是用來追蹤全部SQLite源代碼的版本控制系統(tǒng)。Fossil軟件倉庫就是一個(gè)SQLite數(shù)據(jù)庫文件。(作為單獨(dú)的練習(xí),我們邀請讀者對這種遞歸式的應(yīng)用查詢規(guī)劃器進(jìn)行深入思考。)Fossil既是SQLite的版本控制系統(tǒng),也是SQLite的測試平臺。無論什么時(shí)候?qū)QLite進(jìn)行強(qiáng)化,F(xiàn)ossil都是對這些強(qiáng)化進(jìn)行測試和評估的首批應(yīng)用之一。所以Fossil最早采用下一代查詢規(guī)劃器。
很不幸,下一代查詢規(guī)劃器引起了Fossil性能下降。
Fossil用到許多報(bào)表,其中之一就是單個(gè)分支上所做更改的時(shí)間表,它顯示了這個(gè)分支的所有合并和刪除。查看 http://www.sqlite.org/src/timeline?nd&n=200&r=trunk就可以看到時(shí)間報(bào)表的典型例子。通常生成這樣的報(bào)表只需要幾毫秒。然而,升級到下一代查詢規(guī)劃器之后,我們發(fā)現(xiàn)對倉庫的主干分支生成這樣的報(bào)表竟然需要近10秒的時(shí)間。
用來生成分支時(shí)間表的核心查詢?nèi)缦隆?我們不期望讀者理解這個(gè)查詢的細(xì)節(jié)。下面將給出說明。)
- SELECT
- blob.rid AS blobRid,
- uuid AS uuid,
- datetime(event.mtime,'localtime') AS timestamp,
- coalesce(ecomment, comment) AS comment,
- coalesce(euser, user) AS user,
- blob.rid IN leaf AS leaf,
- bgcolor AS bgColor,
- event.type AS eventType,
- (SELECT group_concat(substr(tagname,5), ', ')
- FROM tag, tagxref
- WHERE tagname GLOB 'sym-*'
- AND tag.tagid=tagxref.tagid
- AND tagxref.rid=blob.rid
- AND tagxref.tagtype>0) AS tags,
- tagid AS tagid,
- brief AS brief,
- event.mtime AS mtime
- FROM event CROSS JOIN blob
- WHERE blob.rid=event.objid
- AND (EXISTS(SELECT 1 FROM tagxref
- WHERE tagid=11 AND tagtype>0 AND rid=blob.rid)
- OR EXISTS(SELECT 1 FROM plink JOIN tagxref ON rid=cid
- WHERE tagid=11 AND tagtype>0 AND pid=blob.rid)
- OR EXISTS(SELECT 1 FROM plink JOIN tagxref ON rid=pid
- WHERE tagid=11 AND tagtype>0 AND cid=blob.rid))
- ORDER BY event.mtime DESC
- LIMIT 200;
這個(gè)查詢不是特別復(fù)雜,不過,即便這樣,它仍然可以替代上百行,也許是上千行處理過程代碼。這個(gè)查詢的要點(diǎn)是:向下掃描EVENT表,查找滿足下列三個(gè)條件中任何一個(gè)的最新的200條提交記錄:
此提交含有"trunk"標(biāo)簽。
此提交有個(gè)子提交含有“trunk"標(biāo)簽。
此提交有個(gè)父提交含有“trunk"標(biāo)簽。
第一個(gè)條件將顯示所有主干分支上的提交,第二個(gè)和第三個(gè)條件包含合并到主干分支,或者由主干分支產(chǎn)生的提交。這三個(gè)條件是通過在此查詢的WHERE子句中用OR連接三個(gè)EXISTS語句實(shí)現(xiàn)的。使用下一代查詢規(guī)劃器引起的性能下降是由第二個(gè)和第三個(gè)條件產(chǎn)生的。兩個(gè)條件里存在的問題是相同的,因此我們只看第二個(gè)條件。第二個(gè)條件的子查詢可以重寫為如下語句(把次要的和不重要的進(jìn)行了簡化):
