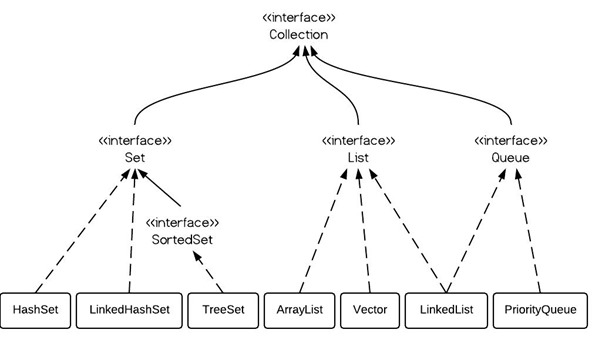
Collection是集合接口: - Set子接口:無序,不允許重復 - List子接口:有序,可以有重復元素 - Map子接口:無序,key不能重復,vlue可以重復
Iterator:只能正向遍歷集合,適用于獲取移除元素。 ListIerator:繼承Iterator,可以雙向列表的遍歷,同樣支持元素的修改。

上述類圖中,實線邊框的是實現類,比如ArrayList,LinkedList,HashMap等,折線邊框的是抽象類,比如AbstractCollection,AbstractList,AbstractMap等,而點線邊框的是接口,比如Collection,Iterator,List等。
發(fā)現一個特點,上述所有的集合類,都實現了Iterator接口,這是一個用于遍歷集合中元素的接口,主要包含 hashNext(),next(),remove()三種方法。它的一個子接口LinkedIterator在它的基礎上又添加了三種方法,分別是 add(),PRevious(),hasprevious()。也就是說如果是先Iterator接口,那么在遍歷集合中元素的時候,只能往后遍歷,被 遍歷后的元素不會在遍歷到,通常無序集合實現的都是這個接口,比如HashSet,HashMap;而那些元素有序的集合,實現的一般都是 LinkedIterator接口,實現這個接口的集合可以雙向遍歷,既可以通過next()訪問下一個元素,又可以通過previous()訪問前一個 元素,比如ArrayList。
還有一個特點就是抽象類的使用。如果要自己實現一個集合類,去實現那些抽象的接口會非常麻煩,工作量很大。這個時候就可以使用抽象類,這些抽象 類中給我們提供了許多現成的實現,我們只需要根據自己的需求重寫一些方法或者添加一些方法就可以實現自己需要的集合類,工作流昂大大降低
我單獨拷貝一部分內容如下:
/** it provides implementations of more* specific subinterfaces like <tt>Set</tt> and <tt>List</tt>. */public interface Collection<E> extends Iterable<E> {//Omit other methods 省略其他方法 }以數組實現。節(jié)約空間,但數組有容量限制,默認初始化容量為10。超出限制時會增加50%容量,不是線程安全的。
用System.arraycopy()復制到新的數組。因此最好能給出數組大小的預估值。 特點:ArrayList內部使用數組進行數據存儲transient Object[] elementData,默認初始化容量為10, private static final int DEFAULT_CAPACITY = 10;
private void grow(int minCapacity) { // overflow-conscious code int oldCapacity = elementData.length; int newCapacity = oldCapacity + (oldCapacity >> 1); if (newCapacity - minCapacity < 0) newCapacity = minCapacity; if (newCapacity - MAX_ARRAY_SIZE > 0) newCapacity = hugeCapacity(minCapacity); // minCapacity is usually close to size, so this is a win: elementData = Arrays.copyOf(elementData, newCapacity);}內部使用Node內部類進行數據存儲,以雙向鏈表實現。無容量限制,但雙向鏈表本身使用了更多空間。添加刪除速度快,查找速度慢。不是線程安全的。
每插入一個元素都要構造一個額外的Node對象,也需要額外的鏈表指針操作。
private static class Node<E> { E item; Node<E> next; Node<E> prev; Node(Node<E> prev, E element, Node<E> next) { this.item = element; this.next = next; this.prev = prev; }}按下標訪問元素-get(i)、set(i,e) 要悲劇的部分遍歷鏈表將指針移動到位 (如果i>數組大小的一半,會從末尾移起)。
