先看要解析的樣例SQL語句:
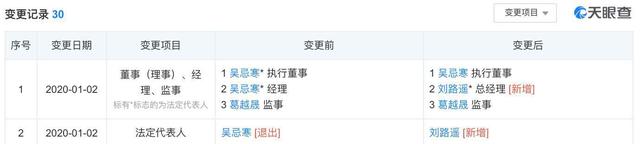
select * from dual
SELECT * frOm dual
Select C1,c2 From tb
select c1,c2 from tb
select count(*) from t1
select c1,c2,c3 from t1 where condi1=1
Select c1,c2,c3 From t1 Where condi1=1
select c1,c2,c3 from t1,t2 where condi3=3 or condi4=5 order by o1,o2
Select c1,c2,c3 from t1,t2 Where condi3=3 or condi4=5 Order by o1,o2
select c1,c2,c3 from t1,t2,t3 where condi1=5 and condi6=6 or condi7=7 group by g1,g2
Select c1,c2,c3 From t1,t2,t3 Where condi1=5 and condi6=6 or condi7=7 Group by g1,g2
Select c1,c2,c3 From t1,t2,t3 Where condi1=5 and condi6=6 or condi7=7 Group by g1,g2,g3 order by g2,g3
解析效果之一(isSingleLine=false):
原SQL為select * from dual
解析后的SQL為
select
*
from
dual
原SQL為SELECT * frOm dual
解析后的SQL為
select
*
from
dual
原SQL為Select C1,c2 From tb
解析后的SQL為
select
C1,c2
from
tb
原SQL為select c1,c2 from tb
解析后的SQL為
select
c1,c2
from
tb
原SQL為select count(*) from t1
解析后的SQL為
select
count(*)
from
t1
原SQL為select c1,c2,c3 from t1 where condi1=1
解析后的SQL為
select
c1,c2,c3
from
t1
where
condi1=1
原SQL為Select c1,c2,c3 From t1 Where condi1=1
解析后的SQL為
select
c1,c2,c3
from
t1
where
condi1=1
原SQL為select c1,c2,c3 from t1,t2 where condi3=3 or condi4=5 order by o1,o2
解析后的SQL為
select
c1,c2,c3
from
t1,t2
where
condi3=3 or condi4=5
order by
o1,o2
原SQL為Select c1,c2,c3 from t1,t2 Where condi3=3 or condi4=5 Order by o1,o2
解析后的SQL為
select
c1,c2,c3
from
t1,t2
where
condi3=3 or condi4=5
order by
o1,o2
原SQL為select c1,c2,c3 from t1,t2,t3 where condi1=5 and condi6=6 or condi7=7 group by g1,g2
解析后的SQL為
select
c1,c2,c3
from
t1,t2,t3
where
condi1=5 and condi6=6 or condi7=7
group by
g1,g2
原SQL為Select c1,c2,c3 From t1,t2,t3 Where condi1=5 and condi6=6 or condi7=7 Group by g1,g2
解析后的SQL為
select
c1,c2,c3
from
t1,t2,t3
where
condi1=5 and condi6=6 or condi7=7
group by
g1,g2
原SQL為Select c1,c2,c3 From t1,t2,t3 Where condi1=5 and condi6=6 or condi7=7 Group by g1,g2,g3 order by g2,g3
解析后的SQL為
select
c1,c2,c3
from
t1,t2,t3
where
condi1=5 and condi6=6 or condi7=7
group by
g1,g2,g3
order by
g2,g3
解析效果之二(isSingleLine=true):
原SQL為select * from dual
解析后的SQL為
select
*
from
dual
原SQL為SELECT * frOm dual
解析后的SQL為
select
*
from
dual
原SQL為Select C1,c2 From tb
解析后的SQL為
select
C1,
c2
from
tb
原SQL為select c1,c2 from tb
解析后的SQL為
select
c1,
c2
from
tb
原SQL為select count(*) from t1
解析后的SQL為
select
count(*)
from
t1
原SQL為select c1,c2,c3 from t1 where condi1=1
解析后的SQL為
select
c1,
c2,
c3
from
t1
where
condi1=1
原SQL為Select c1,c2,c3 From t1 Where condi1=1
解析后的SQL為
select
c1,
c2,
c3
from
t1
where
condi1=1
原SQL為select c1,c2,c3 from t1,t2 where condi3=3 or condi4=5 order by o1,o2
解析后的SQL為
select
c1,
c2,
c3
from
t1,
t2
where
condi3=3 or
condi4=5
order by
o1,
o2
原SQL為Select c1,c2,c3 from t1,t2 Where condi3=3 or condi4=5 Order by o1,o2
解析后的SQL為
select
c1,
c2,
c3
from
t1,
t2
where
condi3=3 or
condi4=5
order by
o1,
o2
原SQL為select c1,c2,c3 from t1,t2,t3 where condi1=5 and condi6=6 or condi7=7 group by g1,g2
解析后的SQL為
select
c1,
c2,
c3
from
t1,
t2,
t3
where
condi1=5 and
condi6=6 or
condi7=7
group by
g1,
g2
原SQL為Select c1,c2,c3 From t1,t2,t3 Where condi1=5 and condi6=6 or condi7=7 Group by g1,g2
解析后的SQL為
select
c1,
c2,
c3
from
t1,
