數據庫中的每個表都是由一個或多個列構成的。在用create table 語句創建一個表時,要為每列指定一個類型。列的類型比數據類型更為特殊,它僅僅是如“數”或“串”這樣的通用類型。列的類型精確地描述了給定表列可能包含的值的種類,如smallint 或varchar( 3 2 )。
mysql的列類型是一種手段,通過這種手段可以描述一個表列包含什么類型的值,這又決定了mysql怎樣處理這些值。例如,數值值既可用數值也可用串的列類型來存放,但是根據存放這些值的類型, mysql對它們的處理將會有些不同。每種列類型都有父鎏匭勻縵攏?br> ■ 其中可以存放什么類型的值。
■ 值要占據多少空間,以及該值是否是定長的(所有值占相同數量的空間)或可變長的(所占空間量依賴于所存儲的值)。
■ 該類型的值怎樣比較和存儲。
■ 此類型是否允許null 值。
■ 此類型是否可以索引。
我們將簡要地考察一下mysql列類型以獲得一個總的概念,然后更詳細地討論描述每種列類型的屬性。
2.2.1列類型概述
mysql為除null 值以外的所有通用數據類型的值都提供了列類型。在列是否能夠包含null 值被視為一種類型屬性的意義上,可認為所有類型都包含null屬性。mysql有整數和浮點數值的列類型,如表2 - 2所示。整數列類型可以有符號也可無符號。有一種特殊的屬性允許整數列值自動生成,這對需要唯一序列或標識號的應用系統來說是非常有用的。
mysql串列類型如表2 - 3所示。串可以存放任何內容,即使是像圖像或聲音這樣的絕對二進制數據也可以存放。串在進行比較時可以設定是否區分大小寫。此外,可對串進行模式匹配(實際上,在mysql中可以在任意列類型上進行模式匹配,但最經常進行模式匹配還是在串類型上)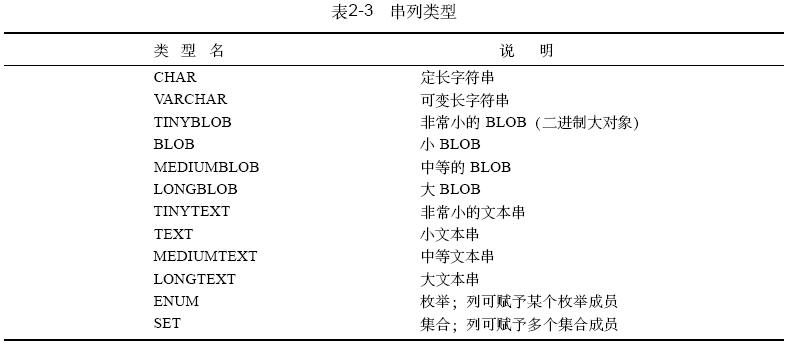
日期與時間列類型在表2 - 4中示出。對于臨時值, mysql提供了日期(有或沒有時間)、時間和時間戳(一種允許跟蹤對記錄何時進行最后更改的特殊類型)的類型。而且還提供了一種在不需要完整的日期時有效地表示年份的類型。
要創建一個表,應使用create table 語句并指定構成表列的列表。每個列都有一個名字和類型,以及與每個類型相關的各種屬性。下面是創建具有三個分別名為f、c 和i 的列的表my_table 的例子:
定義一個列的語法如下: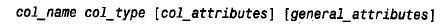
其中列名由col_name 給出。列名可最多包含64 個字符,字符包括字母、數字、下劃線及美元符號。列名可以名字中合法的任何符號(包括數字)開頭。但列名不能完全由數字組成,因為那樣可能使其與數據分不開。mysql保留諸如s e l e c t、delete 和create 這樣的詞,這些詞不能用做列名。但是函數名(如pos 和m i n)是可以使用的。
列類型col_type 表示列可存儲的特定值。列類型說明符還能表示存放在列中的值的最大長度。對于某些類型,可用一個數值明確地說明其長度。而另外一些值,其長度由類型名蘊含。例如,char(10) 明確指定了10 個字符的長度。而tinyblob 值隱含最大長度為2 5 5個字符。有的類型說明符允許指定最大的顯示寬度(即顯示值時使用多少個字符)。浮點類型允許指定小數位數,所以能控制浮點數的精度值為多少。
可以在列類型之后指定可選的類型說明屬性,以及指定更多的常見屬性。屬性起修飾類型的作用,并更改其處理列值的方式,屬性有以下類型:
■ 專用屬性用于指定列。例如,unsigned 屬性只針對整型,而b i n a ry 屬性只用于char 和varchar。
■ 通用屬性除少數列之外可用于任意列。可以指定null 或not null 以表示某個列是否能夠存放null。還可以用d e fa u lt def_value 來表示在創建一個新行但未明確給出該列的值時,該列可賦予值d e f _ v a l ue。def_value 必須為一個常量;它不能是表達式,也不能引用其他列。不能對blob 或text 列指定缺省值。
如果想給出多個列的專用屬性,可按任意順序指定它們,只要它們跟在列類型之后、通用屬性之前即可。類似地,如果需要給出多個通用屬性,也可按任意順序給出它們,只要將它們放在列類型和可能給出的列專用屬性之后即可。本節其余部分討論每個mysql的列類型,給出定義類型和描述它們的屬性的語法,諸如取值范圍和存儲需求等。類型說明如在create table 語句中那樣給出。可選的信息由方括號([ ])給出。如,語mediumint[(m)] 表示最大顯示寬度(指定為m)是可選的。另一方面,對于char( m ),無方括號表示的(m) 是必須的。
2.2.2 數值列類型
mysql的數值列類型有兩種:
■ 整型。用于無小數部分的數,如1、4 3、- 3、0 或- 7 9 8 4 3 2。可對正數表示的數據使用整數列,如磅的近似數、英寸的近似數,銀河系行星的數目、家族人數或一個盤子里的細菌數等。
■ 浮點數。用于可能具有小數部分的數,如3 . 14 15 9、- . 0 0 27 3、- 4 . 7 8、或3 9 . 3 e + 4。可將浮點數列類型用于有小數點部分或極大、極小的數。可能會表示為浮點數的值有農作物平均產量、距離、錢數(如物品價格或工資)、失業率或股票價格等等。整型值也可
以賦予浮點列,這時將它們表示為小數部分為零的浮點值。每種數值類型的名稱和取值范圍如表2 - 5所示。各種類型值所需的存儲量如表2-6 所示。
create table 語句
本章中例子中大量使用了create table 語句。您應該對此語句相當熟悉,因為我們在第1章中的教程部分使用過它。關于create table 語句也可參閱附錄d。
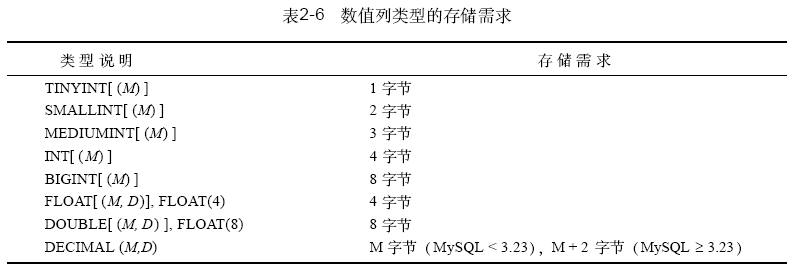
mysql提供了五種整型: t i n y i n t、s m a l l i n t、m e d i u m i n t、int 和b i g i n t。i n t 為i n t e g e r的縮寫。這些類型在可表示的取值范圍上是不同的。整數列可定義為unsigned 從而禁用負值;這使列的取值范圍為0 以上。各種類型的存儲量需求也是不同的。
取值范圍較大的類型所需的存儲量較大。
mysql提供三種浮點類型: float、double 和decimal。與整型不同,浮點類型不能是unsigned 的,其取值范圍也與整型不同,這種不同不僅在于這些類型有最大值,而且還有最小非零值。最小值提供了相應類型精度的一種度量,這對于記錄科學數據來說是非常重要的(當然,也有負的最大和最小值)。
