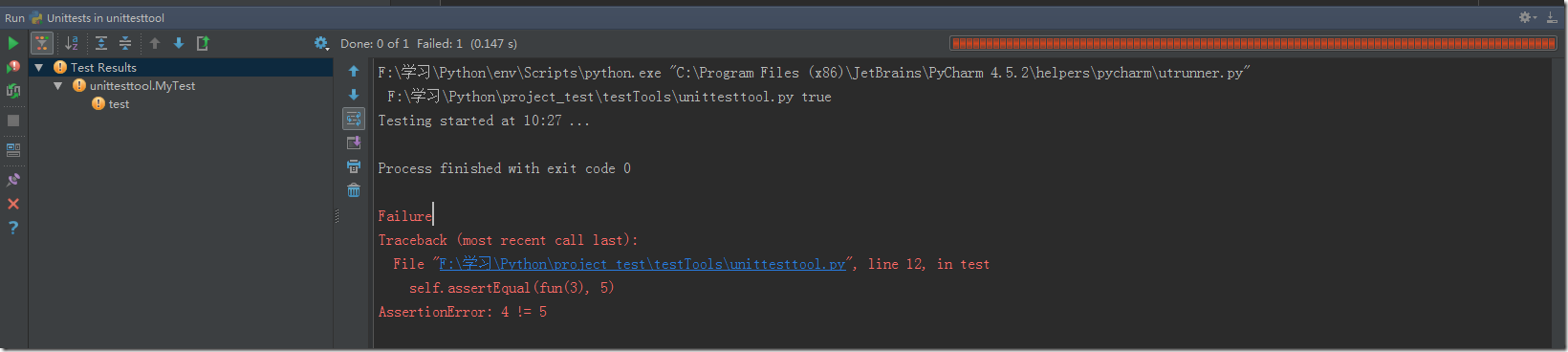
循環器(iterator)是對象的容器,包含有多個對象。通過調用循環器的next()方法 (next()方法,在Python 3.x中),循環器將依次返回一個對象。直到所有的對象遍歷窮盡,循環器將舉出StopIteration錯誤。
在for i in iterator結構中,循環器每次返回的對象將賦予給i,直到循環結束。使用iter()內置函數,我們可以將諸如表、字典等容器變為循環器。比如
標準庫中的itertools包提供了更加靈活的生成循環器的工具。這些工具的輸入大都是已有的循環器。另一方面,這些工具完全可以自行使用Python實現,該包只是提供了一種比較標準、高效的實現方式。
# import the toolsfrom itertools import *函數式編程是將函數本身作為處理對象的編程范式。在Python中,函數也是對象,因此可以輕松的進行一些函數式的處理,比如map(), filter(), reduce()函數。
itertools包含類似的工具。這些函數接收函數作為參數,并將結果返回為一個循環器。
from itertools import *rlt = imap(pow, [1, 2, 3], [1, 2, 3])for num in rlt: print(num)上面顯示了imap函數。該函數與map()函數功能相似,只不過返回的不是序列,而是一個循環器。包含元素1, 4, 27,即1**1, 2**2, 3**3的結果。函數pow(內置的乘方函數)作為第一個參數。pow()依次作用于后面兩個列表的每個元素,并收集函數結果,組成返回的循環器。
此外,還可以用下面的函數:
starmap(pow, [(1, 1), (2, 2), (3, 3)])pow將依次作用于表的每個tuple。
ifilter函數與filter()函數類似,只是返回的是一個循環器。
ifilter(lambda x: x > 5, [2, 3, 5, 6, 7]將lambda函數依次作用于每個元素,如果函數返回True,則收集原來的元素:6, 7。
此外,
ifilterfalse(lambda x: x > 5, [2, 3, 5, 6, 7])與上面類似,但收集返回False的元素:2, 3, 5。
takewhile(lambda x: x < 5, [1, 3, 6, 7, 1])當函數返回True時,收集元素到循環器。一旦函數返回False,則停止:1, 3。
dropwhile(lambda x: x < 5, [1, 3, 6, 7, 1])當函數返回False時,跳過元素。一旦函數返回True,則開始收集剩下的所有元素到循環器:6, 7, 1。
我們可以通過組合原有循環器,來獲得新的循環器。
樣例如下
for m, n in product('abc', [1, 2]): print m, n'''a 1a 2b 1b 2c 1c 2'''注意,上面的組合分順序,即ab, ba都返回。
# 從'abcd'中挑選兩個元素,比如ab, bc, ... 將所有結果排序,返回為新的循環器。combinations('abc', 2)注意,上面的組合不分順序,即ab, ba的話,只返回一個ab。
# 與上面類似,但允許兩次選出的元素重復。即多了aa, bb, cccombinations_with_replacement('abc', 2)將key函數作用于原循環器的各個元素。根據key函數結果,將擁有相同函數結果的元素分到一個新的循環器。每個新的循環器以函數返回結果為標簽。
這就好像一群人的身高作為循環器。我們可以使用這樣一個key函數: 如果身高大于180,返回”tall”;如果身高底于160,返回”short”;中間的返回”middle”。最終,所有身高將分為三個循環器,即”tall”, “short”, “middle”。
def height_class(h): if h > 180: return "tall" elif h < 160: return "short" else: return "middle"friends = [191, 158, 159, 165, 170, 177, 181, 182, 190]friends = sorted(friends, key = height_class)for m, n in groupby(friends, key = height_class): print(m) print(list(n))注意,groupby的功能類似于UNIX中的uniq命令。分組之前需要使用sorted()對原循環器的元素,根據key函數進行排序,讓同組元素先在位置上靠攏。
新聞熱點






疑難解答