t2,
t3
where
condi1=5 and
condi6=6 or
condi7=7
group by
g1,
g2
原SQL為Select c1,c2,c3 From t1,t2,t3 Where condi1=5 and condi6=6 or condi7=7 Group by g1,g2,g3 order by g2,g3
解析后的SQL為
select
c1,
c2,
c3
from
t1,
t2,
t3
where
condi1=5 and
condi6=6 or
condi7=7
group by
g1,
g2,
g3
order by
g2,
g3
使用的類SqlParser�����,你可以拷貝下來使用之:
package com.sitinspring.common.sqlFormatter;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* SQL語句解析器類
* @author: sitinspring(junglesong@gmail.com)
* @date: 2008-3-12
*/
public class SqlParser{
/**
* 逗號(hào)
*/
private static final String Comma = ",";
/**
* 四個(gè)空格
*/
private static final String FourSpace = " ";
/**
* 是否單行顯示字段����,表,條件的標(biāo)識(shí)量
*/
private static boolean isSingleLine=true;
/**
* 待解析的SQL語句
*/
private String sql;
/**
* SQL中選擇的列
*/
private String cols;
/**
* SQL中查找的表
*/
private String tables;
/**
* 查找條件
*/
private String conditions;
/**
* Group By的字段
*/
private String groupCols;
/**
* Order by的字段
*/
private String orderCols;
/**
* 構(gòu)造函數(shù)
* 功能:傳入構(gòu)造函數(shù)���,解析成字段,表����,條件等
* @param sql:傳入的SQL語句
*/
public SqlParser(String sql){
this.sql=sql.trim();
parseCols();
parseTables();
parseConditions();
parseGroupCols();
parseOrderCols();
}
/**
* 解析選擇的列
*
*/
private void parseCols(){
String regex="(select)(.+)(from)";
cols=getMatchedString(regex,sql);
}
/**
* 解析選擇的表
*
*/
private void parseTables(){
String regex="";
if(isContains(sql,"http://s+where//s+")){
regex="(from)(.+)(where)";
}
else{
regex="(from)(.+)($)";
}
tables=getMatchedString(regex,sql);
}
/**
* 解析查找條件
*
*/
private void parseConditions(){
String regex="";
if(isContains(sql,"http://s+where//s+")){
// 包括Where�,有條件
if(isContains(sql,"group//s+by")){
// 條件在where和group by之間
regex="(where)(.+)(group//s+by)";
}
else if(isContains(sql,"order//s+by")){
// 條件在where和order by之間
regex="(where)(.+)(order//s+by)";
}
else{
// 條件在where到字符串末尾
regex="(where)(.+)($)";
}
}
else{
// 不包括where則條件無從談起����,返回即可
return;
}
conditions=getMatchedString(regex,sql);
}
/**
* 解析GroupBy的字段
*
*/
private void parseGroupCols(){
String regex="";
if(isContains(sql,"group//s+by")){
// 包括GroupBy,有分組字段
if(isContains(sql,"order//s+by")){
// group by 后有order by
regex="(group//s+by)(.+)(order//s+by)";
}
else{
// group by 后無order by
regex="(group//s+by)(.+)($)";
}
}
else{
// 不包括GroupBy則分組字段無從談起����,返回即可
return;
}
groupCols=getMatchedString(regex,sql);
}
/**
* 解析OrderBy的字段
*
*/
private void parseOrderCols(){
String regex="";
if(isContains(sql,"order//s+by")){
// 包括GroupBy,有分組字段
regex="(order//s+by)(.+)($)";
}
else{
// 不包括GroupBy則分組字段無從談起,返回即可
return;
}
orderCols=getMatchedString(regex,sql);
}
/**
* 從文本text中找到regex首次匹配的字符串���,不區(qū)分大小寫
* @param regex: 正則表達(dá)式
* @param text:欲查找的字符串
* @return regex首次匹配的字符串,如未匹配返回空
*/
private static String getMatchedString(String regex,String text){
Pattern pattern=Pattern.compile(regex,Pattern.CASE_INSENSITIVE);
Matcher matcher=pattern.matcher(text);
while(matcher.find()){
return matcher.group(2);
}
return null;
}
/**
* 看word是否在lineText中存在,支持正則表達(dá)式
* @param lineText
* @param word
* @return
*/
private static boolean isContains(String lineText,String word){
Pattern pattern=Pattern.compile(word,Pattern.CASE_INSENSITIVE);
