本文翻譯自 Coding Geek, 原文地址
絕大多數java開發者都在使用Map類,尤其是HashMap。HashMap是一種簡單易用且強大的存取數據的方法。但是,有多少人知道HashMap內部是如何工作的?幾天前,為了對這個基本的數據結構有深入的了解,我閱讀大量的HashMap源碼(開始是Java7,然后是Java8)。在這篇文章里,我會解釋HashMap的實現,介紹Java8的新實現,聊一聊性能,內存,還有使用HashMap時已知的一些問題
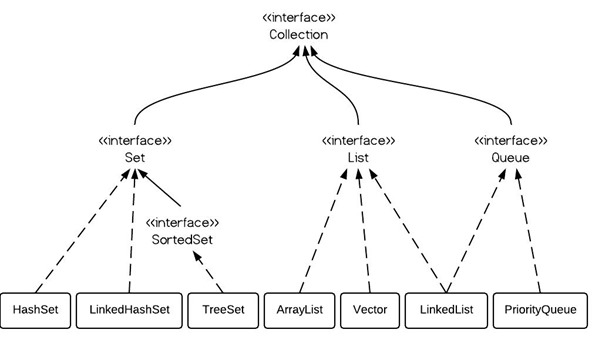
HashMap 類實現了Map<k,v>接口,這個接口的基本主要方法有:
V put(K key, V value)V get(Object key)V remove(Object key)Boolean containsKey(Object key)HashMap使用了內部類Entry<k,v>來存儲數據,這個類是一個帶有兩個額外數據的簡單 鍵-值對 結構:
Entry<k,v>的引用,這樣HashMap可以像單獨的鏈表一樣存儲數據一個hash值,代表了key的哈希值,避免了HashMap每次需要的時候再來計算下面是Java7里Entry的部分實現:
static class Entry<K,V> implements Map.Entry<K,V> { final K key; V value; Entry<K,V> next; int hash;…}HashMap存儲數據到多個單獨的entry鏈表里,所有的鏈表都登記到一個Entry數組里(Entry<K,V>[] array),并且這個內部數組默認容量是16。
下面的圖片展示了一個HashMap實例的內部存儲,一個可為null的Entry數組,每一個Entry都可以鏈接到另一個Entry來形成一個鏈表:

所有具有相同哈希值的key都會放到同一個鏈表里,具有不同哈希值的key最終也有可能在同一個鏈表里。
當一個使用者調用 put(K key, V value)或者get(Object key)這些方法時,會先計算這個Entry應該存放的鏈表在內部數組中的索引(index),然后方法會迭代整個鏈表來尋找具有相同key的Entry(使用key的 equals()方法)
get()方法,會返回這個Entry關聯的value值(如果Entry存在) put(K key, V value)方法,如果Entry存在則重置value值,如果不存在,則以key,value參數構造一個Entry并插入到鏈表的頭部。
獲取鏈表在數組內的索引通過三個步驟確定:
首先獲取Key的哈希值對哈希值再次進行哈希運算,避免出現一個很差的哈希算法,把所有的數據放到內部數組的同一個鏈表里對再次哈希的哈希值進行數組長度(最小為1)的位掩碼運算,這個運算保證生成的索引不會比數組的長度大,你可以把它當成一個優化過的取模運算下面是Java7 和 Java8處理索引的源代碼:
// the "rehash" function in JAVA 7 that takes the hashcode of the keystatic int hash(int h) { h ^= (h >>> 20) ^ (h >>> 12); return h ^ (h >>> 7) ^ (h >>> 4);}// the "rehash" function in JAVA 8 that directly takes the keystatic final int hash(Object key) { int h; return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16); }// the function that returns the index from the rehashed hashstatic int indexFor(int h, int length) { return h & (length-1);}為了更高效的運作,內部數組的大小必須是2的指數大小,讓我們來看看這是為什么。
想象一下數組大小是17,掩碼值就是16(size-1),16的二進制表示是 0…010000,那么對于任何哈希值H通過位運算H AND 16得到的索引就只會是16或者0,這意味著17大小的鏈表數組只會使用到兩個:索引為0的和索引為16的,非常浪費。
但是,如果你取2的指數大小例如16,位運算是 H AND 15,15的二進制表示是 0…001111, 那么取索引的運算就會輸出0~15之間的值,大小16的數據就能完全使用到。舉例:
H = 952 二進制表示為 0..0111011 1000, 相關的索引就是 0…01000 = 8如果H = 1576 二進制表示為 0..01100010 1000, 相關的索引就是 0…01000 = 8如果H = 12356146 二進制表示為 010111100100010100011 0010, 相關的索引就是 0…00010 = 2如果H = 59843 二進制表示為 0111010011100 0011, 相關的索引就是 0…00011 = 3這就是為什么數組的大小必須是2的指數大小,這個機制對開發人員是透明的,如果選擇了一個37大小的HashMap,那么Map會自動選擇37之后的一個2的指數大小(64)來做為內部數組的容量。
