在一個單獨的服務器中安裝更多的cpu成為目前的一個趨勢。使用對稱多處理服務器(smp)的情況下,一個oracle服務器擁有8個、16個或32個cpu以及幾吉比特ram的sga都不足為奇。
oracle跟上了硬件發展的步伐,提供了很多面向多cpu的功能。從oracle8i開始,oracle在每個數據庫函數中都實現了并行性,包括sql訪問(全表檢索)、并行數據操作和并行恢復。對于oracle專業版的挑戰是為用戶的數據庫配置盡可能多的cpu。
在oracle環境中實現并行性最好的方法之一是使用oracle并行查詢(opq)。我將討論opq是如何工作的和怎樣用它來提升大的全表檢索的響應時間以及調用并行事務回滾等等。
使用opq
當在oracle中進行一次合法的、大型的全表檢索時,opq能夠極大地提高響應時間。通過opq,oracle將表劃分成如圖a所示的邏輯塊。
圖 a
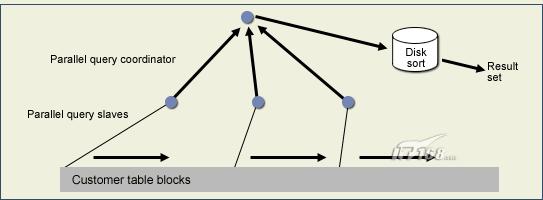
由opq劃分的表
一旦表被劃分成塊,oracle啟用并行的子查詢(有時稱為雜務進程),每個子查詢同時讀取一個大型表中的一塊。所有子查詢完畢以后,oracle將結果會傳給并行查詢調度器,它會重新安排數據,如果需要則進行排序,并且將結果傳遞給最終用戶。opq具有無限的伸縮性,因此,以前需要花費幾分鐘的全表檢索現在的響應時間卻不到1秒。
opq嚴重依賴于處理器的數量,通過并行運行之所以可以極大地提升全表檢索的性能,其前提就是使用了n-1個并行進程(n=oracle服務器上cpu的數量)。
必須注意非常重要的一點,即oracle9i能夠自動檢測外部環境,包括服務器上cpu的數量。在安裝時,oracle9i會檢查服務器上cpu的數量,設置一個名為cpu_count的參數,并使用cpu_count作為默認的初始化輸入參數。這些初始化參數會影響到oracle對內部查詢的處理。
下面就是orale在安裝時根據cpu_count而設置的一些參數:
fast_start_parallel_rollback
parallel_max_servers
log_buffer
db_block_lru_latches
新聞熱點






疑難解答