double precision[(m, d)] 和real[(m, d)] 為double[(m, d)] 的同義詞。而numeric(m, d) 為decimal(m, d) 的同義詞。float(4) 和float(8) 是為了與odbc 兼容而提供的。在mysql3.23 以前,它們為float(10, 2) 和double(16, 4) 的同義詞。自mysql3.23 以來,float(4) 和float(8) 各不相同,下面還要介紹。
在選擇了某種數值類型時,應該考慮所要表示的值的范圍,只需選擇能覆蓋要取值的范圍的最小類型即可。選擇較大類型會對空間造成浪費,使表不必要地增大,處理起來沒有選擇較小類型那樣有效。對于整型值,如果數據取值范圍較小,如人員年齡或兄弟姐妹數,則tinyint 最合適。mediumint 能夠表示數百萬的值并且可用于更多類型的值,但存儲代價較大。bigint 在全部整型中取值范圍最大,而且需要的存儲空間是表示范圍次大的整型i n t類型的兩倍,因此只在確實需要時才用。對于浮點值, d o u b l e占用float的兩倍空間。除非特別需要高精度或范圍極大的值,一般應使用只用一半存儲代價的float型來表示數據。
在定義整型列時,可以指定可選的顯示尺寸m。如果這樣,m 應該是一個1到255 的整數。它表示用來顯示列中值的字符數。例如, mediumint(4) 指定了一個具有4 個字符顯示寬度的mediumint 列。如果定義了一個沒有明確寬度的整數列,將會自動分配給它一個缺省的寬度。缺省值為每種類型的“最長”值的長度。如果某個特定值的可打印表示需要不止m 個字符,則顯示完全的值;不會將值截斷以適合m 個字符。對每種浮點類型,可指定一個最大的顯示尺寸m 和小數位數d。m 的值應該取1到2 5 5。d 的值可為0 到3 0,但是不應大于m - 2。(如果熟悉odbc 術語,就會知道m 和d 對應于
odbc 概念的“精度”和“小數點位數”)m 和d 對float和double 都是可選的,但對于decimal 是必須的。在選項m 和d時,如果省略了它們,則使用缺省值。下面的語句創建了一個表,它說明了數值列類型的m 和d 的缺省值(其中不包括decimal,因為m 和d 對這種類型不是可選的):
如果在創建表之后使用describe my_table 語句,則輸出的field 和type 列如下所示(注意,如果用mysql的3.23 以前的版本運行這個查詢,則有一個小故障, 即bigint 的顯示寬度將是21而不是2 0。):
每一個數字列都具有一個由列類型所決定的取值范圍。如果打算插入一個不在列范圍內的值,將會進行截取:mysql將剪裁該值為取值范圍的邊界值并使用這個結果。在檢索時不進行值的剪裁。
值的剪裁根據列類型的范圍而不是顯示寬度進行。例如,一個smallint(3) 列顯示寬度為3 而取值范圍為-32768 到3 27 6 7。值12345 比顯示寬度大,但在該列的取值范圍內,因此它可以插入而不用剪裁并且作為12345 檢索。值99999 超出了取值范圍,因此在插入時被剪裁為3 27 6 7。以后在檢索中將以值3 27 6 7檢索該值。
一般賦予浮點列的值被四舍五入到這個列所指定的十進制數。如果在一個float(8, 1)的列中存儲1. 2 3 4 5 6,則結果為1. 2。如果將相同的值存入float(8, 4) 的列中,則結果為1. 2 3 4 6。這表示應該定義具有足夠位數的浮點列以便得到盡可能精確的值。如果想精確到千分之一,那就不要定義使該類型僅有兩位小數。
浮點值的這種處理在mysql3.23 中有例外,float(4) 和float(8) 的性能有所變化。這兩種類型現在為單精度( 4 字節)和雙精度( 8 字節)的類型,在其值按給出的形式存放(只受硬件的限制)這一點上說,這兩種類型是真浮點類型。
decimal 類型不同于float和decimal,其中decimal 實際是以串存放的。decimal 可能的最大取值范圍與double 一樣,但是其有效的取值范圍由m 和d 的值決定。如果改變m 而固定d,則其取值范圍將隨m 的變大而變大。表2 - 7的前三行說明了這一點。如果固定m 而改變d,則其取值范圍將隨d 的變大而變小(但精度增加)。表2 - 7的后三行說明了這一點。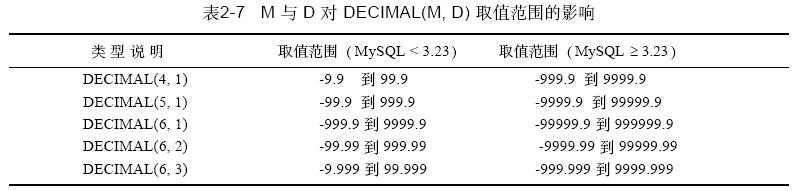
給定的decimal 類型的取值范圍取決于mysql的版本。對于mysql3.23 以前的版本,decimal(m, d) 列的每個值占用m 字節,而符號(如果需要)和小數點包括在m 字節中。因此,類型為decimal(5, 2) 的列,其取值范圍為-9.99 到9 9 . 9 9,因為它們覆蓋了所有可能的5 個字符的值。
正如mysql3.23 一樣,decimal 值是根據ansi 規范進行處理的, ansi 規范規定decimal(m, d) 必須能夠表示m 位數字及d 位小數的任何值。例如, decimal(5, 2) 必須能夠表示從-999.99 到999.99 的所有值。而且必須存儲符號和小數點,因此自mysql3.23以來decimal 值占m + 2 個字節。對于decimal(5, 2),“最長”的值(- 9 9 9 . 9 9)需要7個字節。在正取值范圍的一端,不需要正號,因此mysql利用它擴充了取值范圍,使其超
過了ansi 所規范所要求的取值范圍。如decimal(5, 2) 的最大值為9 9 9 9 . 9 9,因為有7 個字節可用。
簡而言之,在mysql3.23 及以后的版本中,decimal(m, d) 的取值范圍等于更早版本中的decimal(m + 2, d) 的取值范圍。在mysql的所有版本中,如果某個decimal 列的d 為0,則不存儲小數點。這樣做的結果是擴充了列的取值范圍,因為過去用來存儲小數點的字節現在可用來存放其他數字了。
1. 數值列的類型屬性
可對所有數值類型指定zerofill 屬性。它使相應列的顯示值用前導零來填充,以達到顯示寬度。在希望確定列值總是以給定的數字位數顯示時可利用z e r o f i l l。實際上,更準確地說是“一個給定的最小數目的數字位數”,因為比顯示寬度更寬的值可完全顯示而未被剪裁。使用下列語句可看到這一點:
其中select 語句的輸出結果如下。請注意最后一行值,它比列的顯示寬度更寬,但仍然完全顯示出來: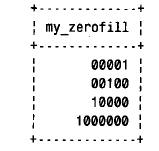
如下所示兩個屬性只用于整數列:
■ auto_increment。在需要產生唯一標識符或順序值時,可利用auto_ increment屬性。auto_increment 值一般從1開始,每行增加1。在插入null 到一個auto _increment 列時,mysql插入一個比該列中當前最大值大1的值。一個表中最多只能有一個auto_increment 列。對于任何想要使用auto_increment 的列,應該定義為not null,并定義為primary key 或定義為unique 鍵。例如, 可按下列任何一種方式定義auto_increment 列:
auto_increment 的性能將在下一小節“使用序列”中作進一步的介紹。
■ u n s i g n e d。此屬性禁用負值。將列定義為unsigned 并不改變其基本數據類型的取值范圍;它只是前移了取值的范圍。考慮下列的表說明:
itiny 和itiny_u兩列都是t i n y i n t列,并且都可取2 5 6個值,但是i t i n y的取值范圍為-12 8 到127,而itiny_u的取值范圍為0 到2 5 5。unsigned 對不取負值的列是非常有用的,如存入人口統計或出席人數的列。如果用常規的有符號列來存儲這樣的值,那么就只利用了該列類型取值范圍的一半。通過使列為u n s i g n e d,能有效地成倍增加其取值范圍。如果將列用于序列號,且將它設為u n s i g n e d,則可取原雙倍的值。在指定以上屬性之后(它們是專門用于數值列的),可以指定通用屬性null 或n o tnull。如果未指定null 或not null,則缺省為null。也可以用d e fa u lt 屬性來指定一個缺省值。如果不指定缺省值,則會自動選擇一個。對于所有數值列類型,那些可以包含null 的列的缺省將為null,不能包含null 的列其缺省為0。下面的樣例創建三個int 列,它們分別具有缺省值-1、1和null: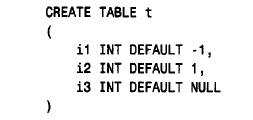
2. 使用序列
許多應用程序出于標識的目的需要使用唯一的號碼。需要唯一值的這種要求在許多場合都會出現,如:會員號、試驗樣品編號、顧客id、錯誤報告或故障標簽等等。auto_increment 列可提供唯一編號。這些列可自動生成順序編號。本節描述auto_increment 列是怎樣起作用的,從而使您能夠有效地利用它們而不至于出錯。另外,還介紹了怎樣不用auto_increment 列來產生序列的方法。
(1) mysql3.23 以前的版本中的auto _ i n c r e m e n tmysql3.23 版以前的auto_increment 列的性能如下:
■ 插入null 到auto_increment 列,使mysql自動地產生下一個序列號并將此序列號自動地插入列中。auto_increment 序列從1開始,因此插入表中的第一個記錄得到為1的序列值,而后繼插入的記錄分別得到序列值2、3 等等。一般,每個自動生成的值都比存儲在該列中的當前最大值大1。
■ 插入0 到auto_increment 與插入null 到列中的效果一樣。插入一行而不指定auto_increment 列的值也與插入null 的效果一樣。
■ 如果插入一個記錄并明確指定auto_increment 列的一個值,將會發生兩件事之一。如果已經存在具有該值的某個記錄,則出錯,因為auto_increment 列中的值必須是惟一的。如果不存在具有該值的記錄,那么新記錄將被插入,并且如果新記錄的auto_increment 列中的值是新的最大值,那么后續行將用該值的下一個值。換句話說,也就是可以通過插入一個具有比當前值大的序列值的記錄,來增大序列的計數器。增大計數器會使序列出現空白,但這個特性也有用。例如創建一個具有auto _increment 列的表,但希望序列從1000 而不是1開始。則可以用后述的兩種辦法之一達到此目的。一個辦法是插入具有明確序列值1000 的第一個記錄,然后通過插入null 到auto_increment 列來插入后續的記錄。另一個辦法是插入
auto_increment 列值為999 的假記錄。然后第一個實際插入的記錄將得到一個序列號10 0 0,這時再將假記錄刪除。
■ 如果將一個不合規定的值插入auto_increment 列,將會出現難以預料的結果。
■ 如果刪除了在auto_increment 列中含有最大值的記錄,則此值在下一次產生新值時會再次使用。如果刪除了表中的所有記錄,則所有值都可以重用;相應的序列重新從1開始。
■ replace 語句正常起作用。
■ update語句按類似插入新記錄的規則起作用。如果更新一個auto _ i n c r e m e n t列為null 或0,則會自動將其更新為下一個序列號。如果試圖更新該列為一個已經存在的值,將出錯(除非碰巧設置此列的值為它所具有的值,才不會出錯,但這沒有任何意義)。如果更新該列的值為一個比當前任何列值都大的值,則以后序列將從下一個值繼續進行編號。
■ 最近自動產生的序列編號值可調用l a s t _ insert_id( ) 函數得到。它使得能在其他不知道此值的語句中引用auto_increment 值。l a s t _ insert_id( ) 依賴于當前服務器會話中生成的auto_increment 值; 它不受與其他客戶機相關的auto_increment 活動的影響。如果當前會話中沒有生成auto_increment 值,則l a s t _ insert_id( ) 返回0。能夠自動生成順序編號這個功能特別有用。但是剛才介紹的auto_increment 性能有兩個缺陷。首先,序列中頂上的記錄被刪除時,序列值的重用使得難于生成可能刪除和插入記錄的應用的一系列單調(嚴格遞增)值。其次,利用從大于1的值開始生成序列的方法是很笨的。
(2) mysql3.23 版以后的auto_incrementmysql3.23 對auto_increment 的性能進行了下列變動以便能夠處理上述問題:
■ 自動順序生成的值嚴格遞增且不重用。如果最大的值為143 并刪除了包含這個值的記錄,mysql繼續生成下一個值14 4。
■ 在創建表時,可以明確指定初始的序列編號。下面的例子創建一個auto _ i n c r e -ment 列seq 從1,000,000 開始的表:
在一個表具有多個列時(正如多數表那樣),最后的auto_increment = 1000000子句應用到哪一列是不會混淆的,因為每個表只能有一個auto_increment 列。
(3) 使用auto_increment 應該考慮的問題在使用auto_increment 列時,應該記住下列要點:
■ auto_increment 不是一種列類型,它只是一種列類型屬性。此外, auto _increment 是一種只能用于整數類型的屬性。mysql早于3.23 的版本并不嚴格服從這個約束,允許定義諸如char 這樣的列類型具有auto_increment 屬性。但是只有整數類型作為auto_increment 列正常起作用。