我們獲取到索引之后,函數(put,get或者remove) 訪問/迭代 關聯的鏈表,檢查是否有指定key對應的Entry。 不做改動的話,這個機制會帶來性能問題,因為這個函數會遍歷整個鏈表來檢查Entry是否存在。想象一下如果內部數組大小是初始值16,我們有兩百萬條數據需要存儲,最好的情況下, 每個鏈表里平均有 125 000個數據(2000000/16).因此,每個get(),remove(),put()會導致125 000個迭代或者操作。為了避免出現這種情況,HashMap會自動調整它的內部數組大小來保持每個鏈表盡可能的短。
當你創建一個HashMap時,你可以指定一個初始化大小和一個載入因數:
public HashMap(int initialCapacity, float loadFactor)如果不指定參數,缺省的initialCapacity是16,loadFactor是0.75,initialCapacity即代表了Map內部數組的大小。
每次當你調用put()方法加入一個新的Entry時,這個方法會檢測是否需要增加內部數組大小,因此map存儲了兩個數據:
添加一個新Entry時,put函數會檢查 map的大小 是否大于閾值 ,如果大于,則會創建一個雙倍大小的數組,當新數組的大小改變,索引計算函數(返回 哈希值 & (數組大小-1) 的位運算)也會跟著改變。因此,數組的重新調整新建了兩倍數量的鏈表,并且 重新分發現有的Entry到這些鏈表數組內(原有的鏈表數組和新創建的鏈表數組)
自動調整的目的是減少鏈表的長度從而減小 put(),remove(),get()等函數的時間開銷,所有具有相同哈希值的Entry在重新調整大小后還會在同一個鏈表內,原來在同一個鏈表內具有不同哈希值的Entry則有可能不在同一個鏈表內了。

上面這個圖展示了一個HashMap自動調整前后的情況,在調整前,為了拿到Entry E,必須要迭代5次,調整后,只需要兩次。速度快了兩倍!
注意:HashMap只會增加內部數組的大小,沒有提供方法變小。
如果你已經了解過HashMap,你知道它不是線程安全的,但是有沒有想過為什么?
想象一下這種場景:你有一個寫線程只往Map里寫新數據,還有一個讀線程只往里讀數據,為什么不能很好的運作?
因為在重新調整內部數組大小的時候,如果線程正在寫或者取對象,Map可能會使用調整前的索引,這樣就找不到調整后的Entry所在的位置了。
最壞的情況是:兩個線程同時往里面放數據,同時調用了調整內部數組大小的方法。當兩個線程都在修改鏈表時,Map其中的某個鏈表可能會陷入一個內部循環,如果你試圖在這個鏈表里取數據時,可能會永遠取不到值。
HashTable 為了避免這種情況,做了線程安全的實現。但是,所有的CRUD方法都是 同步阻塞的,所以會很慢。例如,線程1調用get(key1),線程2調用get(key2),線程3調用get(key3),同一時間只會有一個線程能拿到值,即使他們本來可以同時獲取這三個值。
其實從Java5開始就有一個更高效的線程安全的HashMap的實現了:ConcurrentHashMap。只有鏈表是同步阻塞的,因此多線程可以同時get,put,或者remove數據,只要沒有訪問同一個鏈表或者重新調整內部數組大小就行。在多線程應用里,使用這種實現顯然會更好。
為什么字符串和整數是HashMap的Key的一種很好的實現呢? 大多是因為他們的不變性。如果你選擇自己新建一個Key類并且不保證它的不變性的話,在HashMap里面可能就會丟失數據,讓我們來看下面一種使用情況:
你有一個key,內部值是1你用這個key往HashMap里存了一個數據HashMap從這個key的哈希碼里生成了一個哈希值(就是從1的哈希碼獲取)Map在最近創建的Entry里存儲了這個哈希值你把key的內部值改成2key的哈希碼改變了但是HashMap不知道(因為已經存了舊的哈希值)你想要用改變后的key獲取數據Map會計算你的key的新哈希碼,來定位到數據位于哪個鏈表: 情況1:你已經改了你的key,map試圖從錯誤的鏈表里尋找數據,當然找不到情況2:你很幸運!改變后的key生成的索引和改變前一樣,map遍歷整個鏈表尋找具有相同key的Entry。但是為了匹配key,map先會匹配key的哈希值然后調用equals()方法來對照。因為你改變后的key哈希值也已經變了,map最終也找不到相應的Entry (注:應該也有可能找到錯誤的數據出來)這里有一個具體的例子,我存了兩個鍵值對到Map里,我修改了第一個key并且試圖拿出這兩個值,只有第二個值有返回,第一個值已經丟失在Map里:
