3.8 解決方案隨筆
本節內容相當雜;介紹了怎樣編寫解決各種問題的查詢。多數內容是在郵件清單上看到的解決問題的方案(謝謝清單上的那些朋友,他們為解決方案作了很多工作)。
3.8.1將子選擇編寫為連接
mysql自3.24版本以來才具有子選擇功能。這項功能的缺少是mysql中一件常常令人惋惜的事,但有一件事很多人似乎沒有認識到,那就是用子選擇編寫的查詢通常可以用連接來編寫。實事上,即使mysql具有了子查詢,檢查用子選擇編寫的查詢也是一件苦差事;用連接而不是用子選擇來編寫會更為有效。
1. 重新編寫選擇匹配值的子選擇
下面是一個包含一個子選擇查詢的樣例,它從score 表中選擇所有測試的學分(即,忽略測驗的學分):
可通過將其轉換為一個簡單的連接,不用子選擇也可以編寫出相同的查詢,如下所示:
下面的例子為選擇女學生的學分:
可將其轉換為連接,如下所示:
這里是一個模式,子選擇查詢如下形式:
這樣的查詢可轉換為如下形式的連接: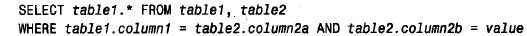
2. 重新編寫選擇非匹配值的子選擇查詢
另一種常用的子選擇查詢是查找一個表中有的而另一個表中沒有的值。正如以前所看到的那樣,“那些未給出的值”這一類的問題是left join 可能有用的一個線索。下面的查詢包含一個子選擇(它尋找那些全勤的學生):

3.8.2 檢查表中未給出的值
我們已經在3 . 6節“檢索記錄”中看到,在要想知道一個表中哪些值不出現在另一表中時,可對兩個表使用left join 并查找那些從第二個表中選中null 的行。并用下列兩個表舉例:
現在讓我們來考慮一種更為困難的情況,“缺了哪些值”。對于第1章中提到的學分保存方案中,有一個列出學生的student 表,一個列出已經出現過的學分事件的event 表,以及列出每個學生的每次學分事件學分的一個score 表。但是,如果一個學生在某個測試或測驗的同一天病了,那么score 表中將不會有這個學生的該事件的學分,因此,要進行測驗或測試的補考。我們怎樣查找這些缺少了的記錄,以便能保證讓這些學生進行補考?問題是要對所有的學分事件確定哪些學生沒有某個學分事件的學分。換個說法,就是我們希望知道學生和事件的哪些組合不出現在學分表中。這就是我們希望left join 所做的事。這個連接不像前例中那樣簡單,因為我們不僅僅要查找不出現在單列中的值;還需要查找兩列的組合。
我們想要的這種組合是所有學生/事件的組合,它們由student 表與event 表的叉積產生:
from student, event
然后我們取出此連接的結果,與score 表執行一個left join 語句找出匹配者:
from student, event
left join score on student.student_id = score.student.id
and event.event_id = score.event_id
請注意,on 子句使得score 表中的行根據不同表中的匹配者進行連接。這是解決本問題的關鍵。left join 強制為由student 和event 表的叉連接生成的每行產生一個行,即使沒有相應的score 表記錄也是這樣。這些缺少的學分記錄的結果行可通過一個事實來識別,就是來自score 表的列將全是null 的。我們可在where 子句中選出這些記錄。來自score 表的任何列都是這樣,但因為我們查找的是缺少的學分,測試score 列從概念上可能最為清晰:
where score.score is null
可利用order by 子句對結果進行排序。兩種最合理的排序分別是按學生和按事件進行,我們選擇第一種:
order by student.student_id, event.event_id
現在需要做的就是命名我們希望在輸出結果中看到的列。最終的查詢如下:
select
student.name, student.student_id,
event.date, event,event_id, event.type
from
student,event
left join score on student.student_id = score.student_id
and event.event_id = score.event_id
where
score.score is null
order by
student.student_id, event.event_id
運行此查詢得出如下結果: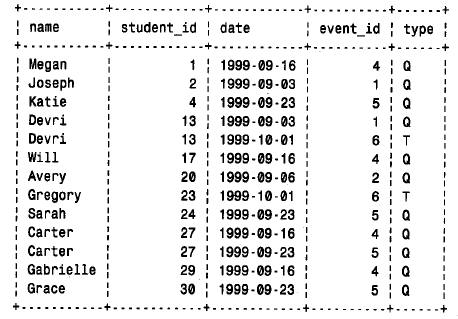
這里有一個問題要引起注意。此輸出列出了學生的id 和事件的id。student_id 列出現在student 和score 表中,因此,開始您可能會認為選擇列表可以給出student.student_id 或score . student _ id。但實際不是這樣,因為能夠找到感興趣記錄的基礎是所有學分表字段返回null。選擇score.student_id 將只在輸出中產生null 值的列。類似的推理可應用到event_id 列,它也出現在event 和score 表中。
3.8.3 執行union 操作
如果想通過從具有相同結構的多個表中建立一個結果集,可在某些數據庫系統中使用某種union 語句來實現。mysql沒有union(至少直到3 . 2 4版還沒有),但有許多辦法來解決這個問題,下面是兩種可行的方案:
■ 執行多個select 查詢,每個表執行一個。如果不關心所選出行的次序,這樣做就行了。
