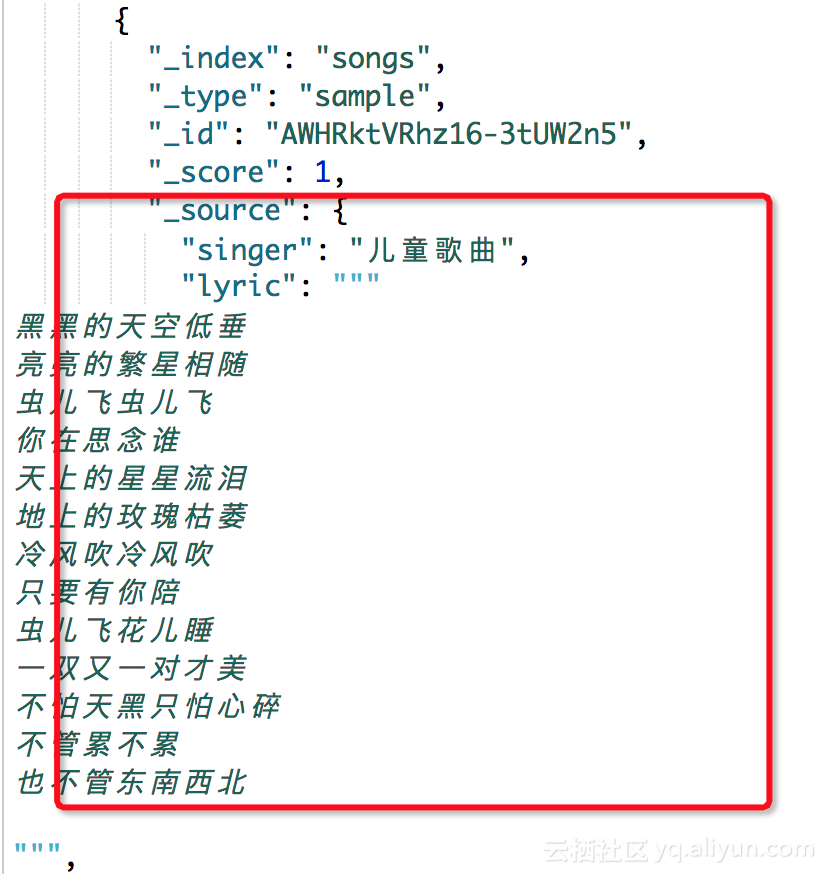
一 由來
去年由于項目的需求,要將一個任意一個文件制作成一個xml文件,并且需要保持文件內容本身不產生變化,還要能夠將這個xml重新還原為原文件。如果小型的文件還好處理,大型的xml,比如幾個G的文件,基本上就OOM了,很難直接從節點中提取數據。所以我采用了流的方式。于是有了這個文件的裁剪工具。
二 使用場景
本工具可能的使用場景:
1.對任一文件的切割/裁剪。通過字節流的方式,開始節點和終止節點,裁剪出兩個節點之間的部分。
2.往任一文件的頭/尾拼接指定字符串。可以很容易將一個文件嵌入在某一個節點中。
3.簡單的文本抽取。可以根據自己定義的規則,提取出來想要的文本內容,并且允許對提取出來的文本進行再處理(當然,只是進行簡單地抽取文字,并不是什么智能的復雜過程的抽取T_T )。
4.文本過濾。根據自己制定的規則,過濾掉指定的文字。
整個工具僅是對Java文件操作api的簡單加工,并且也沒有使用nio。在需要高效率的文件處理情景下,本工具的使用有待考量。文章目的是為了給出自己的一種解決方案,若有更好的方案,歡迎大家給出適當的建議。
三 如何使用
別的先不說,來看看如何使用吧!