public class MutableKeyTest { public static void main(String[] args) { class MyKey { Integer i; public void setI(Integer i) { this.i = i; } public MyKey(Integer i) { this.i = i; } @Override public int hashCode() { return i; } @Override public boolean equals(Object obj) { if (obj instanceof MyKey) { return i.equals(((MyKey) obj).i); } else return false; } } Map<MyKey, String> myMap = new HashMap<>(); MyKey key1 = new MyKey(1); MyKey key2 = new MyKey(2); myMap.put(key1, "test " + 1); myMap.put(key2, "test " + 2); // modifying key1 key1.setI(3); String test1 = myMap.get(key1); String test2 = myMap.get(key2); System.out.JAVA8的改進Java8里,HashMap的內部表示已經改變了很多了。的確,Java7里HashMap的實現有1K行代碼,而Java8里有2K。我前面所說的大部分都是真的,除了Entry鏈表。在Java8里,仍然存在一個內部數組不過里面存儲的都是節點(Node),但是節點包含的信息和Entry完全一樣,因為也可以看做鏈表,下面是Java8里節點實現的部分代碼:
static class Node<K,V> implements Map.Entry<K,V> { final int hash; final K key; V value; Node<K,V> next;那么對比Java7最大的變化是什么呢?節點(Nodes)可以被樹節點(TreeNodes)繼承。樹節點是一種紅黑樹的數據結構,存儲了更多信息,可以讓你以O(log(n))的算法復雜度新增,刪除或者是獲取一個元素。
下面是一個樹節點內存儲的數據的詳細列表供參考:
static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> { final int hash; // inherited from Node<K,V> final K key; // inherited from Node<K,V> V value; // inherited from Node<K,V> Node<K,V> next; // inherited from Node<K,V> Entry<K,V> before, after;// inherited from LinkedHashMap.Entry<K,V> TreeNode<K,V> parent; TreeNode<K,V> left; TreeNode<K,V> right; TreeNode<K,V> prev; boolean red;紅黑樹是一種自平衡的二分搜索樹。它的內部機制確定了不管是新增還是移除節點,長度永遠在log(n)內。使用這種樹的一個主要優點是,當一個內部表有許多相同的數據在同一個容器內時,在樹中搜索會花費O(log(n))的時間復雜度,而鏈表會花費log(n)。
如你所見,樹比鏈表占用了更多的空間(我們稍后會談到這個)。
通過繼承,內部表可以包含 節點(鏈表) 和 樹節點(紅黑樹)兩種節點。Oracle通過下面的規則,決定同時使用這兩種數據結構: * 如果一個內部表的索引超過8個節點,鏈表會轉化為紅黑樹 * 如果內部表的索引少于6個節點,樹會變回鏈表

上圖展示了一個Java8 HashMap的內部數組的結構,具有樹(桶0),和鏈表(桶1,2,3) ,桶0因為有超過8個節點所以結構是樹。
使用HashMap會帶來一定的內存開銷,在Java7里,一個HashMap用Entry包含了 許多鍵值對,一個Entry里會有:
下一個entry的引用一個預計算好的哈希值(整型)一個key的引用一個value的引用此外,Java7里 HashMap使用一個 Entry的內部數組。假設 一個HashMap包含了N個元素,內部數組容量是 C, 額外內存開銷約為: sizeOf(integer) * N + sizeOf(reference) * (3 * N +C)
一個整數是 4 字節一個引用的大小取決于 JVM/OS/Precessor 不過通常也是4字節小貼士:從JAVA7起,HashMap類初始化的方法是懶惰的,這意味著即使你分配了一個HashMap,內部Entry數組在內存里也不會分配到空間( 4 * 數組大小 個字節),直到你調用第一個put()方法
java8的實現里,獲取內存用量變得稍微復雜了一點。因為 Entry 和 樹節點包含的數據是一樣的,但是樹節點會多6個引用和1個布爾值。
如果全部都是 普通鏈表節點,那么內存用量和java7一樣。 如果全部都是 樹節點,內存用量變成: N * sizeOf(integer) + N * sizeOf(boolean) + sizeOf(reference)* (9*N+CAPACITY ) 在大多數標準的 JVM里,這個式子等于 44 * N + 4 * CAPACITY字節
最好的情況下,get/put方法只有 O(1)的時間復雜度。但是,如果你不關心key的哈希函數,調用put/get/方法可能會非常慢。
put/get的良好性能取決于如何分配數據到內部數組不同的索引。如果key的哈希函數設計不良,你會得到一個傾斜的HashMap(和內部數組大小無關)。所有在最長鏈表上的put/get會非常慢,因為會遍歷整個鏈表。最壞的情況下(所有數據都在同一個索引下), 時間復雜度是O(n).
