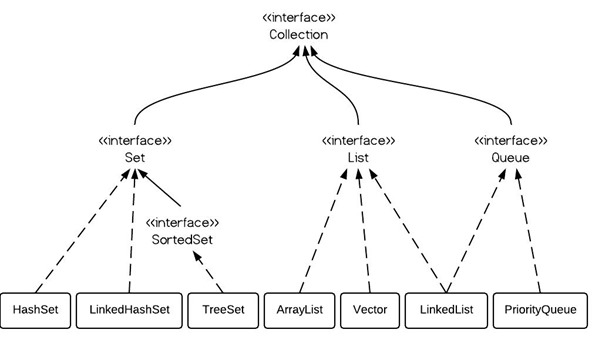
Set表示數學意義上的集合,集合內的元素是不可重復的,主要有兩個實現類,hashSet和TreeSet,因為TreeSet實現了SortedSet接口,所以TreeSet是有序的。
1、TreeSet是二叉樹實現的,已經自動排序,不允許存null值 2、HashSet是哈希表實現的,是無序的,能且僅能存放一個null值 3、HashSet是以hashCode作為每個對象的唯一標識
list又稱有序的Collection。他按對象進入的順序保存對象,所以它能對列表中的每個元素的插入和刪除為進行精確的控制。同時,它可以保存重復的對象。
1.ArrayList是實現了基于動態數組的數據結構,LinkedList基于鏈表的數據結構。 2.對于隨機訪問get和set,ArrayList覺得優于LinkedList,因為LinkedList要移動指針。 3.對于新增和刪除操作add和remove,LinedList比較占優勢,因為ArrayList要移動數據。 4、ArrayList是線程不安全的
Map提供了一個從鍵映射到值的數據結構、它用于保存鍵值對,其中值可以重復,但是鍵是唯一的,不能重復。常用到的有hashMap、TreeMap、LinkedMap。
HashMap是基于散列表實現的,采用對象的HashCode可以進行快速查詢。LinkedHashMap采用列表來維護內部的順序,TreeMap基于紅黑樹的數據結構來實現的,內部元素是按需排序的。
那么這里就有一個比較嚴重的問題了:要想保證元素不重復,可兩個元素是否重復應該依據什么來判斷呢? 這就是Object.equals方法了。但是,如果每增加一個元素就檢查一次,那么當元素很多時,后添加到集合中的元素比較的次數就非常多了。 也就是說,如果集合中現在已經有1000個元素,那么第1001個元素加入集合時,它就要調用1000次equals方法。這顯然會大大降低效率。 于是,Java采用了哈希表的原理。哈希(Hash)實際上是個人名,由于他提出一哈希算法的概念,所以就以他的名字命名了。 哈希算法也稱為散列算法,是將數據依特定算法直接指定到一個地址上。初學者可以這樣理解,hashCode方法實際上返回的就是對象存儲的物理地址(實際可能并不是)。
這樣一來,當集合要添加新的元素時,先調用這個元素的hashCode方法,就一下子能定位到它應該放置的物理位置上。 如果這個位置上沒有元素,它就可以直接存儲在這個位置上,不用再進行任何比較了;如果這個位置上已經有元素了, 就調用它的equals方法與新元素進行比較,相同的話就不存了,不相同就散列其它的地址。 所以這里存在一個沖突解決的問題。這樣一來實際調用equals方法的次數就大大降低了,幾乎只需要一兩次。 所以,Java對于eqauls方法和hashCode方法是這樣規定的: 1、如果兩個對象相同,那么它們的hashCode值一定要相同; 2、如果兩個對象的hashCode相同,它們并不一定相同(上面說的對象相同指的是用eqauls方法比較。) 你當然可以不按要求去做了,但你會發現,相同的對象可以出現在Set集合中。同時,增加新元素的效率會大大下降。 hashcode這個方法是用來鑒定2個對象是否相等的。 那你會說,不是還有equals這個方法嗎? 不錯,這2個方法都是用來判斷2個對象是否相等的。但是他們是有區別的。 一般來講,equals這個方法是給用戶調用的,如果你想判斷2個對象是否相等,你可以重寫equals方法,然后在代碼中調用,就可以判斷他們是否相等 了。簡單來講,equals方法主要是用來判斷從表面上看或者從內容上看,2個對象是不是相等。
“==”比較的是值【變量(棧)內存中存放的對象的(堆)內存地址】 equal用于比較兩個對象的值是否相同【不是比地址】
【特別注意】Object類中的equals方法和“==”是一樣的,沒有區別,而String類,Integer類等等一些類,是重寫了equals方法,才使得equals和“==不同”,所以,當自己創建類時,自動繼承了Object的equals方法,要想實現不同的等于比較,必須重寫equals方法。
“==”比”equal”運行速度快,因為”==”只是比較引用.
新聞熱點






疑難解答