■ auto_increment 機制的主要目的是生成一個正整數序列,并且如果以這種方式使用,則auto_increment 列效果最好。所以應該定義auto_increment 列為u n s i g n e d。這樣做的優點是在到達列類型的取值范圍上限前可以進行兩倍的序列編號。在某些環境下,也有可能利用auto_increment 列來生成負值的序列,但是我們不建議這樣做。如果您決定要試一下,應該保證進行充分的試驗,并且在升級到不同的mysql版本時需要重新測試。筆者的經驗表明,不同的版本中,負序列的性能并不完全一致。
■ 不要認為對某個列定義增加auto_increment 是一個得到無限的編號序列的奇妙方法。事實并非這樣; auto_increment 序列受基礎列類型的取值范圍所限制。例如,如果使用tinyint unsigned 列,則最大的序列號為2 5 5。在達到這個界限時,應用程序將開始出現“重復鍵”錯誤。
■ mysql3.23 引入了不重用序列編號的新auto_increment 性能,并且允許在create table 語句中指定一個初始的序列編號。這些性能在使用下列形式的delete 語句刪除了表中所有記錄后可以撤消:
在此情形下,序列重新從1開始而不按嚴格的增量順序繼續增加。即使在c r e at etable 語句中明確指定了一個初始的序列編號,相應的序列也會從頭開始。出現這種情形的原因在于mysql優化完全刪空一個表的delete 語句的方法上;它從頭開始重新創建數據文件和索引文件而不是去刪除每個記錄,這樣就丟失了所有的序列號信息。如果要刪除所有記錄,但希望保留序列信息,可以取消優化并強制mysql執行逐行的刪除操作,如下所示: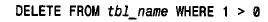
如果使用的是3 . 2 3以上的版本,怎樣保持嚴格的增量序列?方法之一是保持一個只用來生成auto_increment 值的獨立的表,永遠不從這個表中刪除記錄。在這種情況下,獨立表中的值永遠不會重用。在主表中需要生成一個新記錄時,首先在序列編號表中插入一個null。然后對希望包含序列編號的列使用l a s t _ insert_id( ) 的值將該記錄插入主表,如下所示:
如果想要編寫一個生成auto_increment 值的應用程序,但希望序列從100 而不是1開始。再假定希望這個程序可移植到所有mysql版本。怎樣來完成它呢?如果可移植是一個目標,那么不能依賴mysql3.23 所提供的在create table 語句中指定初始序列編號的功能。而是在想要插入一個記錄時,首先用下列語句檢查表是否是空的: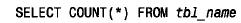
這個步驟雖然是附加的,但不會花費太多的時間,因為沒有where 子句的select count(*) 是優化的,返回很快。如果表是空的,則插入記錄并明確地對序列編號列指定值10 0。如果表不空,則對序列編號列值指定null 使mysql自動生成下一個編號。此方法允許插入序列編號為10 0、101等的記錄,它不管mysql是否允許指定初始序列值都能正常工作。如果要求序列編號即使是從表中刪除了記錄后也要嚴格遞增,則此方法不起作用。在這樣的情形下,可將此方法與前面描述的什么也不做只是用來產生用于主表的序列編號的輔助表技術結合使用。為什么會希望從一個大于1的序列編號開始呢?一個原因是想使所有序列編號全都具有相同的數字位數。如果需要生成顧客id 號,并且希望不要多于一百萬個顧客,則可以從1000 000
開始編號。在對顧客id 值計數的數字位數改變之前,可以追加一百萬個顧客。當然,強制序列編號為一個固定寬度的另一個方法是采用zerofill 列。對于有的情形,這樣做有可能會出問題。例如,如果在perl 或php 腳本中處理具有前導零的序列編號,則必須仔細地將它們只作為串使用;如果將它們轉換成數字,前導零將會丟失。下面的短perl 腳本說明了處理編號時可能會出的問題: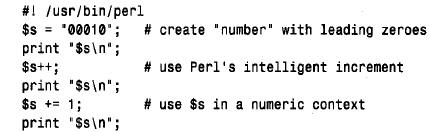
打印時,此腳本給出下列輸出:
perl’s‘+ +’自動增量操作是很靈巧的而且可以利用串或數值建立序列值,但‘+ =’操作只應用于數值。在所顯示的輸出中,可看到‘ + =’引起串到數值的轉換并且丟失了$s 值中的前導零。
序列不從1開始的另一個原因從技術的角度來說可能不值一提。例如,在分配會員號時,序列號不要從1開始,以免出現關于誰是第一號的政治爭論。
(4) 不用auto_increment 生成序列生成序列號的另一個方法根本就不需要使用auto_increment 列。它利用取一個參數的l a s t _ insert_id( ) 函數的變量來生成序列號。(這種形式在mysql3.22.9. 中引入)如果利用l a s t _ insert_id(expr) 來插入或更新一個列, 則下一次不用參數調用l a s t _ insert_id( ) 時,將返回expr 的值。換句話說,就像由auto_increment 機制生成的那樣對expr 進行處理。這樣使得能生成一個序列號,然后可在以后的客戶會話中利用它,用不著取受其他客戶機影響的值。利用這種策略的一種方法是創建一個包含一個值的單行表,該值在想得到序列中下一個值時進行更新。例如,可創建如下的表: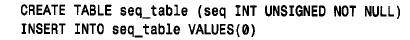
上面的語句創建了表seq_table 并用包含seq 值0 的行對其進行初始化。可利用這個表產生下一個序列號,如下所示: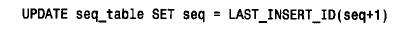
該語句取出seq 列的當前值并對其加1,產生序列中的下一個值。利用l a s t _ insert _id(seq + 1) 生成新值使它就像一個auto_increment 值一樣,而且此值可在以后的語句中通過調用無參數的l a s t _ insert_id( ) 來取出。即使某個其他客戶機同時生成了另一個序列號,上述作用也不會改變,因為l a s t _ insert_id( ) 是客戶機專用的。如果希望生成增量不是1的編號序列或負增量的編號序列,也可以利用這個方法。例如,下面兩個語句可以用來分別生成一個增量為100 的編號序列和一個負的編號序列: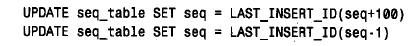
通過將seq 列設置為相應的初始值,可利用這個方法生成以任意值開始的序列。關于將此序列生成方法用于多個計數器的應用,可參閱第3章。
2.2.3 串列類型
mysql提供了幾種存放字符數據的串類型。串常常用于如下這樣的值:
在某種意義上,串實際是一種“通用”類型,因為可用它們來表示任意值。例如,可用串類型來存儲二進制數據,如影像或聲音,或者存儲gzip 的輸出結果,即存儲壓縮數據。對于所有串類型,都要剪裁過長的值使其適合于相應的串類型。但是串類型的取值范圍很不同,有的取值范圍很小,有的則很大。取值大的串類型能夠存儲近4gb 的數據。因此,應該使串足夠長以免您的信息被切斷(由于受客戶機/服務器通信協議的最大塊尺寸限制,列