插入、刪除元素時修改前后節(jié)點的指針即可,不再需要復制移動。但還是要部分遍歷鏈表的指針才能移動到下標所指的位置。
只有在鏈表兩頭的操作-add()、addFirst()、removeLast()或用iterator()上的remove()倒能省掉指針的移動。
Apache Commons 有個TreeNodeList,里面是棵二叉樹,可以快速移動指針到位。
Vector內部使用數組進行數據存儲,是線程安全的。由于每個方法都加鎖,性能低,不建議使用
public synchronized void addElement(E obj) { modCount++; ensureCapacityHelper(elementCount + 1); elementData[elementCount++] = obj;}并發(fā)優(yōu)化的ArrayList,線程安全的,寫速度慢,修改數據會增加容量開銷。
基于不可變對象策略,在修改時先復制出一個數組快照來修改,改好了,再讓內部指針指向新數組。
因為對快照的修改對讀操作來說不可見,所以讀讀之間不互斥,讀寫之間也不互斥,只有寫寫之間要加鎖互斥。但復制快照的成本昂貴,典型的適合讀多寫少的場景。
雖然增加了addIfAbsent(e)方法,會遍歷數組來檢查元素是否已存在,性能可想像的不會太好。
無論哪種實現,按值返回下標contains(e), indexOf(e), remove(e) 都需遍歷所有元素進行比較,性能可想像的不會太好。
沒有按元素值排序的SortedList。
除了CopyOnWriteArrayList,再沒有其他線程安全又并發(fā)優(yōu)化的實現如ConcurrentLinkedList。湊合著用Set與Queue中的等價類時,會缺少一些List特有的方法如get(i)。如果更新頻率較高,或數組較大時,還是得用Collections.synchronizedList(list),對所有操作用同一把鎖來保證線程安全。
Map屬于key-value數據結構
HashMap。不是線程安全的。HashMap允許null為key。
以Entry[]數組實現的哈希桶數組,用Key的哈希值取模桶數組的大小可得到數組下標。
插入元素時,如果兩條Key落在同一個桶(比如哈希值1和17取模16后都屬于第一個哈希桶),我們稱之為哈希沖突。
JDK的做法是鏈表法,Entry用一個next屬性實現多個Entry以單向鏈表存放。查找哈希值為17的key時,先定位到哈希桶,然后鏈表遍歷桶里所有元素,逐個比較其Hash值然后key值。
在JDK8里,新增默認為8的閾值,當一個桶里的Entry超過閥值,就不以單向鏈表而以紅黑樹來存放以加快Key的查找速度。
當然,最好還是桶里只有一個元素,不用去比較。所以默認當Entry數量達到桶數量的75%時,哈希沖突已比較嚴重,就會成倍擴容桶數組,并重新分配所有原來的Entry。擴容成本不低,所以也最好有個預估值。
取模用與操作(hash & (arrayLength-1))會比較快,所以數組的大小永遠是2的N次方, 你隨便給一個初始值比如17會轉為32。默認第一次放入元素時的初始值是16。
iterator()時順著哈希桶數組來遍歷,看起來是個亂序。
HashMap與HashTable有什么區(qū)別?對比Hashtable VS HashMap
兩者都是用key-value方式獲取數據。HashMap允許null值作為key和value,而Hashtable不可以HashMap不是同步的,而Hashtable是同步的。Hashtable是原始集合類之一(也稱作遺留類)。HashMap作為新集合框架的一部分在Java2的1.2版本中加入。它們之間有一下區(qū)別:
● HashMap和Hashtable大致是等同的,除了非同步和空值(HashMap允許null值作為key和value,而Hashtable不可以)。
● HashMap不是同步的,而Hashtable是同步的。
● 迭代HashMap采用快速失敗機制,而Hashtable不是,所以這是設計的考慮點。 ● HashMap沒法保證映射的順序一直不變,但是作為HashMap的子類LinkedHashMap,如果想要預知的順序迭代(默認按照插入順序),你可以很輕易的置換為HashMap,如果使用Hashtable就沒那么容易了。
6、在Hashtable上下文中同步是什么意思?