1.讀取文件指定片段
讀取第0~1048個字節之間的內容。
public void readasbytes(){ FileExtractor cuter = new FileExtractor(); byte[] bytes = cuter.from("D://11.txt").start(0).end(1048).readAsBytes(); }2.文件切割
將第0~1048個字節之間的部分切割為一個新文件。
public File splitAsFile(){ FileExtractor cuter = new FileExtractor(); return cuter.from("D://11.txt").to("D://22.txt").start(0).end(1048).extractAsFile(); }3.將文件拼接到一個xml節點中
將整個文件的內容作為Body節點,寫入到一個xml文件中。返回新生成的xml文件對象。
public File appendText(){ FileExtractor cuter = new FileExtractor(); return cuter.from("D://11.txt").to("D://44.xml").appendAsFile("<Document><Body>", "</Body></Document>"); }4.讀取并處理文件中的指定內容
假如有需求:讀取11.txt的前三行文字。其中,第一行和第二行不能出現”帥”字,并且在第三行文字后加上字符串“我好帥!”。
public String extractText(){ FileExtractor cuter = new FileExtractor(); return cuter.from("D://11.txt").extractAsString(new EasyProcesser() { @Override public String finalStep(String line, int lineNumber, Status status) { if(lineNumber==3){ status.shouldContinue = false;//表示不再繼續讀取文件內容 return line+"我好帥!"; } return line.replaceAll("帥",""); } }); }4.簡單的文本過濾
將一個文件中所有的“bug”去掉,且返回一個處理后的新文件。
public File killBugs(){ FileExtractor cuter = new FileExtractor(); return cuter.from("D://bugs.txt").to("D://nobug.txt").extractAsFile(new EasyProcesser() { @Override public String finalStep(String line, int lineNumber, Status status) { return line.replaceAll("bug", ""); } }); }四 基本流程
通過接口回調的方式,將文件的讀取過程和處理過程分離開來;定義了IteratorFile類來負責遍歷一個文件,讀取文件的內容;分字節、行兩種的方式來進行文件內容的遍歷。下面的介紹,也會分為讀取和處理兩個部分單獨介紹。
五 文件的讀取
定義回調接口
定義一個接口Process,對外暴露了兩個文件內容處理方法,一個支持按字節進行讀取,一個方法支持按行讀取。
public interface Process{ /** * @param b 本次讀取的數據 * @param length 本次讀取的有效長度 * @param currentIndex 當前讀取到的位置 * @param available 讀取文件的總長度 * @return true 表示繼續讀取文件,false表示終止讀取文件 * @time 2017年1月22日 下午4:56:41 */ public boolean doWhat(byte[] b,int length,int currentIndex,int available); /** * * @param line 本次讀取到的行 * @param currentIndex 行號 * @return true 表示繼續讀取文件,false表示終止讀取文件 * @time 2017年1月22日 下午4:59:03 */ public boolean doWhat(String line,int currentIndex);讓ItratorFile中本身實現這個接口,但是默認都是返回true,不做任何的處理。如下所示:
public class IteratorFile implements Process{....../** * 按照字節來讀取遍歷文件內容,根據自定義需要重寫該方法 */ @Override public boolean doWhat(byte[] b, int length,int currentIndex,int available) { return true; } /** * 按照行來讀取遍歷文件內容,根據自定義需要重寫該方法 */ @Override public boolean doWhat(String line,int currentIndex) { return true; }......}按字節遍歷文件內容
實現按照字節的方式來進行文件的遍歷(讀取)。在這里使用了skip()方法來控制從第幾個節點開始讀取內容;然后在使用文件流讀取的時候,將每次讀取到得數據傳遞給回調接口的方法;需要注意的是,每次讀取到得數據是存在一個字節數組bytes里面的,每次讀取的長度也是需要傳遞給回調接口的。我們很容易看出,一旦dowhat()返回false,文件的讀取立即就退出了。
public void iterator2Bytes(){ init(); int length = -1; FileInputStream fis = null; try { file = new File(in); fis = new FileInputStream(file); available = fis.available(); fis.skip(getStart()); readedIndex = getStart(); if (!beforeItrator()) return; while ((length=fis.read(bytes))!=-1) { readedIndex+=length; if(!doWhat(bytes, length,readedIndex,available)){ break; } } if(!afterItrator()) return; } catch (FileNotFoundException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); }finally{ try { fis.close(); } catch (IOException e) { e.printStackTrace(); } } }按行來遍歷文件內容
常規的文件讀取方式,在while循環中,調用了回調接口的方法,并且傳遞相關的數據。
public void iterator2Line(){ init(); BufferedReader reader = null; FileReader read = null; String line = null; try { file = new File(in); read = new FileReader(file); reader = new BufferedReader(read); if (!beforeItrator()) return; while ( null != (line=reader.readLine())) { readedIndex++; if(!doWhat(line,readedIndex)){ break; } } if(!afterItrator()) return ; } catch (FileNotFoundException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); }finally{ try { read.close(); reader.close(); } catch (IOException e) { e.printStackTrace(); } } }然后,還需要提供方法來設置要讀取的源文件路徑。
