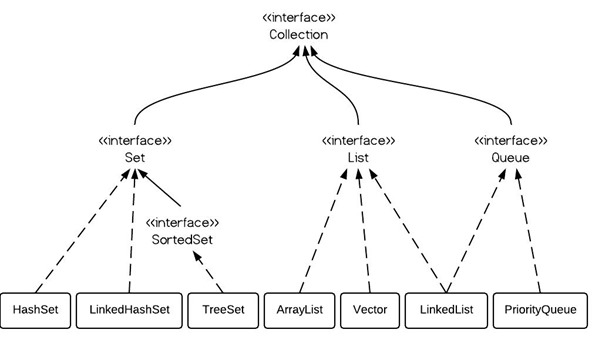
注:這是java正則表達式去除html標簽方法。
PRivate static final String regEx_script = "<script[^>]*?>[//s//S]*?<///script>"; // 定義script的正則表達式
private static final String regEx_style = "<style[^>]*?>[//s//S]*?<///style>"; // 定義style的正則表達式 private static final String regEx_html = "<[^>]+>"; // 定義HTML標簽的正則表達式 private static final String regEx_space = "//s*|/t|/r|/n";// 定義空格回車換行符private static final String regEx_w = "<w[^>]*?>[//s//S]*?<///w[^>]*?>";//定義所有w標簽
/** * @param htmlStr * @return 刪除Html標簽 * @author LongJin */ public static String delHTMLTag(String htmlStr) { Pattern p_w = Pattern.compile(regEx_w, Pattern.CASE_INSENSITIVE); Matcher m_w = p_w.matcher(htmlStr); htmlStr = m_w.replaceAll(""); // 過濾script標簽 Pattern p_script = Pattern.compile(regEx_script, Pattern.CASE_INSENSITIVE); Matcher m_script = p_script.matcher(htmlStr); htmlStr = m_script.replaceAll(""); // 過濾script標簽 Pattern p_style = Pattern.compile(regEx_style, Pattern.CASE_INSENSITIVE); Matcher m_style = p_style.matcher(htmlStr); htmlStr = m_style.replaceAll(""); // 過濾style標簽 Pattern p_html = Pattern.compile(regEx_html, Pattern.CASE_INSENSITIVE); Matcher m_html = p_html.matcher(htmlStr); htmlStr = m_html.replaceAll(""); // 過濾html標簽 Pattern p_space = Pattern.compile(regEx_space, Pattern.CASE_INSENSITIVE); Matcher m_space = p_space.matcher(htmlStr); htmlStr = m_space.replaceAll(""); // 過濾空格回車標簽 htmlStr = htmlStr.replaceAll(" ", ""); //過濾 return htmlStr.trim(); // 返回文本字符串 }
新聞熱點






疑難解答