- SELECT 1
- FROM plink JOIN tagxref ON tagxref.rid=plink.cid
- WHERE tagxref.tagid=$trunk
- AND plink.pid=$ckid;
PLINK表保存著各個(gè)提交之間的父子關(guān)系。TAGXREF表把標(biāo)簽映射到提交上。作為參考,對這兩個(gè)表進(jìn)行查詢的模式的相關(guān)部分顯示如下:
- CREATE TABLE plink(
- pid INTEGER REFERENCES blob,
- cid INTEGER REFERENCES blob
- );
- CREATE UNIQUE INDEX plink_i1 ON plink(pid,cid);
- CREATE TABLE tagxref(
- tagid INTEGER REFERENCES tag,
- mtime TIMESTAMP,
- rid INTEGER REFERENCE blob,
- UNIQUE(rid, tagid)
- );
- CREATE INDEX tagxref_i1 ON tagxref(tagid, mtime);
實(shí)現(xiàn)這樣的查詢只有兩個(gè)方法值得考慮。(當(dāng)然可能還有許多其他算法,不過它們中的任何一個(gè)都不是“最佳”算法的競爭者。
查找提交$ckid的所有子提交,然后對每一個(gè)進(jìn)行測試,看看是否有子提交包含$trunk標(biāo)簽
查找所有包含$trunk標(biāo)簽的提交,然后對每個(gè)這樣的提交進(jìn)行測試,看看是否有$ckid提交的子提交。
僅憑直覺,我們?nèi)祟愓J(rèn)為第一個(gè)算法是最佳選擇。每個(gè)提交可能有幾個(gè)子提交(其中有一個(gè)提交是我們最常用到的。),然后對每個(gè)子提交進(jìn)行測試,用對數(shù)運(yùn)算計(jì)算出查找到$trunk標(biāo)簽的時(shí)間。實(shí)際上,算法1確實(shí)較快。然而下一代查詢規(guī)劃器卻沒有使用人們直覺上的最佳選擇。下一代查詢規(guī)劃器一定是選擇了很難得算法,算法2在數(shù)學(xué)上相對稍微難些。這是因?yàn)椋涸跊]有其他信息的情況下下一代查詢規(guī)劃器一定假設(shè)PLINK_I1和TAGXREF_I1索引具有同等的質(zhì)量和同等的可選擇性。算法2使用了TAGXREF_I1索引的一個(gè)字段,PLINK_I1索引的兩個(gè)字段,而算法1只是使用了這兩個(gè)索引的第一個(gè)字段。正是由于算法2使用了多個(gè)字段的索引,所以下一代查詢規(guī)劃器才會以自己的標(biāo)準(zhǔn)正確地確定它作為兩種算法中性能較好的算法。兩個(gè)算法所花費(fèi)的時(shí)間非常接近,算法2 只是勉強(qiáng)稍稍領(lǐng)先算法1。不過,這種情況下,選擇算法2確實(shí)是正確的。
很不幸,在實(shí)際的應(yīng)用中算法2比算法1要慢些。
出現(xiàn)這樣的問題是因?yàn)樗饕⒉皇蔷哂型荣|(zhì)量。一個(gè)提交有可能只有一個(gè)子提交。這樣PLINK_I1索引的第一個(gè)字段通常縮減值對一行進(jìn)行搜索。不過由于成千上萬的提交都包含有"trunk"標(biāo)簽,所以TAGXREF_I1的第一個(gè)字段對縮減搜索不會有多大幫助。
下一代查詢規(guī)劃器是沒有辦法知道TAGXREF_I1在這樣的查詢中幾乎沒有什么用處,除非在數(shù)據(jù)庫上運(yùn)行ANALYZE。ANALYZE命令 收集了各個(gè)索引的質(zhì)量統(tǒng)計(jì)信息,并把 這些統(tǒng)計(jì)信息存儲到SQLITE_STAT1表里。如果下一代查詢規(guī)劃器能夠訪問這些統(tǒng)計(jì)信息 ,那么在很大程度上它就會非常容易地選擇算法1作為最佳算法。
