數據庫高可用架構對于我們這些應用端開發的人來說是一個比較陌生的領域,是在具體的數據庫產品之上搭建的環境,需要像DBA這樣對數據庫產品有足夠的了解才能有所涉及,雖然不能深入其中,但可以通過一些經典的高可用架構學習其中的思想。就我所了解到的有以下幾種:
MySQL Replication
MySQL Cluster
Oracle RAC
IBM HACMP
Oracle ASM
MySQL Replication
MySQL Replication就是通過異步復制多個copy以達到提高可用性的目的,常規的復制架構有以下幾種:
Master-Slaves
Master-Master
Master-Master-Salves
1)Master-Slaves
Master- Slaves是最常用的提高可用的方法,特別是在互聯網應用中,讀遠遠大于寫,因此提高讀的可用性是首當其中的,Master-Slaves就是讓寫的操作集中在一臺數據庫Master上,然后這個Master會
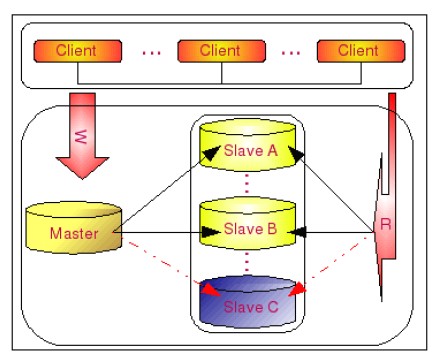
如上圖在SlaveC不可用時,讀和寫都不會中斷,等SlaveC恢復后會自動同步丟失的數據,又能重新投入運轉,可維護性非常好。但如果Master有問題就麻煩了,因此它只解決了讀的高可用性,但不保證寫的高可用性。
2)Master-Master
為解決上面談的寫的高可用性,MySQL提供了Master-Master的復制架構,如下所示:
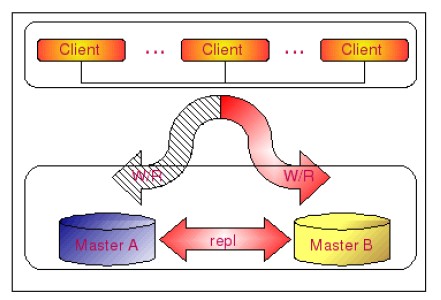
一般說來都向MasterA寫,MasterA同步數據到MasterB,當MasterA有問題時,會自動切換到MasterB,等MasterA恢復時,MasterB同步數據到MasterA
3)Master-Master-Salves
Master-Master-Salves是結合上面兩種方案,是一種同時提供讀和寫高可用的復制架構,如下圖所示:

MySQL Cluster
MySQL Cluster主要由三個部分組成:
SQL服務器節點
NDB數據存儲節點
監控和管理節點
三個部門的組成結構如下圖所示:
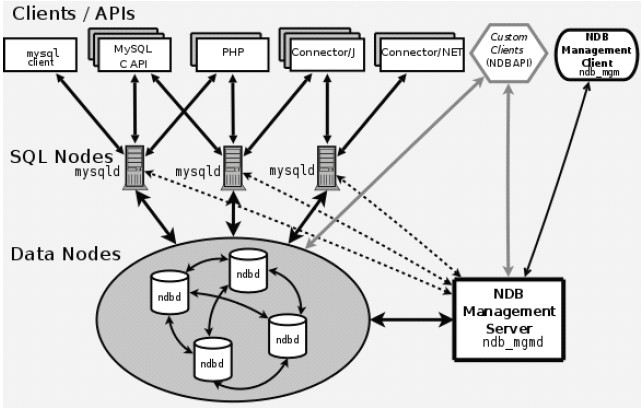
這樣的分層也是由MySQL本身把SQL處理和存儲分開的架構相關系的。
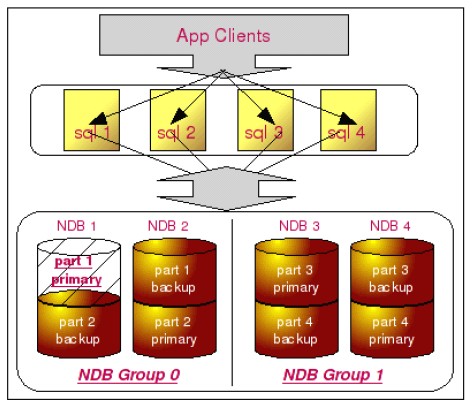
這樣一來MySQL Cluster就可以分別在SQL處理和存儲兩個層次上做高可用的復制策略。在SQL處理層次上,比較容易做集群,因為這些SQL處理是無狀態性的,完全可以通過增加機器的方式增強可用性。在存儲層次上,通過對每個節點進行備份的形式增加存儲的可用性,這類似與MySQL Replication,結構圖如下所示:
Oracle RAC
Oracle RAC和MySQL Cluster有些相似,但主要集中在SQL處理層的高可用性,而在存儲上體現不多,結構圖如下所示:
新聞熱點






疑難解答