public IteratorFile from(String in){ this.in = in; return this; }六 文件內容處理
FileExtractor介紹
定義了FileExtractor類,來封裝對文件內容的處理操作;該類會引用到遍歷文件所需要的類IteratorFile。
FileExtractor的基本方法
/** * 往文件頭或者文件結尾插入字符串 * @tips 不能對同一個文件輸出路徑反復執行該方法,否則會出現文本異常,因為用到了RandomAccessFile,如有需要,調用前需手動刪除原有的同名文件 * @param startStr 文件開頭要插入的字符串 * @param endStr 文件結尾要插入的字符串 * @return 生成的新文件 * @time 2017年1月22日 下午5:05:35 */ public File appendAsFile(final String startStr,String endStr){}/** * 從指定位置截取文件 * @tips 適合所有的文件類型 * @return * @time 2017年1月22日 下午5:06:36 */ public File splitAsFile(){}/** * 文本文件的特殊處理(情景:文本抽取,文本替換等) * @tips 只適合文本文件,對于二進制文件,因為換行符的原因導致文件出現可能無法執行等問題。 * @time 2017年1月22日 下午5:09:14 */ public File extractAsFile(FlowLineProcesser method) {/** * 文本文件的特殊處理(情景:文本抽取,文本替換等) * @tips 只適合文本文件,對于二進制文件,因為換行符的原因導致文件出現可能無法執行等問題。 * @time 2017年1月22日 下午5:09:14 */ public String extractAsString(FlowLineProcesser method) {} /** * 讀取指定位置的文件內容為字節數組 * @return * @time 2017年1月23日 上午11:06:18 */ public byte[] readAsBytes(){}其中,返回值為File的方法在處理完成后,都出返回一個經過內容后的新文件。
其他方法
同樣,設置源文件位置的方法,以及截取位置的相關方法
/** * 設置源文件 */ public FileExtractor from(String in){ this.in = in; return this; } /** * 設置生成臨時文件的位置(返回值為File的方法均需要設置) */ public FileExtractor to(String out) { this.out = out; return this; } /** * 文本開始截取的位置(包含此位置),字節相關的方法均需要設置 */ public FileExtractor start(int start){ this.startPos = start; return this; } /** * 文本截取的終止位置(包含此位置),字節相關方法均需要設置 */ public FileExtractor end(int end) { this.endPos = end; return this; }按字節讀取文件時的文件內容處理
有幾個重點:
1.因為要根據字節的位置來進行文件截取,所以需要根據字節來遍歷文件,所以要重寫doWhat()字節遍歷的的方法。并在外部構造一個OutPutStream來進行新文件的寫出工作。
2.每次遍歷讀取出的文件內容,都存放在一個字節數組b里面,但并不是b中的數據都是有用的,所以需要傳遞b有效長度length。
3.readedIndex記錄了到本次為止(包括本次)為止,已經讀取了多少位數據。
4.按照自己來遍歷文件時,如何判斷讀取到了的終止位置?
當(已讀的數據總長度)readedIndex>endPos(終止節點)時,說明本次讀取的時候超過了應該終止的位置,此時b數組中有一部分數據就是多讀的了,這部分數據是不應該被保存的。我們可以通過計算得到讀超了多少位,即length-(readedIndex-endPos-1),那么只要保存這部分數據就可以了。
讀取指定片段的文件內容:
//本方法在需要讀取的數據多時,不建議使用,因為byte[]是不可變的,多次讀取的時候,需要進行多次的byete[] copy過程,效率“感人”。 public byte[] readAsBytes(){ try { checkIn(); } catch (Exception e) { e.printStackTrace(); return null; } //臨時保存字節的容器 final BytesBuffer buffer = new BytesBuffer(); IteratorFile c = new IteratorFile(){ @Override public boolean doWhat(byte[] b, int length, int currentIndex, int available) { if(readedIndex>endPos){ //說明已經讀取到了endingPos位置并且讀超了 buffer.addBytes(b, 0, length-(readedIndex-endPos-1)-1); return false; }else{ buffer.addBytes(b, 0, length-1); } return true; } }; //按照字節進行遍歷 c.from(in).start(startPos).iterator2Bytes(); return buffer.toBytes(); }當文件很大時,生成一個新的文件的比較靠譜的方法,所以,類似直接返回byte[],在文件讀取之前,設置一個outputSteam,在內容循環讀取的過程中,將讀取的內容寫入到一個新文件中去。
public File splitAsFile(){ ...... final OutputStream os = FileUtils.openOut(file); try { IteratorFile itFile = new IteratorFile(){ @Override public boolean doWhat(byte[] b, int length,int readedIndex,int available) { try { if(readedIndex>endPos){ //說明已經讀取到了endingPos位置,并且讀超了readedIndex-getEnd()-1位 os.write(b, 0, length-(readedIndex-endPos-1)); return false;//終止讀取 }else{ os.write(b, 0, length); } return true; } catch (IOException e) { e.printStackTrace(); return false; } } }.from(in).start(startPos); itFile.iterator2Bytes(); } catch (Exception e) { e.printStackTrace(); this.tempFile = null; }finally{ try { os.flush(); os.close(); } catch (IOException e) { e.printStackTrace(); } } return getTempFile(); }按行來讀取時的文件內容處理
首先,再次聲明,按行來遍歷文件的時候,只適合文本文件。除非你對每一行的換行符用/r還是/n沒有要求。像exe文件,如果用行來遍歷的話,你寫出為一個新的文件的時候,任意一個的換行符的不對都可能導致一個exe文件變為”unexe”文件!