難道舊查詢規(guī)劃器沒有選擇算法2?很簡單:因?yàn)镹N算法甚至從來都沒有考慮到算法2。這類規(guī)劃問題的圖示如下:
劃器")
在如左圖那樣“沒有運(yùn)行ANALYZE“的情況下,NN算法選擇循環(huán)P9PLINK)作為外循環(huán),因?yàn)?.9比5.2要小,結(jié)果就是選擇P-T路徑,即算法1。NN算法只是在每一步查找一個(gè)最佳選擇路徑,因此它完全忽略了這樣一個(gè)事實(shí):5.2+4.4是比4.9+4.8性能稍稍有些好的規(guī)劃。然而N3算法對著兩個(gè)連接追蹤了5個(gè)最佳路徑,因此它最終選擇了T-P路徑,因?yàn)檫@條路徑的總體資源消耗要少一些。路徑T-P就是算法2。
注意: 如果運(yùn)行了ANALYZE,那么對資源消耗的評估就更加接近于現(xiàn)實(shí),這樣NN和N3都選擇算法1。
(附注:最新的兩圖中對資源消耗的評估是下一代查詢規(guī)劃器使用以2為底的對數(shù)算法計(jì)算得出來的,而且與舊查詢規(guī)劃器相比假設(shè)的資源消耗稍微有些不同。因此,最后兩個(gè)圖中的資源消耗評估不能與TPC-H Q8圖里的資源消耗評估進(jìn)行比較。)
4.2 問題修正
對資源倉庫數(shù)據(jù)庫運(yùn)行ANALYZE可立即修復(fù)這類性能問題。然而,無論是否對資源倉庫是否進(jìn)行分析,我們都要求Fossil十分強(qiáng)壯,而且總是能夠快速地運(yùn)行。基于這個(gè)原因,我們修改查詢使用CROSS JOIN操作符而不使用常用的JOIN操作符。SQLite將不會對CROSS JOIN連接的表重新排序。這個(gè)功能是SQLite中長期都有的一個(gè)功能,做這么特別的設(shè)計(jì)就是允許具有豐富經(jīng)驗(yàn)的開發(fā)人員能夠強(qiáng)制SQLite執(zhí)行特定的嵌套循環(huán)順序。一旦某個(gè)連接更改為(增加了一個(gè)關(guān)鍵字的)CROSS JOIN這樣的連接,下一代查詢規(guī)劃器就不管是否使用ANALYZE收集統(tǒng)計(jì)統(tǒng)計(jì)信息都強(qiáng)制選擇稍稍快一點(diǎn)的算法1。
我們說算法1"快一些“,不過,嚴(yán)格來說這么說不準(zhǔn)確。對一個(gè)常見的存儲倉庫運(yùn)行算法1是快一些,不過,可能構(gòu)建這樣一種資源倉庫:對資源倉庫的每一次提交都是提交給不同的名字唯一的分支上,而且所有的提交都是根提交的子提交。這種情況下,TAGXREF_I1與PLINK_I1相比就具有更多的可選項(xiàng)了,此時(shí)算法2才真正快一些。然而實(shí)際中這樣的資源倉庫極不可能出現(xiàn),所以使用CROSS JOIN語法硬編碼嵌套循環(huán)的順序是解決這種情形下存在問題的適合方案。
5.0 避免或者修正查詢規(guī)劃器問題的方法一覽表
不要驚慌!查詢規(guī)劃器選擇差的規(guī)劃這種情況實(shí)際上是非常罕見的。你未必會在應(yīng)用中碰到這樣的問題。如果你沒有性能方面問題,那么你就不必為此而擔(dān)心。
創(chuàng)建正確的索引。大多數(shù)SQL性能問題不是因?yàn)椴樵円?guī)劃器問題而引起的,而是因?yàn)槿鄙俸线m的索引。確保索引可以促進(jìn)所有大型的查詢。大多數(shù)性能問題都可以使用一個(gè)或者兩個(gè)CREATE INDEX命令來解決,而不需要對應(yīng)用代碼進(jìn)行修改。
避免創(chuàng)建低質(zhì)量的索引。(用于解決查詢規(guī)劃器問題而創(chuàng)建的)低質(zhì)量索引是這樣的索引:表里的索引最左一個(gè)字段具有相同值的行超過10行或者20行。特別注意,避免使用布爾字段或或者“枚舉類型”字段作為索引的最左一字段。
這篇文章的前一段所說的Fossil性能問題是因?yàn)門AGXREF表的TAGXREF_I1索引的最左一子段(TAGID字段)具有相同值得項(xiàng)超過1萬。
