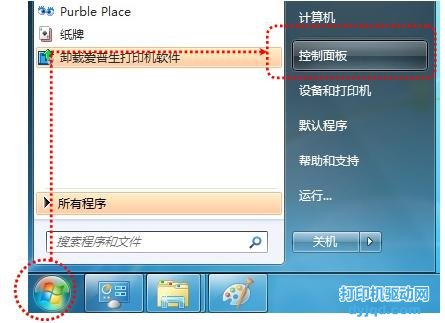
網上有很多 shell script 讀文本文件的例子,但是都沒有講出故事的全部,只說了一半。舉個例子,比如從一個 testfile 文件中讀取如下格式的文本行:
代碼如下:
$ vi testfile
ls -a -l /bin | sort
ls -a -l /bin | sort | wc
ls -a -l | grep sh | wc
ls -a -l
ls -a -l | sort | wc
最常見的一個 line by line 讀取文件內容的例子就是:
代碼如下:
$ vi readfile
#!/bin/sh
testfile=$1
while read -r line
do
echo $line
done < $testfile
$ chmod +x readfile
$ ./readfile testfile
ls -a -l /bin | sort
ls -a -l /bin | sort | wc
ls -a -l | grep sh | wc
ls -a -l
ls -a -l | sort | wc
這個例子的問題是讀取文本行后,文本格式發生了變化,和原來 testfile 文件的內容不完全一致,空格字符自動被刪除了一些。為什么會這樣呢?因為 IFS,如果在 shell script 里沒有明確指定 IFS 的話,IFS 會默認用來分割空格、制表、換行等,所以上面文本行里多余的空格和換行都被自動縮進了。
如果想要輸出 testfile 文件原有的格式,把每行(作為整體)原封不動的打印出來怎么辦?這時需要指定 IFS 變量,告訴 shell 以 "行" 為單位讀取。
代碼如下:
$ vi readfile
#!/bin/sh
IFS=""
testfile=$1
while read -r line
do
echo $line
done < $testfile
$ ./readfile testfile
ls -a -l /bin | sort
ls -a -l /bin | sort | wc
ls -a -l | grep sh | wc
ls -a -l
ls -a -l | sort | wc
上面兩種方法的輸出不是差不多嗎,有什么關系呢,第一種還美觀一些?關系重大,VPSee 昨天寫了一個模擬 shell 的 C 程序,然后又寫了一個 shell script 來測試這個 C 程序,這個 script 需要從上面的 testfile 里讀取完整一行傳給 C 程序,如果按照上面的兩種方法會得到兩種不同的輸入格式,意義完全不同:
代碼如下:
$./mypipe ls -a -l | sort | wc
$./mypipe "ls -a -l | sort | wc "
顯然我要的是第2種輸入,把 "ls -a -l | sort | wc " 作為整體傳給我的 mypipe,來測試我的 mypipe 能不能正確識別出字符串里面的各種命令。
如果不用 IFS 的話,還有一種方法可以得到上面第二種方法的效果:
新聞熱點






疑難解答