■ 將每個表中的行選入一個臨時存儲表,然后選擇該表的內容。這樣可對行按所需的次序進行排序。在mysql3.23版及以后的版本中,可通過允許服務器創建存儲表來解決這個問題。而且,還可以使該表為臨時表,以便在您與服務器的會話結束時,自動刪除該表。
在下面的代碼中,我們明確地刪除該表使服務器釋放與其有關的資源。如果客戶機會話將繼續執行進一步的查詢,這樣做很有好處。為了取到更好的性能,還可以利用heap(在內存中)表。
對于3 . 2 3版本,除了必須自己明確定義hold_tbl 表中的列外,其想法是類似的,而且結尾處的drop table 是強制性的,用來防止在以下客戶機會話生命周期之后繼續存在: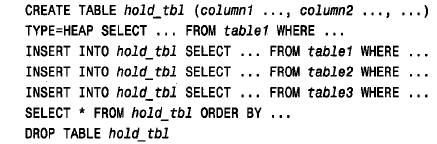
3.8.4 增加序列號列
如果用alter table 增加auto_increment 列,則該列用序列號自動地填充。下面這組mysql會話中的語句示出了怎樣創建一個表,在其中存放數據,然后增加一個auto_increment 列: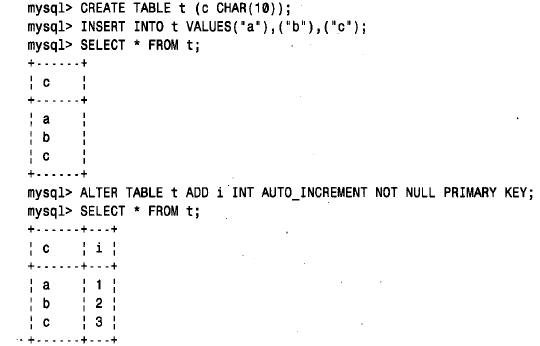
3.8.5 對某個已有的列進行排序
如果有一個數值列,可對其按如下進行排序(或對其重排序,如果已對其排過序,但刪除了行并且想要對值重新排序使其連續):
alter table t modify i int null
update t set i = null
alter table t modify i int unsignedauto_increment not null primary key
但是有一種更容易的方法,那就是刪除該列,然后再作為一個auto_increment 列追加它。alter table 允許指定多個活動,因此,上述工作可在單個語句中完成:
alter table t
drop i,
add i int unsignedauto_increment not null primary key
3.8.6 非正常次序的串
假如有一個表示體育機構人員的表,如橄欖球隊,如果按人員職位進行排序,以便以特殊的順序表示它,如:教練、教練助理、四分衛、流動后衛、接球員、巡邏員等。可將列定義為enum 并按希望出現的順序定義枚舉元素。對該列的排序將會以所指定的順序自動進行。
3.8.7 建立計數表
在第2章的“使用序列”小節中,我們介紹了怎樣利用l a s t _ insert_id(expr) 生成一個序列。那個例子說明了怎樣利用單列的表進行計數。那樣做對于只需要單個計數器的情形能夠滿足需要,但是,如果需要幾個計數器,該方法將會引起不必要的表重復。假如有一個web 站點并且想要在幾個頁面上放置“此頁面已經被訪問nnn 次”這樣的計數器。那么為每個具有一個計數器的頁面建立一個單獨的表就有些多余了。避免創建多個計數器表的一種方法是建立一個兩列的表。其中一列存放計數值;另一列存放計數器名。這時仍然可以使用last _ insert_id( ) 函數,但可用計數器名來決定用哪一行。這個表如下所示:
create table counter
(
count int unsigned,
name varchar(255) not null primary key
)
其中計數器名為一個串,從而可以調用任何想要的計數器,我們將其定義為primary key 以免名稱重復。這里假定使用這個表的應用程序知道他們將使用的名稱。對于前面所說的web 計數器,可通過利用文件樹中每個頁面的路徑名作為其計數器名的方法,保證計數器名的唯一性。例如,要為站點的主頁建立一個新計數器,可執行下列語句:
insert into counter(name) values("index.html")
它用零值初始化稱為“ index.html”的計數器。為了生成序列中的下一個值,增加表中相應行的計數值,然后用last _ insert_id( ) 檢索它:
update counter
set count = last_insert_id(count+1)
where name = "index.html"
select last_insert_id()
另一種方法是不用last _ insert_id( ) 增加計數器的值,如下所示:
update counter set count = count+1where name = "index.html"
select count from counter where name = "index.html"
然而,如果另一個客戶在您發布update語句與select 語句之間增加了該計數器的值,則這種方法工作不正常。不過可在此兩條語句的前后分別放置lock tables 和u n l o c ktables,在您使用該計數器時阻塞其他客戶,以解決上述問題。但用l a s t _ insert_id( )方法完成同樣的工作更為容易一些。因為它的值是客戶專用的,您總能得到自己插入的值,而不是其他客戶插入的值,而且不必阻塞其他客戶使代碼復雜化。
3.8.8 檢查表是否存在
在應用程序內部知道一個表是否存在有時很有用。為了做到這一點,可使用下列任一條語句:
select count(*) from tb1_name
select * from tb1_name where 1=0
如果指定的表存在,則上述兩條語句都將執行成功,如果不存在,則都失敗。它們是這種測試的很好的查詢。它們執行速度快,所以不會費太多的時間。這種方法最適合您自己編寫的應用程序,因為您可以測試查詢的成功與失敗并采取相應的措施。但在從mysql運行的批量腳本中不特別有用,因為發生錯誤時除了終止運行外不可能做任何事(或者可以忽略相應的錯誤,但是顯然無法再運行該查詢了)。
新聞熱點






疑難解答