同步意味著在一個時間點只能有一個線程可以修改哈希表,任何線程在執(zhí)行hashtable的更新操作前需要獲取對象鎖,其他線程等待鎖的釋放。
特點 LindedHashMap和HashMap類似,只是里面多維護了一個添加的順序,這樣遍歷集合時候能夠按照順序輸出,不是線程安全的。
擴展HashMap,每個Entry增加雙向鏈表,號稱是最占內存的數據結構。
支持iterator()時按Entry的插入順序來排序(如果設置accessOrder屬性為true,則所有讀寫訪問都排序)。
插入時,Entry把自己加到Header Entry的前面去。如果所有讀寫訪問都要排序,還要把前后Entry的before/after拼接起來以在鏈表中刪除掉自己,所以此時讀操作也是線程不安全的了。
以紅黑樹實現,不是線程安全的.
紅黑樹又叫自平衡二叉樹: 對于任一節(jié)點而言,其到葉節(jié)點的每一條路徑都包含相同數目的黑結點。 上面的規(guī)定,使得樹的層數不會差的太遠,使得所有操作的復雜度不超過 O(lgn),但也使得插入,修改時要復雜的左旋右旋來保持樹的平衡。
支持iterator()時按Key值排序,可按實現了Comparable接口的Key的升序排序,或由傳入的Comparator控制。可想象的,在樹上插入/刪除元素的代價一定比HashMap的大。
支持SortedMap接口,如firstKey(),lastKey()取得最大最小的key,或sub(fromKey, toKey), tailMap(fromKey)剪取Map的某一段。
EnumMap的原理是,在構造函數里要傳入枚舉類,那它就構建一個與枚舉的所有值等大的數組,按Enum. ordinal()下標來訪問數組。性能與內存占用俱佳。
美中不足的是,因為要實現Map接口,而 V get(Object key)中key是Object而不是泛型K,所以安全起見,EnumMap每次訪問都要先對Key進行類型判斷,在JMC里錄得不低的采樣命中頻率。
并發(fā)優(yōu)化的HashMap。
特點 ConcurrentHashMap實現和HashMap類似,只是通過分段鎖實現一個線程安全的Map。通過分段鎖的設計既能減小鎖的開銷,又能保證數據的正確性
在JDK5里的經典設計,默認16把寫鎖(可以設置更多),有效分散了阻塞的概率。數據結構為Segment[],每個Segment一把鎖。Segment里面才是哈希桶數組。Key先算出它在哪個Segment里,再去算它在哪個哈希桶里。
也沒有讀鎖,因為put/remove動作是個原子動作(比如put的整個過程是一個對數組元素/Entry 指針的賦值操作),讀操作不會看到一個更新動作的中間狀態(tài)。
但在JDK8里,Segment[]的設計被拋棄了,改為精心設計的,只在需要鎖的時候加鎖。
支持ConcurrentMap接口,如putIfAbsent(key,value)與相反的replace(key,value)與以及實現CAS的replace(key, oldValue, newValue)。
JDK6新增的并發(fā)優(yōu)化的SortedMap,以SkipList結構實現。Concurrent包選用它是因為它支持基于CAS的無鎖算法,而紅黑樹則沒有好的無鎖算法。
原理上,可以想象為多個鏈表組成的N層樓,其中的元素從稀疏到密集,每個元素有往右與往下的指針。從第一層樓開始遍歷,如果右端的值比期望的大,那就往下走一層,繼續(xù)往前走。
典型的空間換時間。每次插入,都要決定在哪幾層插入,同時,要決定要不要多蓋一層樓。
它的size()同樣不能隨便調,會遍歷來統(tǒng)計。
所有Set幾乎都是內部用一個Map來實現, 因為Map里的KeySet就是一個Set,而value是假值,全部使用同一個Object即可。
Set的特征也繼承了那些內部的Map實現的特征。
內部是ConcurrentSkipListMap的并發(fā)優(yōu)化的SortedSet。
內部是CopyOnWriteArrayList的并發(fā)優(yōu)化的Set,利用其addIfAbsent()方法實現元素去重,如前所述該方法的性能很一般。
好像少了個ConcurrentHashSet,本來也該有一個內部用ConcurrentHashMap的簡單實現,但JDK偏偏沒提供。Jetty就自己簡單封了一個,Guava則直接用java.util.Collections.newSetFromMap(new ConcurrentHashMap()) 實現。
Queue是在兩端出入的List,所以也可以用數組或鏈表來實現。
是的,以雙向鏈表實現的LinkedList既是List,也是Queue。