如果你一定要使用低質(zhì)量的索引,那么請一定要運(yùn)行ANALYZE。只要查詢規(guī)劃器知道那個(gè)索引時(shí)低質(zhì)量的,那么低質(zhì)量的索引就不會讓它迷惑。查詢規(guī)劃器知曉低質(zhì)量索引的方法是通過SQLITE_STAT1表的內(nèi)容來實(shí)現(xiàn)的,這個(gè)表示有ANALYZE命令計(jì)算得來的。
當(dāng)然,ANALYZE只有在數(shù)據(jù)庫一開始就擁有非常大量的內(nèi)容的情況下才能夠高效地運(yùn)行。當(dāng)你希望創(chuàng)建一個(gè)數(shù)據(jù)庫并累積了大量數(shù)據(jù)的時(shí)候,你可以運(yùn)行命令"ANALYZE sqlite_master"創(chuàng)建SQLITE_STAT1表,然后(使用常用的INSERT語句)向SQLITE_STAT1表中填入用來說明這樣的數(shù)據(jù)庫正適合你的應(yīng)用的內(nèi)容-也許這樣的內(nèi)容是你在對實(shí)驗(yàn)室的某個(gè)填寫的非常完美的模板數(shù)據(jù)庫運(yùn)行ANALYZE命令后所獲得的。
編寫你自己的代碼。增加可以讓你快速且非常容易就能知道哪些查詢需要很多時(shí)間,這樣就只運(yùn)行哪些特別不需要花太長時(shí)間的查詢。
如果查詢可能使用沒有運(yùn)行分析的數(shù)據(jù)庫上的低質(zhì)量索引,那么請使用CROSS JOIN語法,強(qiáng)制使用特定的嵌套循環(huán)順序。SQLite對CROSS JOIN操作符進(jìn)行特殊的處理,它強(qiáng)制左表為右表的外部循環(huán)。
如果有其他方法實(shí)現(xiàn),那么就避免這么做,因?yàn)樗c任何一個(gè)SQL語言理念里的強(qiáng)大的優(yōu)點(diǎn)相抵觸,特別是應(yīng)用開發(fā)人不需要了解查詢規(guī)劃。如果你使用了CROSS JOIN,那么直到開發(fā)周期的后期你也要這么做,而且要在注釋里仔細(xì)地說明CROSS JOIN是如何使用的,這樣以后才有可能把它去掉。在開發(fā)周期的早期就避免使用CROSS JOIN,因?yàn)檫@么做是不成熟的優(yōu)化措施,也就是眾所周知的萬惡之源。
使用單目運(yùn)算符"+",取消WHERE子句某些限制條件。當(dāng)對某個(gè)具體的查詢有更高質(zhì)量的索引可以使用的時(shí)候,如果查詢規(guī)劃器仍然堅(jiān)持選擇差質(zhì)量的索引,那么請?jiān)赪HERE子句中謹(jǐn)慎地使用單目運(yùn)算符"+",這樣做就可以強(qiáng)制查詢規(guī)劃器不使用差質(zhì)量的索引。如果可能的話,就盡量小心地添加這個(gè)這個(gè)運(yùn)算符,而且尤其避免在應(yīng)用開發(fā)的周期的早期就使用。特別要注意:給一個(gè)與類型密切相關(guān)的等號表達(dá)式增加單目運(yùn)算符"+"可能更改這個(gè)表達(dá)式的結(jié)果。
使用INDEXED BY語法,強(qiáng)制有問題的查詢選擇特定的索引。同前兩個(gè)標(biāo)題一樣,如果可能的話,盡量避免使用這個(gè)方法,尤其避免在開發(fā)的早期這么做,因?yàn)楹芮宄且粋€(gè)不成熟的優(yōu)化措施。
6.0 結(jié)論
SQLite的查詢規(guī)劃器做這樣的工作做得非常好:為正在運(yùn)行的SQL語句選擇快速算法。對舊查詢規(guī)劃器來說,這是事實(shí),對新的下一代查詢規(guī)劃器來說更是這樣。也許偶然會出現(xiàn)這樣的情況:由于信息不完整,查詢規(guī)劃器選擇了稍差的查詢規(guī)劃。 與使用舊查詢規(guī)劃器相比,使用下一代查詢規(guī)劃器這種情形就會更少出現(xiàn)了,不過仍然有可能出現(xiàn)。即便出現(xiàn)了這種極少出現(xiàn)的情況,應(yīng)用開發(fā)人員需要做的是了解和幫助查詢規(guī)劃器做正確的事情。通常情況下,下一代查詢規(guī)劃器只是對SQLite做了一個(gè)新的增強(qiáng),這種增強(qiáng)可以讓應(yīng)用運(yùn)行的更快些,而且不需要開發(fā)人員做更多的思考或者動(dòng)作。
新聞熱點(diǎn)





疑難解答
圖片精選