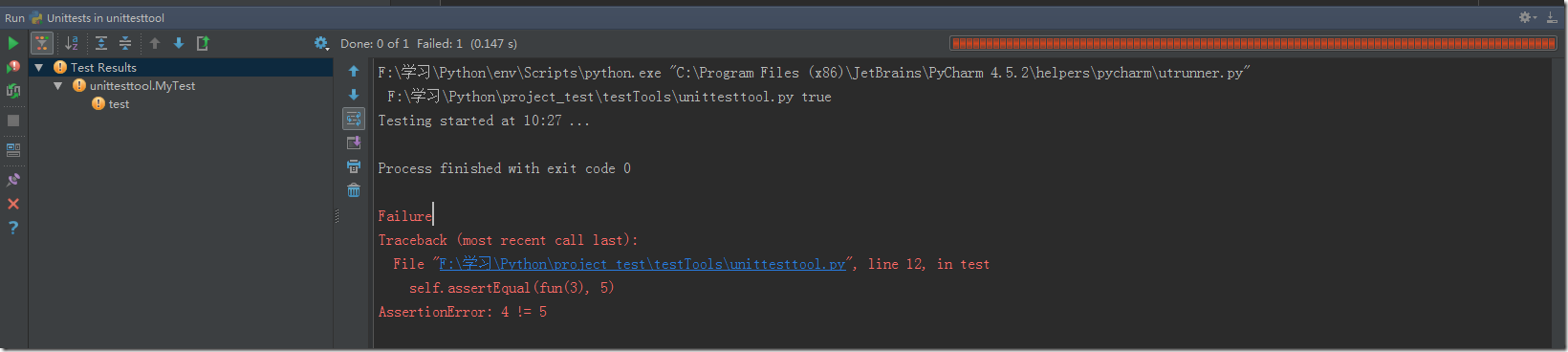
Python 英文意思:大蟒蛇: 使用python可以做哪些用途? 1、 網站的開發,利用django,flask框架搭建網站。 2、 用爬蟲實現數據挖掘、批量處理,例如:微博私信機器人,美劇批量下載,運行投資策略、刷便宜機票,爬合適房源、系統管理員腳本。 3、 再包裝其他語言程序。 關于Python的庫: 首先是python內置的標準庫,然后在此基礎上,如果想要相應的擴展,可以下載并且導入第三方庫 爬蟲部分: 首先,我們先看下什么是爬蟲呢? 爬蟲的英文翻譯叫spider,即網絡爬蟲,可以理解為在互聯網絡上爬行的一只蜘蛛,當這只蜘蛛遇到資源的時候,它就會抓取下來,至于抓取什么內容,就由控制爬蟲的代碼來完成了。 一些爬蟲的基本概念: URL:就是一種資源定位符,簡單來說就是我們通常說的網址。這邊需要注意的就是,互聯網上的每一個文件都有唯一的一個URL,它包含的信息就是指出文件的位置以及瀏覽器怎么處理它。 URL的組成: 1、協議,也叫服務方式 2、存有該資源的主機ip,或者端口號 3、主機資源的具體地址,比如目錄
Scrapy 框架學習: 基本介紹: Scrapy的基本組件 Spider:是一個類,它定義了怎么樣爬取一個網站,包括怎么跟蹤鏈接,怎樣提取數據 Scrapy.spider的屬性: Name:spider的名稱 Allowed_domains():
新聞熱點






疑難解答