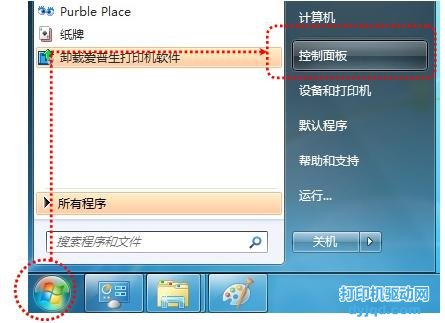
REXML 是由 Sean Russell 編寫的庫。它不是 Ruby 的唯一 XML 庫,但它是很受歡迎的一個,并且是用純 Ruby 編寫( NQXML 也是用 Ruby 編寫的, 但 XMLParser 封裝了用 C 編寫的 Jade 庫)。 在他的 REXML 概述中,Russell 評論道:
我有這樣的問題:我不喜歡令人困惑的 API。有幾種用于 Java 實現(xiàn)的 XML 解析器 API。其中大多數(shù)都遵循 DOM 或 SAX,并且在基本原理上與不斷出現(xiàn)的眾多 Java API 非常相似。也就是說,它們看 上去象是由從未使用過他們自己的 API 的理論家設(shè)計出來的。 通常,現(xiàn)有的 XML API 都很令人討厭。他們采用一種被明確設(shè)計成非常簡單、一流且功能強(qiáng)大的標(biāo)記語言, 然后用討厭的、過多的和大型 API 對它進(jìn)行封裝。甚至是為了進(jìn)行最基本的 XML 樹操作,我總是不得不參考 API 文檔; 沒有任何東西是憑直覺的,而且?guī)缀趺總€操作都很復(fù)雜。
雖然我并不認(rèn)為它有多么令人心煩,但我同意 Russell 的觀點:XML API 對于大多數(shù)使用它們的人來說無疑帶來了過多的工作量。
示例
看下面的book.xml:
引用
<library shelf="Recent Acquisitions"> <section name="Ruby"> <book isbn="0672328844"> <title>The Ruby Way</title> <author>Hal Fulton</author> <description> Second edition. The book you are now reading. Ain't recursion grand? </description> </book> </section> <section name="Space"> <book isbn="0684835509"> <title>The Case for Mars</title> <author>Robert Zubrin</author> <description>Pushing toward a second home for the human race. </description> </book> <book isbn="074325631X"> <title>First Man: The Life of Neil A. Armstrong</title> <author>James R. Hansen</author> <description>Definitive biography of the first man on the moon. </description> </book> </section> </library>
1 Tree Parsing(也就是DOM-like)
我們需要require rexml/document 庫,并且include REXML :
require 'rexml/document' include REXML input = File.new("books.xml") doc = Document.new(input) root = doc.root puts root.attributes["shelf"] # Recent Acquisitions doc.elements.each("library/section") { |e| puts e.attributes["name"] } # Output: # Ruby # Space doc.elements.each("*/section/book") { |e| puts e.attributes["isbn"] } # Output: # 0672328844 # 0321445619 # 0684835509 # 074325631X sec2 = root.elements[2] author = sec2.elements[1].elements["author"].text # Robert Zubrin 這里要注意的是xml中的屬性和值被表示為一個hash,因此我們能夠通過attributes[]來提取我們需要的值,元素的值還能通過類似于path的字符串或者整數(shù)來取得.其中用整數(shù)取的話,是1-based而不是0-based.
新聞熱點






疑難解答
圖片精選