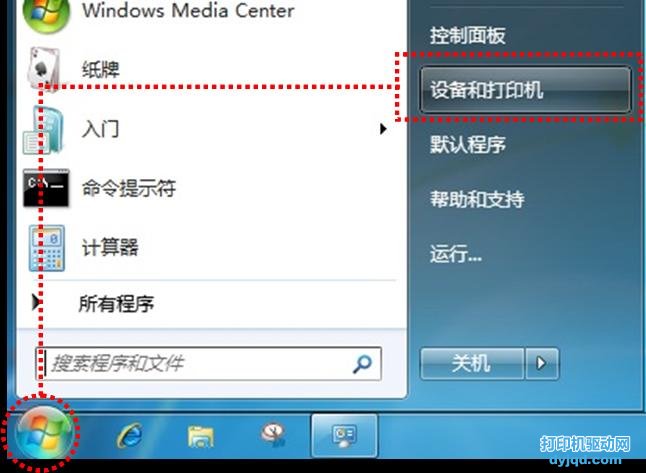
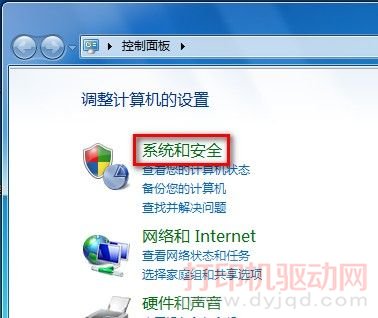
首先運(yùn)行Adobe Acrobat X Pro軟件,打開(kāi)你要提取文字的pdf文檔,如下圖所示:

定位到你想要提取文字的頁(yè)面,選中,點(diǎn)擊右鍵可以看到,當(dāng)前頁(yè)面是一張圖片,如下圖所示:

在Adobe Acrobat X Pro軟件工具欄右側(cè),依次找到工具——識(shí)別文本,如下圖所示:

點(diǎn)擊“在本文件中”,彈出識(shí)別文本的窗口,為了方便,我選擇了當(dāng)前頁(yè)面,設(shè)置中內(nèi)容一般不用設(shè)置,如有需要可以點(diǎn)擊編輯,更改設(shè)置項(xiàng)目,如下圖所示:

點(diǎn)擊“確定”后,軟件會(huì)自動(dòng)分析當(dāng)前頁(yè)面,然后自動(dòng)識(shí)別其中的文本,如下圖所示:

識(shí)別完成后,仍然停留在當(dāng)前頁(yè)面,不同的是,當(dāng)再次選擇其中的文本點(diǎn)擊右鍵后,就能看到熟悉的復(fù)制,也可以選擇“將選定項(xiàng)目導(dǎo)出為…”,如下圖所示:

復(fù)制完成后,將其粘貼到文本文檔中或者你需要的地方就可以了,如下圖所示,pdf中的文字就這樣提取出來(lái)了。

新聞熱點(diǎn)






疑難解答
圖片精選
網(wǎng)友關(guān)注