Matcher matcher=pattern.matcher(lineText);
return matcher.find();
}
public String toString(){
// 無法解析則原樣返回
if(cols==null && tables==null && conditions==null && groupCols==null && orderCols==null ){
return sql;
}
StringBuffer sb=new StringBuffer();
sb.append("原SQL為"+sql+"/n");
sb.append("解析后的SQL為/n");
for(String str:getParsedSqlList()){
sb.append(str);
}
sb.append("/n");
return sb.toString();
}
/**
* 在分隔符后加上回車
* @param str
* @param splitStr
* @return
*/
private static String getAddEnterStr(String str,String splitStr){
Pattern p = Pattern.compile(splitStr,Pattern.CASE_INSENSITIVE);
// 用Pattern類的matcher()方法生成一個(gè)Matcher對(duì)象
Matcher m = p.matcher(str);
StringBuffer sb = new StringBuffer();
// 使用find()方法查找第一個(gè)匹配的對(duì)象
boolean result = m.find();
// 使用循環(huán)找出模式匹配的內(nèi)容替換之,再將內(nèi)容加到sb里
while (result) {
m.appendReplacement(sb, m.group(0) + "/n ");
result = m.find();
}
// 最后調(diào)用appendTail()方法將最后一次匹配后的剩余字符串加到sb里��;
m.appendTail(sb);
return FourSpace+sb.toString();
}
/**
* 取得解析的SQL字符串列表
* @return
*/
public List<String> getParsedSqlList(){
List<String> sqlList=new ArrayList<String>();
// 無法解析則原樣返回
if(cols==null && tables==null && conditions==null && groupCols==null && orderCols==null ){
sqlList.add(sql);
return sqlList;
}
if(cols!=null){
sqlList.add("select/n");
if(isSingleLine){
sqlList.add(getAddEnterStr(cols,Comma));
}
else{
sqlList.add(FourSpace+cols);
}
}
if(tables!=null){
sqlList.add(" /nfrom/n");
if(isSingleLine){
sqlList.add(getAddEnterStr(tables,Comma));
}
else{
sqlList.add(FourSpace+tables);
}
}
if(conditions!=null){
sqlList.add(" /nwhere/n");
if(isSingleLine){
sqlList.add(getAddEnterStr(conditions,"(and|or)"));
}
else{
sqlList.add(FourSpace+conditions);
}
}
if(groupCols!=null){
sqlList.add(" /ngroup by/n");
if(isSingleLine){
sqlList.add(getAddEnterStr(groupCols,Comma));
}
else{
sqlList.add(FourSpace+groupCols);
}
}
if(orderCols!=null){
sqlList.add(" /norder by/n");
if(isSingleLine){
sqlList.add(getAddEnterStr(orderCols,Comma));
}
else{
sqlList.add(FourSpace+orderCols);
}
}
return sqlList;
}
/**
* 設(shè)置是否單行顯示表���,字段���,條件等
* @param isSingleLine
*/
public static void setSingleLine(boolean isSingleLine) {
SqlParser.isSingleLine = isSingleLine;
}
/**
* 測(cè)試
* @param args
*/
public static void main(String[] args){
List<String> ls=new ArrayList<String>();
ls.add("select * from dual");
ls.add("SELECT * frOm dual");
ls.add("Select C1,c2 From tb");
ls.add("select c1,c2 from tb");
ls.add("select count(*) from t1");
ls.add("select c1,c2,c3 from t1 where condi1=1 ");
ls.add("Select c1,c2,c3 From t1 Where condi1=1 ");
ls.add("select c1,c2,c3 from t1,t2 where condi3=3 or condi4=5 order by o1,o2");
ls.add("Select c1,c2,c3 from t1,t2 Where condi3=3 or condi4=5 Order by o1,o2");
ls.add("select c1,c2,c3 from t1,t2,t3 where condi1=5 and condi6=6 or condi7=7 group by g1,g2");
ls.add("Select c1,c2,c3 From t1,t2,t3 Where condi1=5 and condi6=6 or condi7=7 Group by g1,g2");
ls.add("Select c1,c2,c3 From t1,t2,t3 Where condi1=5 and condi6=6 or condi7=7 Group by g1,g2,g3 order by g2,g3");
for(String sql:ls){
System.out.println(new SqlParser(sql));
//System.out.println(sql);
}
}
}