以循環(huán)數組實現的雙向Queue。大小是2的倍數,默認是16。
為了支持FIFO,即從數組尾壓入元素(快),從數組頭取出元素(超慢),就不能再使用普通ArrayList的實現了,改為使用循環(huán)數組。
有隊頭隊尾兩個下標:彈出元素時,隊頭下標遞增;加入元素時,隊尾下標遞增。如果加入元素時已到數組空間的末尾,則將元素賦值到數組[0],同時隊尾下標指向0,再插入下一個元素則賦值到數組[1],隊尾下標指向1。如果隊尾的下標追上隊頭,說明數組所有空間已用完,進行雙倍的數組擴容。
用平衡二叉最小堆實現的優(yōu)先級隊列,不再是FIFO,而是按元素實現的Comparable接口或傳入Comparator的比較結果來出隊,數值越小,優(yōu)先級越高,越先出隊。但是注意其iterator()的返回不會排序。
平衡最小二叉堆,用一個簡單的數組即可表達,可以快速尋址,沒有指針什么的。最小的在queue[0] ,比如queue[4]的兩個孩子,會在queue[2*4+1] 和 queue[2*(4+1)],即queue[9]和queue[10]。
入隊時,插入queue[size],然后二叉地往上比較調整堆。
出隊時,彈出queue[0],然后把queque[size]拿出來二叉地往下比較調整堆。
初始大小為11,空間不夠時自動50%擴容。
無界的并發(fā)優(yōu)化的Queue,基于鏈表,實現了依賴于CAS的無鎖算法。
ConcurrentLinkedQueue的結構是單向鏈表和head/tail兩個指針,因為入隊時需要修改隊尾元素的next指針,以及修改tail指向新入隊的元素兩個CAS動作無法原子,所以需要的特殊的算法。
BlockingQueue,一來如果隊列已空不用重復的查看是否有新數據而會阻塞在那里,二來隊列的長度受限,用以保證生產者與消費者的速度不會相差太遠。當入隊時隊列已滿,或出隊時隊列已空,不同函數的效果見下表:
| 立刻報異常 | 立刻返回布爾 | 阻塞等待 | 可設定等待時間 | |
|---|---|---|---|---|
| 入隊 | add(e) | offer(e) | put(e) | offer(e, timeout, unit) |
| 出隊 | remove() | poll() | take() | poll(timeout, unit) |
| 查看 | element() | peek() | 無 | 無 |
定長的并發(fā)優(yōu)化的BlockingQueue,也是基于循環(huán)數組實現。有一把公共的鎖與notFull、notEmpty兩個Condition管理隊列滿或空時的阻塞狀態(tài)。
可選定長的并發(fā)優(yōu)化的BlockingQueue,基于鏈表實現,所以可以把長度設為Integer.MAX_VALUE成為無界無等待的。
利用鏈表的特征,分離了takeLock與putLock兩把鎖,繼續(xù)用notEmpty、notFull管理隊列滿或空時的阻塞狀態(tài)。
無界的PriorityQueue,也是基于數組存儲的二叉堆(見前)。一把公共的鎖實現線程安全。因為無界,空間不夠時會自動擴容,所以入列時不會鎖,出列為空時才會鎖。
內部包含一個PriorityQueue,同樣是無界的,同樣是出列時才會鎖。一把公共的鎖實現線程安全。元素需實現Delayed接口,每次調用時需返回當前離觸發(fā)時間還有多久,小于0表示該觸發(fā)了。
pull()時會用peek()查看隊頭的元素,檢查是否到達觸發(fā)時間。ScheduledThreadPoolExecutor用了類似的結構。
?
SynchronousQueue同步隊列本身無容量,放入元素時,比如等待元素被另一條線程的消費者取走再返回。JDK線程池里用它。
JDK7還有個LinkedTransferQueue,在普通線程安全的BlockingQueue的基礎上,增加一個transfer(e) 函數,效果與SynchronousQueue一樣。
紅黑樹: https://github.com/julycoding/The-Art-Of-Programming-By-July/blob/master/ebook/zh/03.01.md 跳表:http://blog.sina.com.cn/s/blog_72995dcc01017w1t.html 二叉堆:http://blog.csdn.net/lcore/article/details/9100073 ConcurrentLinkedQueue:http://www.ibm.com/developerworks/cn/java/j-jtp04186/
新聞熱點






疑難解答