值的最大限額為2 4 mb)。
表2 - 8給出了mysql定義串值列的類型,以及每種類型的最大尺寸和存儲需求。對于可變長的列類型,各行的值所占的存儲量是不同的,這取決于實際存放在列中的值的長度。這個長度在表中用l 表示。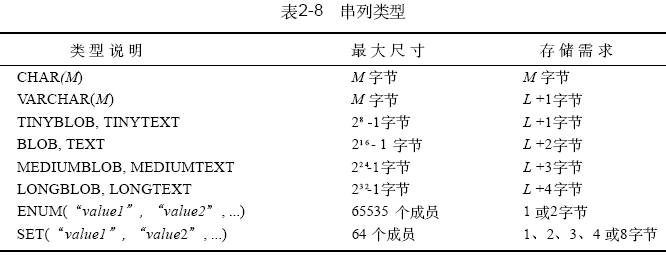
l 以外所需的額外字節為存放該值的長度所需的字節數。mysql通過存儲值的內容及其長度來處理可變長度的值。這些額外的字節是無符號整數。請注意,可變長類型的最大長度、此類型所需的額外字節數以及占用相同字節數的無符號整數之間的對應關系。例如,
mediumblob 值可能最多22 4 - 1字節長并需要3 個字節記錄其結果。3 個字節的整數類型mediumint 的最大無符號值為22 4 - 1。這并非偶然。
1. char 和varchar 列類型
char 和varchar 是最常使用的串類型。它們是有差異的, char 是定長類型而varchar 是可變長類型。char(m) 列中的每個值占m 個字節;短于m 個字節的值存儲時在右邊加空格(但右邊的空格在檢索時去掉)。varchar(m) 列的值只用所必需的字節數來存放(結尾的空格在存儲時去掉,這與ansi sql 的varchar 值的標準不同),然后再加一個字節記錄其長度。如果所需的值在長度上變化不大,則char 是一種比varchar 好的選擇,因為處理行長度固定的表比處理行長度可變的表的效率更高。如果所有的值長度相同,由于需要額外的字節來記錄值的長度,varchar 實際占用了更多的空間。在mysql3.23 以前,char 和varchar 列用最大長度為1到255 的m 來定義。從mysql3.23 開始,char(0) 也是合法的了。在希望定義一個列,但由于尚不知道其長度,所以不想給其分配空間的情況下, char(0) 列作為占位符很有用處。以后可以用alte rtable 來加寬這個列。如果允許其為null,則char(0) 列也可以用來表示o n / o ff 值。這樣的列可能取兩個值,null 和空串。char(0) 列在表中所占的空間很小,只占一位。除少數情況外,在同一個表中不能混用char 和varchar。mysql根據情況甚至會將列從一種類型轉換為另一種類型。這樣做的原因如下:
■ 行定長的表比行可變長的表容易處理(其理由請參閱2 . 3節“選擇列的類型”)。
■ 表行只在表中所有行為定長類型時是定長的。即使表中只有一列是可變長的,該表的行也是可變長的。
■ 因為在行可變長時定長行的性能優點完全失去。所以為了節省存儲空間,在這種情況下最好也將定長列轉換為可變長列。這表示,如果表中有varchar 列,那么表中不可能同時有char 列;mysql會自動地將它們轉換為varchar 列。例如創建如下一個表:
請注意,varchar 列的出現使mysql將c1也轉換成了varchar 類型。如果試圖用alter table 將c1轉換為char,將不起作用。將varchar 列轉換為char 的惟一辦法是同時轉換表中所有varchar 列: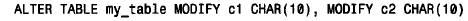
blob 和text 列類型像varchar 一樣是可變長的,但是它們沒有定長的等價類型,因此不能在同一表中與blob 或text 列一起使用char 列。這時任何char 列都將被轉換為varchar 列。定長與可變長列混用的情形是在char 列短于4 個字符時,可以不對其進行轉換。例如,mysql不會將下面所創建的表中的char 列轉換為varchar 列:
短于4個字符的列不轉換的原因是,平均情況下,不存儲尾空格所節省的空間被va r c ha r列中記錄每個值的長度所需的額外字節所抵消了。實際上,如果所有列都短, mysql將會把所定義的所有列從varchar 轉換為char。mysql這樣做的原因是,這種轉換平均來說不會增加存儲需求,而且使表行定長,從而改善了性能。如果按如下創建一個表,varchar 列全都會轉換為char 列:
2. blob 與text 列類型
blob 是一個二進制大對象,是一個可以存儲大量數據的容器,可以使其任意大。在mysql中,blob 類型實際是一個類型系列( t i n y b l o b、b l o b、m e d i u mb l o b、l o n g b l o b),除了在可以存儲的最大信息量上不同外(請參閱表2 - 8),它們是等同的。
mysql還有一個text 類型系列( t i n y t e x t、t e x t、m e d i u m t e x t、l o n g t e x t)。除了用于比較和排序外,它們在各個方面都與相應的blob 類型等同,blob 值是區分大小寫的,而text 值不區分大小寫。blob 和text 列對于存儲可能有很大增長的值或各行大小有很大變化的值很有用,例如,字處理文檔、圖像和聲音、混合數據以及新聞文章等等。blob 或text 列在mysql3.23 以上版本中可以進行索引,雖然在索引時必須指定一個用于索引的約束尺寸,以免建立出很大的索引項從而抵消索引所帶來的好處。除此之外,一般不通過查找blob 或text 列來進行搜索,因為這樣的列常常包含二進制數據(如圖像)。常見的做法是用表中另外的列來記錄有關blob 或text 值的某種標識信息,并用這些信息來確定想要哪些行。使用blob 和text 列需要特別注意以下幾點:
■ 由于blob 和text 值的大小變化很大,如果進行的刪除和更新很多,則存儲它們的
表出現高碎片率會很高。應該定期地運行optimize table 減少碎片率以保持良好的
性能。要了解更詳細的信息請參閱第4章。
■ 如果使用非常大的值,可能會需要調整服務器增加max_allowed_packet 參數的值。詳細的信息請參閱第11章“常規的mysql管理”。如果需要增加希望使用非常大的值的客戶機的塊尺寸,可見附錄e“mysql程序參考”,該附錄介紹了怎樣對mysql和mysqldump 客戶機進行這種塊尺寸的增加。
3. enum 和set 列類型
enum 和set 是一種特殊的串類型,其列值必須從一個固定的串集中選擇。它們之間的主要差別是enum 列值必須確實是值集中的一個成員,而set 列值可以包括集合中任意或所有的成員。換句話說, enum 用于互相排斥的值,而s e t列可以從一個值的列表中選擇多個值。
enum 列類型定義了一個枚舉。可賦予enum 列一個在創建表時指定的值列表中選擇的成員。枚舉可具有最多65 536 個成員(其中之一為mysql保留)。枚舉通常用來表示類別值。例如,定義為enum (“n”, “y”) 的列中的值可以是“n”或“y”。或者可將enum 用于諸如調查或問卷中的多項選擇問題,或用于某個產品的可能尺寸或顏色等:
如果正在處理web 頁中的選擇,那么可以利用enum 來表示站點訪問者在某頁上的互相排斥的單選鈕集合中進行的選擇。例如,如果運行一個在線比薩餅訂購服務系統,可用enum 來表示顧客訂購的比薩餅形狀: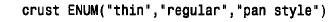
如果枚舉類別表示計數,在建立該枚舉時最重要的是選擇合適的類別。例如,在記錄實驗室檢驗中白血球的數目時,可能會將計數分為如下的幾組: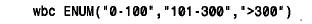
在某個測試結果以精確的計數到達時,要根據該值所屬的類別來記錄它。但如果想將列從基于類別的enum 轉換為基于精確計數的整數時,不可能恢復原來的計數。在創建set 列時,要指定一個合法的集合成員列表。在這種意義上, set 類型與enum是類似的。但是set 與enum 不同,每個列值可由來自集合中任意數目的成員組成。集合中最多可有64 個成員。對于值之間互斥的固定集合,可使用set 列類型。例如,可利用set 來表示汽車的可用選件,如下所示:
然后,特定的set 值將表示顧客實際訂購哪些選件,如下所示:
空串表示顧客未訂購任何選件。這是一個合法的set 值。set 列值為單個串。如果某個值由多個集合成員組成,那么這些成員在串中用逗號分隔。顯然,這表示不應該用含有逗號的串作為set 成員。set 列的其他用途是表示諸如病人的診斷或來自web 頁的選擇結果這樣的信息。對于診斷,可能會有一個向病人提問的標準癥狀清單,而病人可能會表現出某些癥狀或所有的癥狀。對于在線比薩餅服務系統,用于訂購的web 頁應該具有一組復選框,用來表示顧客想在比薩餅上加的配料。對enum 或set 列的合法值列表的定義很重要,例如:
■ 正如上面所介紹的,此列表決定了列的可能合法值。
■ 可按任意的大小寫字符插入enum 或set 值,但是列定義中指定的串的大小寫字符決定了以后檢索它們時的大小寫。例如,如果有一個enum (“y”, “n”) 列,但您在其中存儲了“ y”和“n”,當您檢索出它們時顯示的是“ y”和“n”。這并不影響比較或排序的狀態,因為enum 和set 列是不區分大小寫的。
■ 在enum 定義中的值順序就是排序順序。set 定義中的值順序也決定了排序順序,但是這個關系更為復雜,因為列值可能包括多個集合成員。
■ set 定義中的值順序決定了在顯示由多個集合成員組成的set 列值時,子串出現的順序。
enum 和set 被歸為串類型是由于在建立這些類型的列時,枚舉和集合成員被指定為串。但是,這些成員在內部存放時作為數值,而且同樣可作為數值來處理。這表示enum 和s e t類型比其他的串類型更為有效,因為通常可用數值運算而不是串運算來處理它們。而且這還表示enum 和set 值可用在串或數值的環境中。
列定義中的enum 成員是從1開始順序編號的。(0 被mysql用作錯誤成員,如果以串的形式表示就是空串。)枚舉值的數目決定了enum 列的存儲大小。一個字節可表示256 個值,兩個字節可表示65 536 個值。(可將其與一字節和兩字節的整數類型t i n y i n t、
unsigned 和smallint unsigned 進行對比。)因此,枚舉成員的最大數目為65 536(包括錯誤成員),并且存儲大小依賴于成員數目是否多于256 個。在enum 定義中,可以最多指定65 535(而不是65 536)個成員,因為mysql保留了一個錯誤成員,它是每個枚舉的隱含成員。在將一個非法值賦給enum 列時,mysql自動將其換成錯誤成員。下面有一個例子,可用mysql客戶機程序測試一下。它給出枚舉成員的數值順序,而且還說明了null 值無順序編號:
可對enum 成員按名或者按編號進行運算,例如: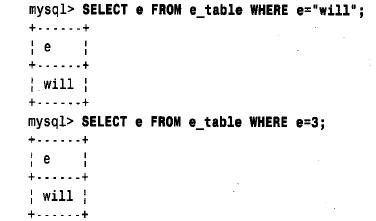
可以定義空串為一個合法的枚舉成員。與列在定義中的其他成員一樣,它將被賦予一個非零的數值。但是使用空串可能會引起某些混淆,因為該串也被作為數值為0 的錯誤成員。在下面的例子中,將非法的枚舉值“ x”賦予enum 列引起了錯誤成員的賦值。僅在以數值
形式進行檢索時,才能夠與空串區分開: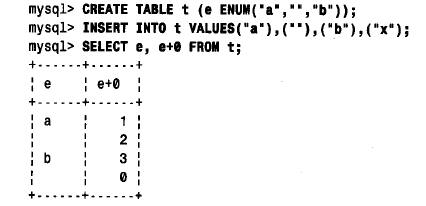
set 列的數值表示與enum 列的表示有所不同,集合成員不是順序編號的。每個成員對應set 值中的一個二進制位。第一個集合成員對應于0 位,第二個成員對應于1位,如此等等。數值set 值0 對應于空串。set 成員以位值保存。每個字節的8 個集合值可按此方式存
放,因此set 列的存儲大小是由集合成員的數目決定的,最多64 個成員。對于大小為1到8、9 到16、17 到2 4、25 到3 2、33 到64 個成員的集合,其set 值分別占用1、2、3、4 或8個字節。
用一組二進制位來表示set 正是允許set 值由多個集合成員組成的原因。值中二進制位的任意組合都可以得到,因此,相應的值可由對應于這些二進制位的set 定義中的串組合構成。下面給出一個說明set 列的串形式與數值形式之間關系的樣例;數值以十進制形式和二
進制形式分別給出: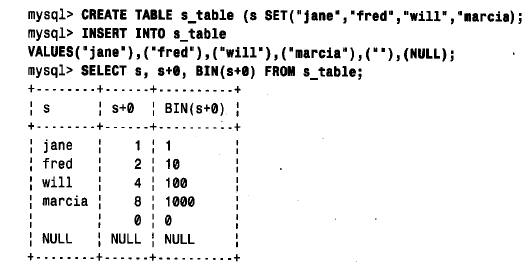
如果給set 列賦予一個含有未作為集合成員列出的子串的值,那么這些子串被刪除,并將包含其余子串的值賦予該列。在賦值給set 列時,子串不需要按定義該列時的順序給出。但是,在以后檢索該值時,各成員將按定義時的順序列出。假如用下面的定義定義一個s e t列來表示家具: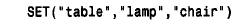
如果給這個列賦予“ c h a i r, couch, table”值,那么,“c o uc h”被放棄,因為它不是集合的成員。其次,以后檢索這個值時,顯示為“ table, chair”。之所以這樣是因為mysql針對所賦的值的每個子串決定各個二進制位并在存儲值時將它們置為1。“c o uc h”不對應二進制位,則忽略。在檢索時,mysql按順序掃描各二進制位,通過數值值構造出串值,它自動地將子串排成定義列時給出的順序。這個舉動還表示,如果在一個值中不止一次地指定某個成員,但在檢索時它也只會出現一次。如果將“ lamp, lamp,lamp”賦予某個set 列,檢索時也只會得出“l a m p”。mysql重新對set 值中的成員進行排序這個事實表示,如果用一個串來搜索值,則必須以正確的順序列出各成員。如果插入“ c h a i r, table”,然后搜索“c h a i r, table”,那么將找不到相應的記錄;必須查找“ table, chair”才能找到。enum 和set 列的排序和索引是根據列值的內部值(數值值)進行的。下面的例子可能會顯示不正確,因為各個值并不是按字母順序存儲的:

null 值排在其他值前(如果是降序,將排在其他值之后)。如果有一個固定的值集,并且希望按特殊的次序進行排序,可利用enum 的排序順序。在創建表時做一個enum 列,并在該列的定義中以所想要的次序給出各枚舉值即可。如果希望enum 按正常的字典順序排序,可使用c o n c at( ) 和排序結果將列轉換成一個非enum 串,如下所示:
4. 串列類型屬性
可對char 和varchar 類型指定b i n a ry 屬性使列值作為二進制串處理(即,在比較和排序操作區分大小寫)。
可對任何串類型指定通用屬性null 和not null。如果兩者都不指定,缺省值為null。但是定義某個串列為not null 并不阻止其取空串。空值不同于遺漏的值,因此,不要錯誤地認為可以通過定義not null 來強制某個串列只包含非空的值。如果要求串值非
空,那么這是一個在應用程序中必須強制實施的約束條件。
還可以對除blob 和text 類型外的所有串列類型用d e fa u lt 屬性指定一個缺省值。如果不指定缺省值, mysql會自動選擇一個。對于可以包含null 的列,其缺省值為null。對于不能包含null 的列,除enum 列外都為空串,在enum 列中,缺省值為第一個枚舉成員(對于set 類型,在相應的列不能包含null 時其缺省值實際上是空集,不過這里空集等價于空串)。
2.2.4 日期和時間列類型
mysql提供了幾種時間值的列類型,它們分別是: date、date time、time、times tamp 和year。表2-9 給出了mysql為定義存儲日期和時間值所提供的這些類型,并給出了每種類型的合法取值范圍。year 類型是在mysql3.22版本中引入的。其他類型在所有mysql版本中都可用。每種時間類型的存儲需求見表2 - 10。每個日期和時間類型都有一個“零”值,在插入該類型的一個非法值時替換成此值,見表2 - 11。這個值也是定義為not null 的日期和時間列的缺省值。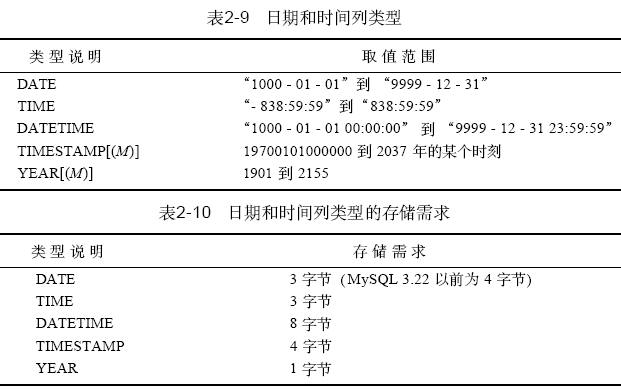
mysql表示日期時根據ansi 規范首先給出年份。例如,1999 年12 月3 日表示為“1999 - 12 - 0 3”。mysql允許在輸入日期
時有某些活動的余地。如能將兩個數字的年份轉換成四位數字的年份,而且在輸入小于10 的月份和日期時不用輸入前面的那位數字。但是必須首先給出年份。平常經常使用的那些格式,如“ 12 / 3 / 9 9”或“3 / 12 / 9 9”,都是不正確的。mysql使用的日期表示規則請參閱“處理日期和時間列”小節。時間值按本地時區返回給服務器; mysql對返回給客戶機的值不作任何時區調整。
1. date、time 和datetime 列類型date、time 和datetime 類型存儲日期、時間以及日期和時間值的組合。其格式為“yyyy - mm - dd”、“h h : m m : s s”和“yyyy - mm - dd hh:mm:ss”。對于datetime 類型,日期和時間部分都需要;如果將date 值賦給datetime 列,mysql會自動地追加一個為“0 0 : 0 0 : 0 0”的時間部分。mysql對datetime 和time 表示的時間在處理上稍有不同。對于datetime ,時間部分表示某天的時間。而time 值表示占用的時間(這也就是為什么其取值范圍如此之大而且允許取負值的原因)。用time 值的最右邊部分表示秒,因此,如果插入一個“短”(不完全)的時間值,如“12 : 3 0”到time 列,則存儲的值為“ 0 0 : 12 : 3 0”,即被認為是“12 分30 秒”。如果愿意,也可用time 列來表示天的時間,但是要記住這個轉換規則以免出問題。為了插入一個“12 小時30 分鐘”的值,必須將其表示為“ 12 : 3 0 : 0 0”。
2. timestamp 列類型
times tamp 列以yyyymmddhhmmss 的格式表示值,其取值范圍從19700101000000到2037 年的某個時間。此取值范圍與unix 的時間相聯系,在unix 的時間中,1970 年的第一天為“零天”,也就是所謂的“新紀元”。因此1970 年的開始決定了t i m e s tamp 取值范圍的低端。其取值范圍的上端對應于unix 時間上的四字節界限,它可以表示到2037年的值。(times tamp 值的上限將會隨著操作系統為擴充unix 的時間值所進行的修改而增加。這是在系統庫一級必須提及的。mysql也將利用這些更改。)times tamp 類型之所以得到這樣的名稱是因為它在創建或修改某個記錄時,有特殊的記錄作用。如果在一個times tamp 列中插入null,則該列值將自動設置為當前的日期和時間。在建立或更新一行但不明確給times tamp 列賦值時也會自動設置該列的值為當前的日期和時間。但是,僅行中的第一個times tamp 列按此方式處理,即使是行中第一個timestamp列,也可以通過插入一個明確的日期和時間值到該列(而不是null)使該處理失效。
times tamp 列的定義可包含對最大顯示寬度m 的說明。表2 - 12給出了所允許的m 值的顯示格式。如果times tamp 定義中省略了m 或者其值為0或大于14,則該列按times tamp(14) 處理。取值范圍從1到13的m 奇數值作為下一個更大的偶數值處理。t i m e s tamp 列的顯示寬度與存儲大小或存儲在內部的值無關。times tamp 值總是以4 字節存放并按14 位精度進行計算,與顯示寬度無關。為了明白這一點,按如下定義一個表,然后插入一些行,進行檢索: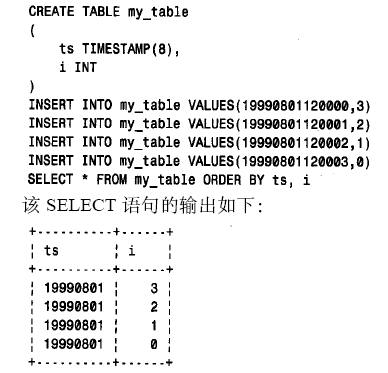
從表面上看,出現的行排序有誤,第一列中的值全都相同,所以似乎排序是根據第二列中的值進行的。這個表面反常的結果是由于事實上, mysql是根據插入t i m e s tamp 列的全部14 位值進行排序的。mysql沒有可在記錄建立時設置為當前日期和時間、并從此以后保持不變的列類型。如果要實現這一點,可用兩種方法來完成:
■ 使用t i m e s tamp 列。在最初建立一個記錄時,設置該列為null,將其初始化為當前日期和時間: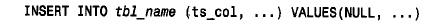
在以后無論何時更改此記錄,都要明確地設置此列為其原有的值。賦予一個明確的值使時間戳機制失效,因為它阻止了該列的值自動更新: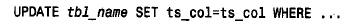
