Requests庫跟urllib庫的作用相似,都是根據http協議操作各種消息和頁面。
都說Requests庫比urllib庫好用,我也沒有體會到好在哪兒。
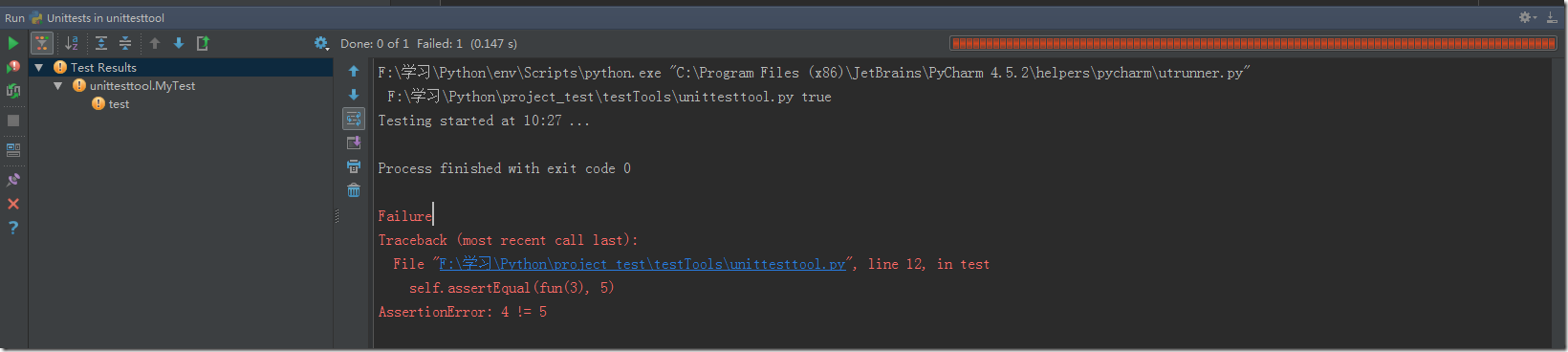
但是,urllib庫有一點不爽的是:urllib.request.urlretrieve(url, localPath)函數在將某些圖片鏈接保存到本地時,會出現錯誤:httpError:304 Forbidden
為什么會出現這個錯誤?查詢網上的說法,大多認為是Header的問題,不過我試了將完整的Header添加進去仍然不行。
本案例用Requests庫替換urllib庫,并用open().write()方法替換掉urllib.request.urlretrieve(url, localPath)方法。
一,安裝Requests庫
pip3 install requests安裝后進入python導入模塊測試是否安裝成功import requests沒有出錯即安裝成功Requests庫的使用請參閱中文官方文檔:http://cn.python-requests.org/zh_CN/latest/
二,結合了Requests庫和BeautifulSoup庫的圖片爬蟲程序
''' requests,bs4'''import osimport requestsfrom bs4 import BeautifulSoupdef getHtmlCode(url): # 該方法傳入url,返回url的html的源碼 headers = { 'User-Agent': 'MMozilla/5.0 (Windows NT 6.1; WOW64; rv:31.0) Gecko/20100101 Firefox/31.0' } r= requests.get(url,headers=headers) r.encoding='UTF-8' page = r.text return pagedef getImg(page,localPath): # 該方法傳入html的源碼,經過截取其中的img標簽,將圖片保存到本機 if not os.path.exists(localPath): # 新建文件夾 os.mkdir(localPath) soup = BeautifulSoup(page,'html.parser') # 按照html格式解析頁面 imgList = soup.find_all('img') # 返回包含所有img標簽的列表 x = 0 for imgUrl in imgList: # 列表循環
新聞熱點






疑難解答