下面是一個例子,第一個圖片展示了一個傾斜HashMap,第二個圖則是一個平衡的HashMap:

這個傾斜HashMap在索引0上的get/put非常耗時,獲取Entry K會進行6次迭代

在這個平衡HashMap內,獲取Entry K只要進行3次迭代。這兩個HashMap存儲的數據量相同,內部數組大小也一樣。唯一的區別,就是分發數據的key的哈希函數。
下面是一個極端的例子,我創建了一個哈希函數,把兩百萬的數據都放到同一個數組索引下:
public class Test { public static void main(String[] args) { class MyKey { Integer i; public MyKey(Integer i){ this.i =i; } @Override public int hashCode() { return 1; } @Override public boolean equals(Object obj) { … } } Date begin = new Date(); Map <MyKey,String> myMap= new HashMap<>(2_500_000,1); for (int i=0;i<2_000_000;i++){ myMap.put( new MyKey(i), "test "+i); } Date end = new Date(); System.out.println("Duration (ms) "+ (end.getTime()-begin.getTime())); }}在我的機器上(core i5-2500k @ 3.6Ghz),這個程序跑了超過45分鐘(java 8u40),45分鐘后我中斷了這個程序。
現在,我運行相同的代碼,只是使用下面的哈希函數:
@Override public int hashCode() { int key = 2097152-1; return key+2097152*i; }結果只花了 46秒 !! 這個哈希函數比先前那一個有一個更好的數據分發所以put函數運行快得多。
如果我還是運行這段代碼,但是換成下面這個更好的哈希函數:
@Override public int hashCode() { return i; }現在,程序只需要2秒。
我希望你意識到哈希函數有多么重要。如果上面的測試在java7上運行,第一個和第二個測試的性能甚至還會更差(java7的復雜度是 O(n),java8是 O(log(n)))
當你使用HashMap時,你需要找到一個哈希函數,可以 把key分發到盡量多的索引上,為了做到這一點,你需要避免哈希碰撞。字符串是不錯的一種key,因為它有 很不錯的哈希函數。整數做key也不錯,因為它的哈希函數就是本身的值。
如果你需要存儲大量數據,你應該在創建HashMap時設置一個接近你預期值的初始化大小。如果你不這么做,map會用默認的 16數組大小和0.75的 載入因數。 前面11個put會很快但是第12個(16*0.75)會創建一個容量為32的新數組,第13~23個put也會很快但是第24個會再次創建一個雙倍大小的數組。這個內部重設大小的操作會出現在第48次,96次,192次……。在數據量較小時,這個操作很快,但是當數據量增大時,這個操作會費時數秒到數分鐘不等。通過指定預期初始化大小,你可以避免這些操作開銷。
但是這也有一個弊端,如果你設置了一個很大的數組大小像 2^28而你只用了2^26,你會浪費掉大量的內存(這個例子里大約是 2^30 字節)
對于簡單的使用,你不需要知道HashMap是如何工作的,因為你感覺不出 O(1)、O(n)、O(log(n))的區別。但是了解這種最常用的數據結果的底層機制總是有好處的,何況,對于java開發者來說,這是一個很典型的面試問題。在大數據量時,知道它是如果工作的,知道哈希函數的重要性 就變得非常重要了。
希望這篇文章能幫助你加深對HashMap實現細節的了解。
新聞熱點






疑難解答