■ 使用datetime 列。在建立記錄時,將該列的值初始化為now( ):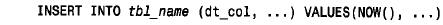
無論以后何時更新此記錄,都不能動該列:updatetbl_name set /* angthing but dt_col here */ where ...如果想利用t i m e s tamp 列既保存建立的時間值又保存最后修改的時間值,那么可用一個t i m e s tamp 列來保存修改時間值,用另一個t i m e s tamp 列保存建立時間值。要保證保存修改時間值的列為第一個t i m e s ta m p,從而在記錄建立或更改時自動對其進行設置。使保存建立時間值的列為第二個t i m e s ta m p,并在建立新記錄時將其初始化為now( )。這樣第二個t i m e s tamp 的值將反映記錄建立時間,而且以后將不再更改。
3. year 列類型
year 是一個用來有效地表示年份值的1個字節的列類型。其取值范圍為從1901到2 15 5。在想保存日期信息但又只需要日期的年份時可使用year 類型,如出生年份、政府機關選舉年份等等。在不需要完全的日期值時, year 比其他日期類型在空間利用上更為有效。
year 列的定義可包括顯示寬度m 的說明,顯示寬度應該為4 或2。如果year 定義中省略了m,其缺省值為4。tinyint 與year 具有相同的存儲大小(一個字節),但取值范圍不同。要使用一個整數類型且覆蓋與year 相同的取值范圍,可能需要smallint 類型,此類型要占兩倍的空間。在所要表示的年份取值范圍與year 類型的取值范圍相同的情況下, year 的空間利用率比smallint 更為有效。year 相對整數列的另一個優點是mysql將會利用mysql的年份推測規則把2 位值轉換為4 位值。例如,97 與14 將轉換為1997 和2 0 14。但要認識到,插入數值00 將得到0000 而不是2 0 0 0。如果希望零值轉換為2 0 0 0,必須指定其為串“0 0”。
4. 日期和時間列類型的屬性沒有專門針對日期和時間列類型的屬性。通用屬性null 和not null 可用于任意日期和時間類型。如果null 和not null 兩者都不指定,則缺省值為null。也可以用defa ult 屬性指定一個缺省值。如果不指定缺省值,將自動選擇一個缺
省值。含有null 的列的缺省值為null 。否則,缺省值為該類型的“零”值。
5. 處理日期和時間列mysql可以理解各種格式的日期和時間值。date 值可按后面的任何一種格式指定,其中包括串和數值形式。表2 - 13為每種日期和時間類型所允許的格式。兩位數字的年度值的格式用“歧義年份值的解釋”中所描述的規則來解釋。對于有分隔
符的串格式,不一定非要用日期的“ -”符號和時間的“ :”符號來分隔,任何標點符號都可用作分隔符,因為值的解釋取決于上下文,而不是取決于分隔符。例如,雖然時間一般是用分隔符“:”指定的,但mysql并不會在一個需要日期的上下文中將含有“ :”號的值理解成時間。此外,對于有分隔符的串格式,不需要為小于10 的月、日、小時、分鐘或秒值指定兩個數值。下列值是完全等同的: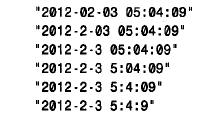
請注意,有前導零的值根據它們被指定為串或數有不同的解釋。串“ 0 0 12 3 1”將視為一個六位數字的值并解釋為date 的“2 0 0 0 - 12 - 3 1”和datetime 的“2000-12-3100:00:00”。而數0 0 12 3 1被認為12 3 1,這樣的解釋就有問題了。這種情形最好使用串值,或者如果要使用數值的話,應該用完全限定的值(即, date 用2 0 0 0 12 3 1,datetime 用2 0 0 0 12 3 10 0 0 0)。通常,在date、datetime 和t i m e s tamp 類型之間可以自由地賦值,但是應該記住以下一些限制:
■ 如果將datetime 或t i m e s tamp 值賦給date,則時間部分被刪除。
■ 如果將date 值賦給datetime 或t i m e s ta m p,結果值的時間部分被設置為零。
■ 各種類型具有不同的取值范圍。t i m e s tamp 的取值范圍更受限制( 1970 到2 0 3 7),因此,比方說,不能將1970 年以前的datetime 值賦給t i m e s tamp 并得到合理的結果。也不能將2037 以后的值賦給times tamp。mysql提供了許多處理日期和時間值的函數。要了解更詳細的信息請參閱附錄c。
6. 歧義年份值的理解
對于所有包括年份部分的日期和時間類型( date、date time、time stamp、year),mysql將兩位數字的年份轉換為四位數字的年份。這個轉換根據下列規則進行(在mysql4.0 中,這些規則稍有改動,其中69 將轉換為1969 而不是2069。這是根據x/open unix 標準規定的規則作出的改動):
■ 00 到69 的年份值轉換為2000 到2069。
■ 70 到99 的年份值轉換為1970 到1999。
通過將不同的兩位數字值賦給一個year 列然后進行檢索,可很容易地看到這些規則的效果。下面是檢索程序: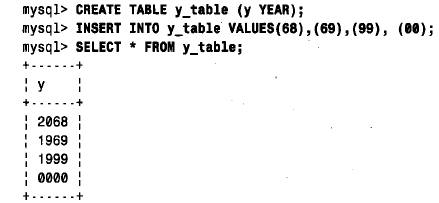
請注意,00 轉換為0000 而不是2 0 0 0。這是因為0 是year 類型的一個完全合法的值;如果插入一個數值,得到的就是這個結果。要得到2 0 0 0,應該插入串“ 0”或“0 0”。可通過c o n c at( ) 插入year 值來保證mysql得到一個串而不是數。c o n c at( ) 函數不管其參數是串或數值,都返回一個串結果。請記住,將兩位數字的年份值轉換為四位數字的年份值的規則只產生一種結果。在未給
定世紀的情況下,mysql沒有辦法肯定兩位數字的年份的含義。如果mysql的轉換規則不能得出您所希望的值,解決的方法很簡單:即用四位數字輸入年份值。mysql有千年蟲問題嗎?mysql自身是沒有2000 年問題的,因為它在內部是按四位數年份存儲日期值的,并且由用戶負責提供恰當的日期值。兩位數字年份解釋的實際問題不是mysql帶來的,而是由于有的人想省事,輸入歧義數據所引起的問題。如果您愿意冒險,可以繼續這樣做。在您冒險的時候,mysql的猜測規則是可以使用的。但要意識到,很多時候您確實需要輸入四位數字的年份。例如, p r e s i d e n t表列出了1700 年以來的美國總統,所以在此表中錄入出生與死亡日期需要四位的年份值。這些列中的年份值跨了好幾個世紀,因此,讓mysql從兩位數字的年份去猜測是哪個世紀是不可能的。
新聞熱點






疑難解答