過程中,我用到了:
一個輔助類Status,來輔助控制遍歷的流程。
一個接口FlowLineProcesser,類似于一個處理文本的流水線。
Status和FlowLineProcesser是相互輔助的,Status也能輔助FlowLineProcesse是流水線的具體過程,Status是控制處理過程中怎么處理d的。
我也想了許多次,到底要不要把這個過程搞的這么復雜。但是還是先留著吧…
先看輔助類Status:
public class Status{ /** * 是否找到了開頭,默認false,若true則后續的遍歷不會執行相應的firstStep()方法 */ public boolean overFirstStep = false; /** * 是否找到了結尾,默認false,若true則后續的遍歷不會執行相應的finalStep()方法 */ public boolean overFinalStep = false; /** * 是否繼續讀取源文件,默認true表示繼續讀取,false則表示,執行本次操作后,遍歷終止 */ public boolean shouldContinue = true;}然后是FlowLineProcesser接口:
FlowLineProcesser是一個接口,類似于一個流水線。定義了兩步操作,分別對應兩個方法fistStep()和finalStep()。其中兩個方法的返回值都是String,firstStep接受到得line是真正從文件中讀取到的行,它將line經過自己的處理后,返回處理后的line給finalStep。所以,finalStep中得line其實是firstStep處理后的結果。但是最終真正返回給主處理流程的line,正是finalStep處理后的返回值。
public interface FlowLineProcesser{ /** * * @param line 讀取到的行 * @param lineNumber 行號,從1開始 * @param status 控制器 * @return * @time 2017年1月22日 下午5:02:02 */ String firstStep(String line,int lineNumber,Status status); /** * @tips * @param line 讀取到的行(是firstStep()處理后的結果) * @param lineNumber 行號,從1開始 * @param status 控制器 * @return * @time 2017年1月22日 下午5:02:09 */ String finalStep(String line,int lineNumber,Status status);}現在,可以來看一下如何去實現文本的抽取了:
所有讀取的行,都臨時存到一個stringbuilder中去。firstStep先進行一次處理,得到返回值后傳遞給finalStep,再次處理后,將得到的結果保存下來。如果最后的結果是null,則不會保存。
public String extractAsString(FlowLineProcesser method) { try { checkIn(); } catch (Exception e) { e.printStackTrace(); return null; } final StringBuilder builder = new StringBuilder(); this.mMethod = method; new IteratorFile(){ Status status = new Status(); @Override public boolean doWhat(String line, int currentIndex) { String lineAfterProcess = ""; if(!status.overFirstStep){ lineAfterProcess = mMethod.firstStep(line, currentIndex,status); } if(!status.shouldContinue){ return false; } if(!status.overFinalStep){ lineAfterProcess = mMethod.finalStep(lineAfterProcess,currentIndex,status); } if(lineAfterProcess!=null){ builder.append(lineAfterProcess); builder.append(getLineStr());//換行符被寫死在這里了 } if(!status.shouldContinue){ return false; } return true; } }.from(in).iterator2Line(); return builder.toString(); }當要抽取的文本太大的時候,可以采用生成新文件的方式。與返回string的流程基本一致。
public File extractAsFile(FlowLineProcesser method) { try { checkIn(); checkOut(); } catch (Exception e) { e.printStackTrace(); return null; } this.mMethod = method; File file = initOutFile(); if(file==null){ return null; } FileWriter fileWriter = null; try { fileWriter = new FileWriter(file); } catch (Exception e) { e.printStackTrace(); return null; } final BufferedWriter writer = new BufferedWriter(fileWriter); IteratorFile itfile = new IteratorFile(){ Status status = new Status(); @Override public boolean doWhat(String line, int currentIndex) { String lineAfterProcess = ""; if(!status.overFirstStep){ lineAfterProcess = mMethod.firstStep(line, currentIndex,status); } if(!status.shouldContinue){ return false; } if(!status.overFinalStep){ lineAfterProcess = mMethod.finalStep(lineAfterProcess,currentIndex,status); } if(lineAfterProcess!=null){ try { writer.write(lineAfterProcess); writer.newLine();//TODO 換行符在此給寫死了 } catch (IOException e) { e.printStackTrace(); return false; } } if(!status.shouldContinue){ return false; } return true; } }; itfile.from(in).iterator2Line(); if(writer!=null){ try { writer.close(); } catch (IOException e) { e.printStackTrace(); } } try { fileWriter.close(); } catch (IOException e) { e.printStackTrace(); } return getTempFile(); }好啦,介紹到此就要結束啦,我們下次再聊~
代碼包供您下載哦!―>代碼包
以上就是本文的全部內容,希望對大家的學習有所幫助,也希望大家多多支持武林網。
新聞熱點






疑難解答