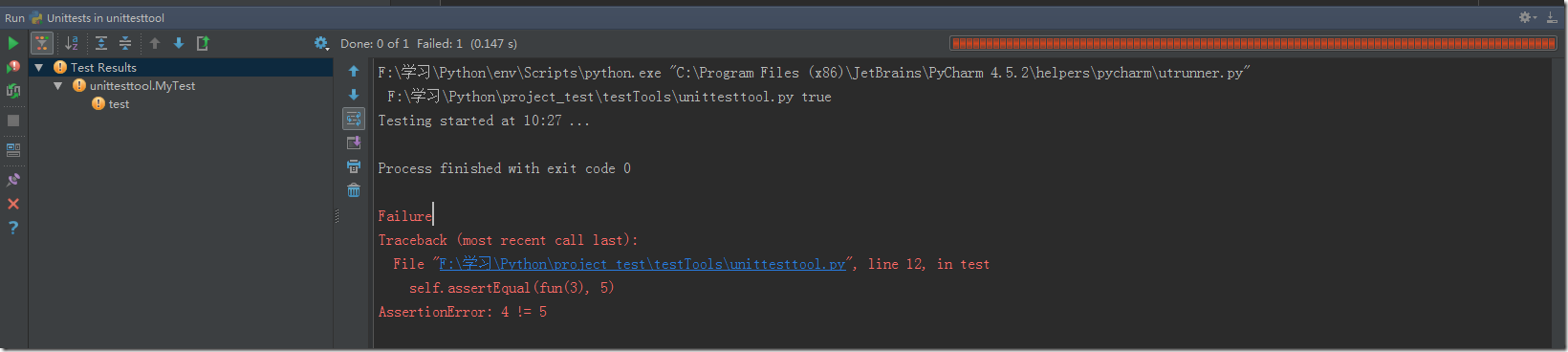
目前公司的數據庫應用除了web application的交互,還有大量的后臺數據分析系統、 電信BOSS 系統。主要用到的數據有MySQL, Vertica, orcale. 目前實現的關于數據庫的自動化測試主要有下列三個方案。
第一類應用是大家都很常見的web application和數據庫的交互。這個會在以后selenium章節討論實現方案。 第二類應用是電信BOSS 系統,就是電信計費系統的后臺。大量的通話記錄、短信記錄、流量源記錄數據輸入到源數據庫表里,然后后臺進程按照計費規則計算出每個用戶的月花費 第三類應用是數據比較簡單的,數據輸出比較簡單。 比如客戶每天通過FTP 傳給我們手機用戶訂制流量數據包的記錄,我們后臺進程定時讀取客戶傳過來的文件,根據一定的邏輯運算對訂購表和用戶屬性表,進行寫入,更新和刪除操作。第二類應用測試方案: 此類應用數據量非常膨大,業務邏輯很復雜,曾經考慮過下面的方案。 1. 采用直接導入產品線數據的方案,然后運行后臺進程,計算出結果,自動化測試工具去檢查數據準確性,這個方案等于是要完全實現一套新的BOSS 后臺產品,后面開發部門對邏輯做了改動,測試工具也要完全要做一樣的事情。考慮到目前測試和開發的人員比例關系,這種方案顯然是行不通的。 2. 采用預先設計好的數據源,能覆蓋到所有回歸測試的cases, 這種情況下輸出結果是固定的,實現起來就簡單了。但這種方案,如果產品的邏輯發生了變化,你需要插入一條新的數據源去覆蓋新的邏輯,這樣會導致很多cases的輸出會發生改變。而且你可能沒有預計到被改變的 cases就是有bug. 這種方案我們曾經用過,后來被我買拋棄了。 3. 采用一樣的數據源,比較新老版本輸出的結果。 我們自動化測試目標也是定位在回歸測試,對于新的邏輯,我們在手工測試已經覆蓋。所以我們自動化測試工具的目標是要想辦法過濾掉這些新邏輯產生的數據, 這個過濾方案要設計好,確保以后的變更不需要修改代碼,通過配置即可。 這樣我們新老版本的數據比較,就可以確保不引入bug,而且數據源直接采用實際產品線的數據,保證了覆蓋率。 我們公司整個測試方案是從2過渡到3的。第三類應用測試方案: 這個應用里面我們同樣考慮過第一類應用里面的方案一,這個顯然是不現實的。但這個應用業務邏輯比較簡單。數據的寫入表比較單一。大部分case只有1個,少部分有2-3個表。所以我們采用的方案是預先設計好輸入數據,結果數據按case 放到對應的csv文件里面。 這樣后期有新的邏輯變更,導致了數據的變更,因為輸出數據少,我們可以直接在csv文件里面修改參考數據。 下面是我們的一個參考數據配置文件例子。<database_name> <compare_item action="insert" description="比較XXX的輸出結果"> <!-- 獲取實時測試數據的SQL 語句 --> <query_sql>SELECT * FROM table1 WHERE carrieraa = '87'</query_sql> <!-- 參考結果的文件 ct.csv --> <expected_result>ct.csv</expected_result> <!-- 結果在此文件的第一和第二行,為了工具使用人員的方便,我們可以在代碼里面做邏輯判斷,如果沒有這個配置項,那就都全部文件,或者支持1,3,6這樣的配置--> <result_lines>1-2</result_lines> </compare_item> <compare_item action="update" description="比較XXX的輸出結果"> <!-- 獲取實時測試數據的SQL 語句 --> <query_sql>SELECT * FROM table1 WHERE carrierbb = '87'</query_sql> <!-- 參考結果的文件 ct.csv --> <expected_result>ct.csv</expected_result> <!-- 結果在此文件的第一和第二行,為了工具使用人員的方便,我們可以在代碼里面做邏輯判斷,如果沒有這個配置項,那就都全部文件,或者支持1,3,6這樣的配置--> <result_lines>3,4</result_lines> </compare_item> </database_name>
新聞熱點






疑難解答